
들어가며
일반적인 메인 메모리는 DRAM이라고 부르며 캐시 메모리는 SRAM이라고 부른다. SRAM에 대해서 알아보자.
SRAM의 속도

SRAM은 1사이클에 1개의 데이터를 가져올 수 있을만큼 빠르다 하지만 DRAM은 그에 비해 수십배 느리다. 대신에 SRAM은 GB당 수백만원일 정도로 비싸다. 그래서 우리는 싼 DRAM과 비싼 SRAM을 섞어서 사용한다. 그러면 어떻게 하면은 이 둘을 이용해서 효율적으로 사용할 수 있을까?
Locality
프로그램은 주기적으로 그들이 원하는 데이터가 있는 특정 장소에 접근한다. 이 때 우리는 2가지 전략을 볼 수 있다.
- Temporal Locality: 최근에 사용된 데이터는 다시 사용될 가능성이 높다는 뜻
- Spatial Locality: 특정 address에 있는 데이터가 사용되면 그 주위에 있는 데이터가 그 다음에사용될 가능성이 높다는 뜻
1번을 대표하는 예제가 for-loop이다. loop에서는 index라는 변수가 자주 사용된다.
2번을 대표하는 예제는 array이다.
그래서 우리는 최근에 접근한 프로그램 및 데이터를 DISK에서 DRAM으로 가져오고, 가장 최근에 사용된 block data를 DRAM에서 SRAM으로 가져온다. 이렇게 데이터를 프로세서와 가까운 위치로 가져오면은 좀 더 빠르게 task를 수행할 수 있다는 장점이 있다.
Cache
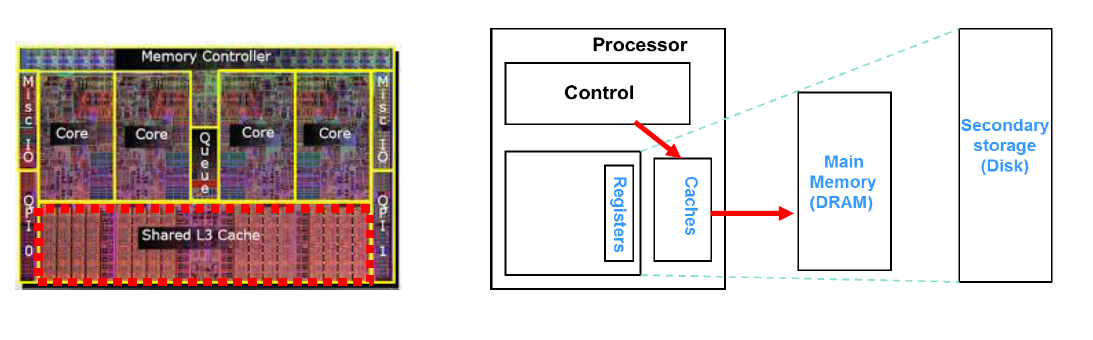
L1, L2 캐시는 위 그림처럼 각 프로세서 안에 존재한다.
Block
Block은 데이터를 DRAM에서 SRAM으로 가져올 때 사용되는 데이터의 단위이다. 대부분 Multiple Words(4의 배수 bytes)이다.
hit/miss
Cache hit은 메모리에 있는 데이터를 접근하기 전에 해당 데이터가 캐시에 존재하는 경우이고 Miss 그 반대이다.
전체의 access에서 hit가 발생할 확률을 hit rate 라고 하며, 데이터를 캐시에서 읽어오는 시간을 hit time이라고 한다.
마찬가지로 miss가 발생할 확률을 miss rate 라고 하며, 캐시 이후에 메모리에 접근해서 데이터를 가져오고, 캐시에 데이터를 저장하는 시간을 miss penalty라고 한다.
Store
자 그럼 다음에는 어떻게 하면 캐시를 저장할 수 있는 지에 대해서 알아보자. 먼저 block size = 1word = 4bytes라고 가정한다.
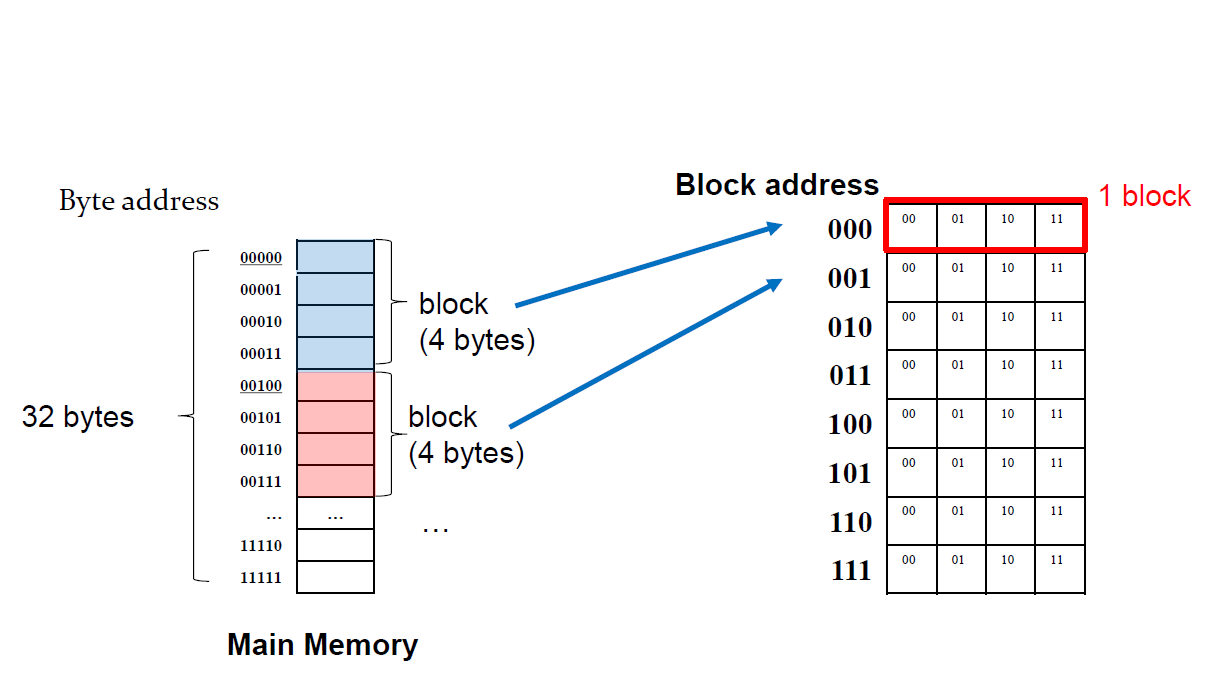
위 그림처럼 4개의 cell이 1개의 block으로 묶여서 저장된다. 파란색 블ㄹ록을 보면은 MSB 3개의 비트가 같은 것을 확인할 수 있다. 반대로 LSB 2개 비트는 다르다. 이는 4개가 하나로 묶였기 때문이다. 그래서 2 bit LSR 연산한 값을 block address로 삼는다.
example
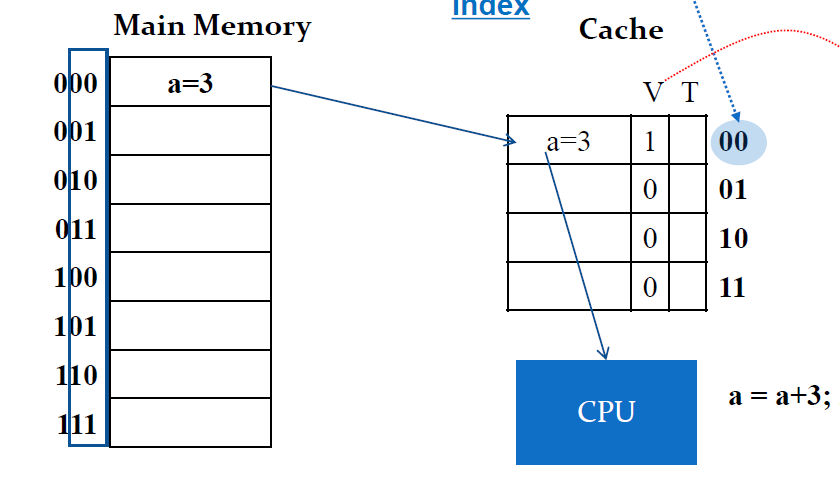
000번지에 있는 a=3데이터를 호출하면은 modular 연산을 한 나머지 00이 한 블록 안에서의 해당 셀의 index가 된다. 그리고 캐시에는 V비트와 T비트가 있는데 V비트는 Valid의 약자로 cell에 데이터가 있는지 없는지를 나타낸다.
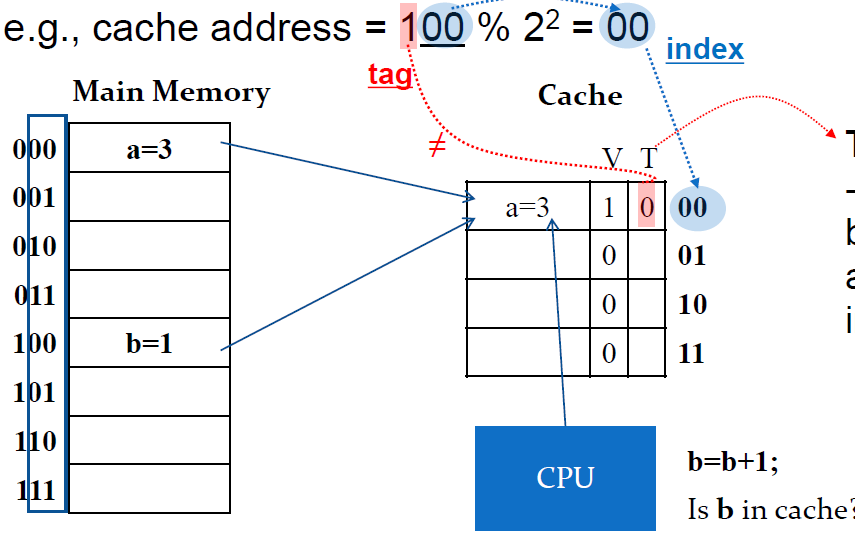
그런데 여기서 100번지에 있는 b=1 데이터를 캐시에 저장하고 싶다면은 동일하게 block address가 0번지인 곳에 작성하게 된다. 이떄 000과 100을 구분하기 위해서 T(Tag)비트가 사용된다. T비트는 캐시의 데이터가 어느 메모리에서 왔는지를 나타낸다.
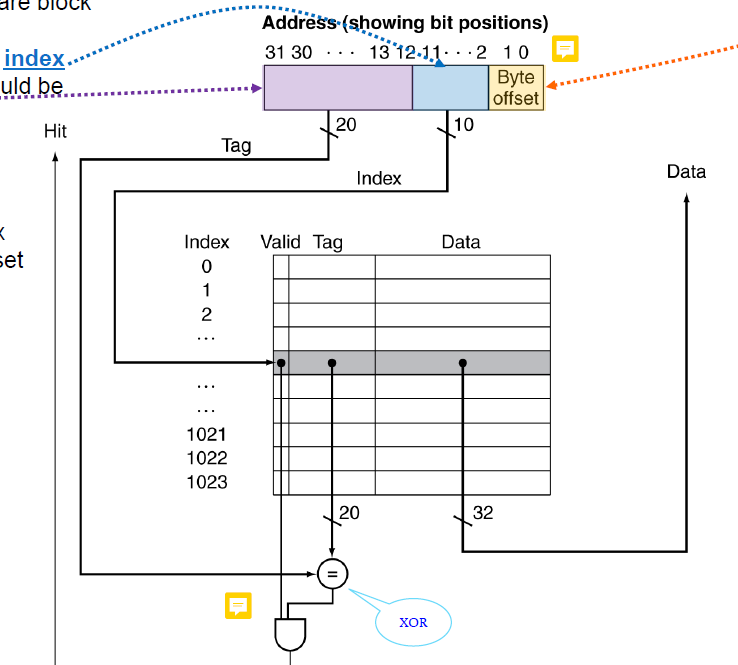
최종적으로 위 회로를 볼 수 있다. 아래의 AND게이트를 통해서 우리가 특정 메모리에 접근하고 싶을 때,
- 그 메모리 주소를 modular연산을 해서 block address를 구하고
- 캐시의 해당 주소의 V비트를 확인하고
- 캐시의 T와 메모리주소를 비교한다.
위 3단계를 모두 만족하면 cache hit가 된다.
Larger Block Size
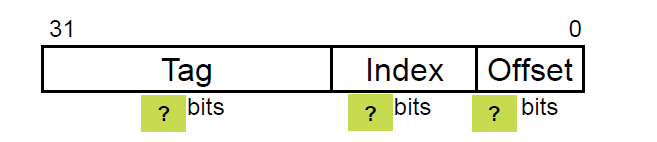
만약에 캐시의 구조가 64개의 블록을 사용하고 한 블록당 16byte를 저장한다고 하면 위 빈칸을 어떻게 채울 수 있을까?
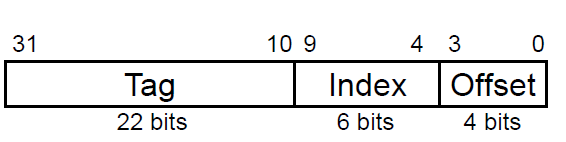
일단 16byte를 저장해야하므로 어떤 총 2^4개의 cell이 있는 것이므로 해당 셀들을 구분하기 위해서 Offset은 4비트여야 한다.
그리고 블록은 총 64(=2^6)개이므로 index도 6비트가 필요하고 나머지는 tag비트가 될것이다.
Block Size Consideration
블록의 사이즈가 크면 좋을까 나쁠까?
먼저 블록의 사이즈가 커지면 한 번 데이터를 가져올 때 주변의 더 많은 데이터를 가져오기에(spatial locality) miss rate가 줄어든다. 하지만 동시에 전체 block의 갯수가 줄어든다. 그렇기 때문에 miss rate가 증가한다.
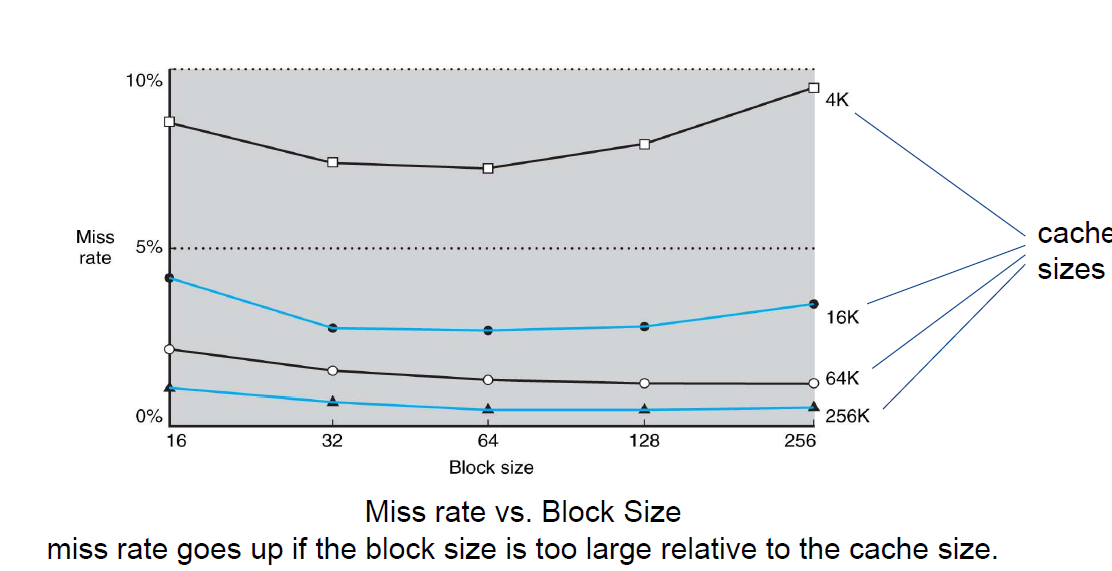
위 그림처럼 특정 구간까지는 block size를 증가하면 miss rate가 줄어들지만 특정 구간 이후부터는 miss rate가 증가한다.
handle cache miss
cache hit이 되면은 아주 빠르게 데이터를 읽어올 수 있다. 하지만 miss가 일어나면 다음 계층으로 넘어가서 데이터를 가져와야한다. 그러면 파이프라이닝에서 MEM부분의 시간이 길어지게 된다.
handle cache Write
캐시에 데이터를 적으면은 그 데이터를 메모리에도 적어주어야한다. 그렇지 않으면은 중간에 캐시에 적은 데이터가 다른 데이터로 덮어씌워졌을 때 데이터 불일치가 발생한다. 하지만 매 쓰기마다 메모리에 데이터를 다 직접 써버리면

위처럼 성능이 떨어진다.
이를 해결하기 위해 2가지 솔루션이 있다.
- Write buffer: 캐시에 데이터를 쓰면은 자동으로 버퍼에 쓴 데이터가 저장되면서 background에서 ram에 데이터를 적는다.
- Write back: 데이터를 메모리에 쓰는 시점을 최대한 마지막으로 미룬다. 그리고 캐시에 새로운 데이터를 로드해야하는 상황처럼 메모리에 write가 불가피한 그 시점에 쓴다. 이 때는 dirty bit(modified bit)를 추가해서 해당 데이터가 수정이 되었는지 아닌지를 표기한다.
Bandwith
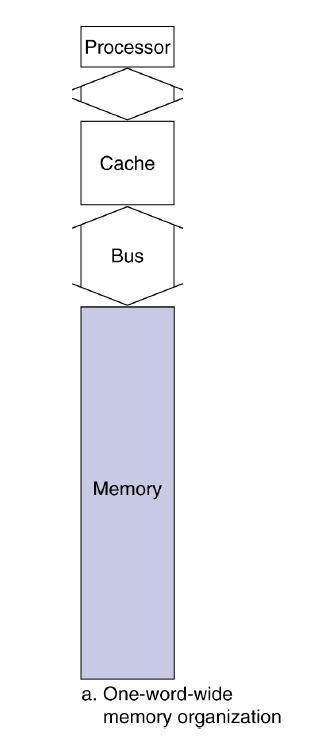
우리가 4byte를 메모리에서 읽는 상황을 가정해보자. 위 그림에서는 한 사이클에 1byte의 데이터만 움직일 수 있다.

메모리 read를 하는 작업은 왕복에 2사이클, 데이터를 찾는데 15사이클이 소요된다. 그러면 4byte를 가져오는데에는
명령을 보내는데 1사이클, 찾는데 4 15 사이클, 보내는데 4 1 사이클이 소요된다.
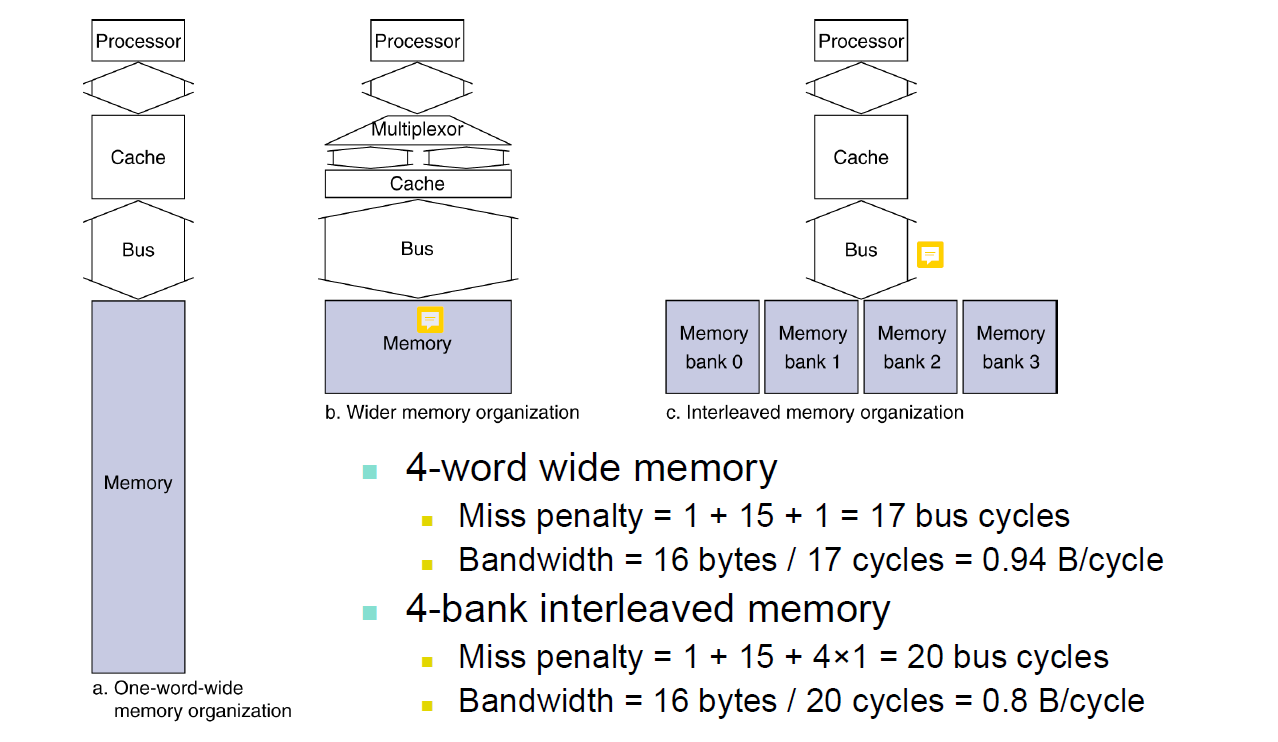
하지만 위 그림처럼 한 번에 많은 데이터를 보낼 수 있게 하면은 필요한 사이클을 줄일 수 있다.
block size
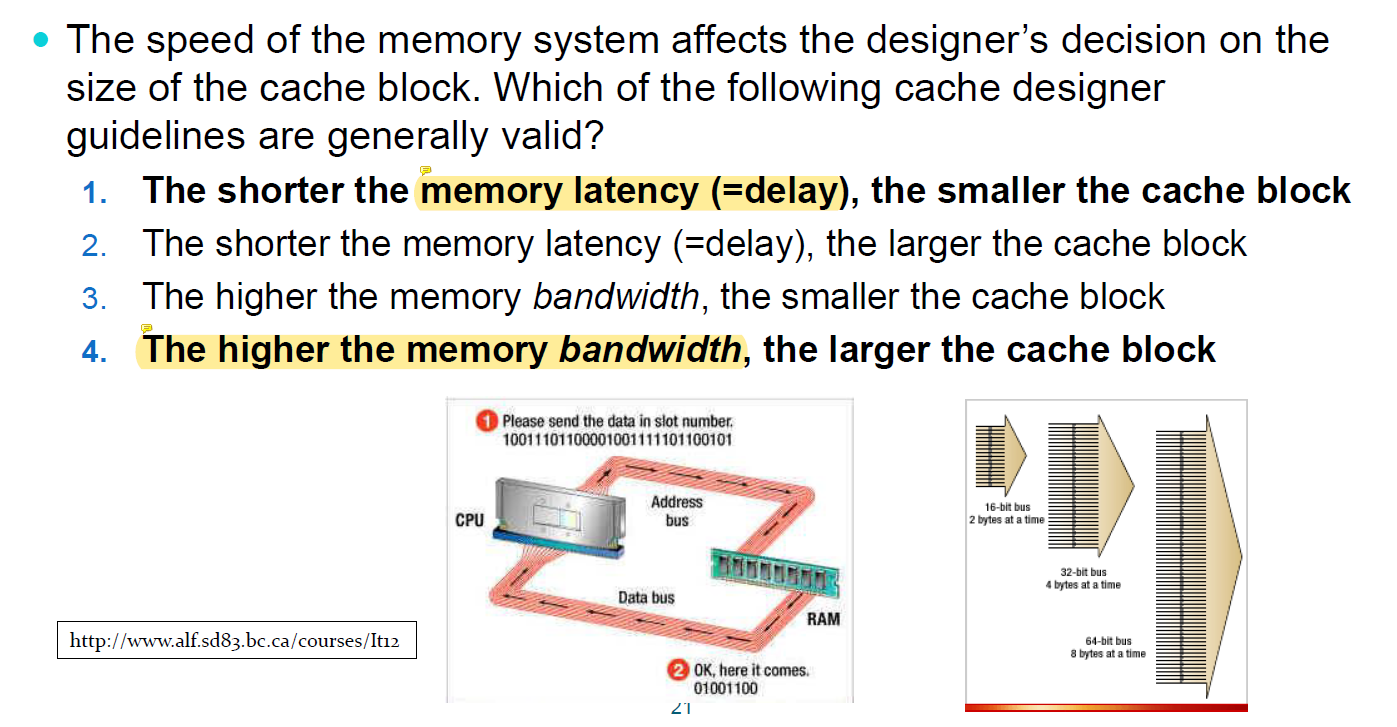
그래서 결론적으로 block size는 어떻게 결정하면 좋을까?
- memory latency가 적은 경우 : 메모리를 빨리 읽고 쓸 수 있는 경우에는 block size를 작게하는 것이 좋다.
- memory bandwith가 큰 경우: 한 번에 메모리를 많이 읽을 수 있는 경우에는 그 이점을 살려서 한 번에 많은 데이터를 읽어오는 것이 좋다.
