
32비트 표현

우리가 비트를 적을 때 일반적으로는 위 그림처럼 수평 방향으로 적게 되고 맨 오른쪽이 제일 작은 비트, 맨 왼쪽이 제일 큰 비트로 적는 것지만 그렇지 않을 경우를 대비해서 가장 작은 비트를 우리는 LSB(Least Significant Bit)라고 부르고 가장 큰 비트를 MSB(Most Significant Bit)라고 부른다.
Signed vs Unsigned
signed는 양수와 음수를 둘 다 표현하는 것을 의미하고 Unsigned는 양수만 표현하는 것을 뜻한다. 2진수는
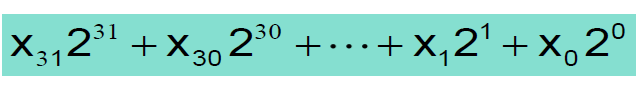
위처럼 계산된다.
Signed에서 우리가 음수를 표현하기 위해서는 2의 보수를 사용한다. 2의 보수를 계산하는 방법은 매우 쉽다
not 연산을 하고 1을 더한다.
위 연산을 하면은 2의 보수를 구할 수 있고 그것이 음수로 바꾸는 방법이다.
예를 들어 4비트 표현식에서 1은 0001 이다. 여기서 2의 보수를 구하면 1111이다. 그래서 -1은 2진수로 1111인 것이다.
여기서 우리가 알 수 있는 사실은 Signed에서 MSB가 바로 부호를 나타내는 부호 비트(sign bit)라는 것이다. 그리고 우리는 2의 보수를 이용해서 뺄셈기 없이 뺄셈 연산을 할 수 있다.
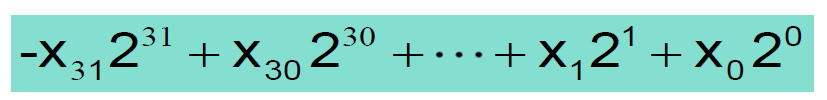
32비트 표현식에서 2진수를 10진수로 변환하는 공식이다.
폰 노이만 구조

폰 노이만 구조는 일반적인 목적을 가진 컴퓨터의 아키텍처이다. 오늘날의 대부분의 컴퓨터는 폰노이만 구조를 따르고 있다.
폰 노이만 구조에서 컴퓨터는 5가지로 구성되어 있다.
- Control unit
- Data path
- I/O ,2개
- Memory
1번과 2번을 합쳐서 우리는 CPU라고 부르며 CPU는 명령어를 읽어들이고 번역하고 명령어를 실행하는 등의 역할을 한다.
좀더 자세히 살펴보면, 2번에 해당하는 DataPath는 산술 논리 장치(ALU)나 레지스터, 버스와 같은 기능을 모아둔 단위라고 볼 수 있다. 1번에 해당하는 Control unit은 직접 연산을 수행하는 것이 아니라 명령어를 읽어서 해독하고 명령을 지시하는 역할을 한다.
PC(Program Counter)
PC는 명령어의 주소를 저장하는 곳이다.
ISA
자 그럼 명령어란 무엇일까? 명령어는 컴퓨터 세계에서 CPU에게 명령을 내리는 단위이다. Instruction Set은 모든 단어의 집합체라고 볼 수 있다. 우리가 컴퓨터에게 내리는 명령은 명령 + 데이터 라고 볼 수 있는데 명령에 해당하는 모든 명령어를 모아둔 것을 두고 Instruction Set이라고 한다.
서로 다른 컴퓨터는 서로 다른 명령어 집합을 가지고 있을 수 있다. 예를 들어 ARMv8, MIPS, x86 등등 말이다. 하지만 많은 기능과 명령어들을 대게 비슷하다.
ISA(Instruction Set Architecture)는 CPU를 정의한다. 그리고 S/W와 H/W사이의 게약을 의미한다. 무슨 말이냐면, S/W에서 H/W를 바라보는 인터페이스가 된다는 것이다.
ISA에는 두 가지의 종류가 있다. CICS(Complex Instruction Set Computer과 RISC(Reduced Instruction Set Computer 두 개 말이다.
CISC는 이름에서 알 수 있듯이 많고 복잡한 명령어를 가지고 있는 컴퓨터를 의미한다. 그 명령어의 수가 1000개를 넘기며 그렇기에 더 많은 복잡한 기능들을 구현할 수 있으며 과거의 코드들도 수행할 수 있다는 장점이 있지만 많은 에너지를 필요로 한다는 단점도 존재한다.
RISC는 CISC에 비해서 더 적은 명령어들을 가지고 있으며 더 효율적으로 에너지를 사용한다. RISC의 디자인 원칙은 작고, 일반적으로 만들어서 빠르게 하자는 것이다. RISC 아키텍처는 모바일이나 임베디드 장치에서도 많이 사용이 된다.
하드웨어 연산
컴퓨터는 기본적으로 산술연산이 가능해야 한다.
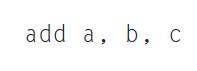
위 연산은 LEGv8 어셈블리 언어로 변수 b, c를 더해서 a에 넣으라는 연산이다.
LEGv8 산술 명령어는 반드시 한 종류의 연산만 지시하고 변수 세 개를 갖는다.
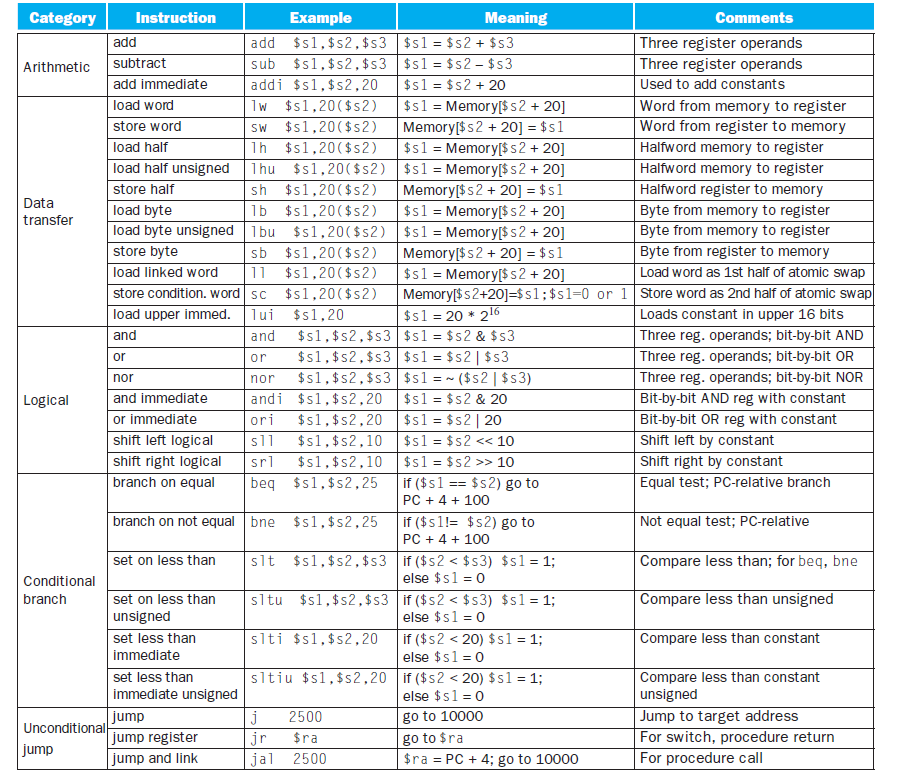
위는 LEGv8 어셈블리어의 명령어 표이다.
어셈블리어는 고급 언어와는 다르게 한 줄에는 한 개의 명령어만 사용할 수 있다. 덧셈 연산에는 연산에 더해질 값 2개와 결과값 1개 총 3개이므로 피연산자는 3개이다. 이렇게 모든 명령어가 피연산자를 반드시 3개씩 갖도록 하는 것이 하드웨어를 단순하게 하자는 원칙에 부합한다.
이를 통해서
설계 원칙1: 간단하기 위해서는 규칙적인 것이 좋다.
라는 설계 원칙을 엿볼 수 있다.
예제

위의 연산을 하는 c 코드를 컴파일해보자.
g + h를 임시 변수 t0에 넣고 i + j 값을 t1에 넣고 뺀 값을 f에 넣는다.
JAVA는 이식성을 높이기 위해 소프트웨어 인터프리터를 사용하도록 설계되었다. 인터프리터의 명령어 집합을 java bytecode라 한다. 오늘 날의 java는 java bytecode를 기계어로 컴파일한다. 그래서 c보다 훨씬 나중에 컴파일이 일어나서 java 컴파일러를 JIT 컴파일러(just in time)라고 부르기도 한다.
ARMv7

위 사진은 ARMv7의 프로그래밍 모델에 대한 설명이다.
맨 왼쪽에 초록색은 32개의 레지스터이고 중앙에 하늘색은 메인 메모리를 의미하고 마지막 노란색 블록은 어떻게 CPU가 레지스터, memory를 가지고 명령어들을 수행하는 지에 대한 수도 코드이다.
먼저 PC에는 수행해야할 명령어의 주소가 있다. 그래서 메인 메모리에서 수행해야할 명령어를 가져온 다음에 PC의 값을 4만큼 증가한다. 4만큼 증가한다는 것은 4bytes만큼 증가한다는 것인데 왜 4bytes인가 하면, 32비트 컴퓨터 체제에서는 하나의 명령어의 길이기 32bit이기 때문이다. 그 다음에 fetch한 명령어를 수행한다. 이 과정을 반복하는 것이 바로 명령어들을 수행하는 것이다.
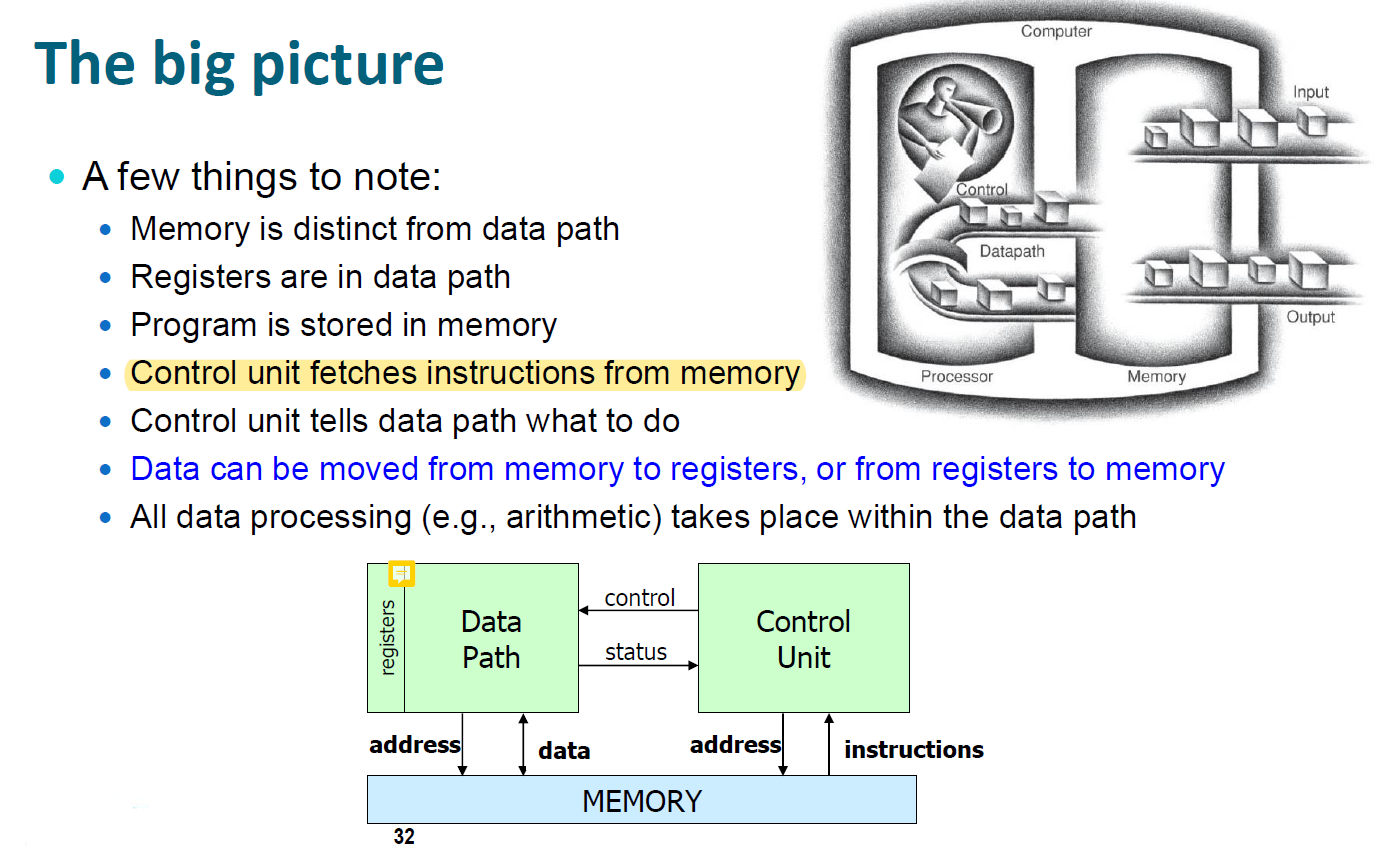
큰 그림은 위와 같다. 해석을 해보자면
- Memory는 DataPath와 구분된다.
- 레지스터는 DataPath에 포함된다.
- 프로그램(명령어들의 모음)은 메인 메모리에 존쟇나다.
- Control unit은 명령어를 가져온다.
- 그래서 DataPath에게 뭘 해야할 지 알려준다.
- 데이터는 메인메모리에서 레지스터로, 또 반대로도 이동한다.
- 모든 데이터 연산 및 처리는 DataPath 안에서 수행된다.
Register Operands
모든 산술 연산은 레지스터를 사용한다. 우리가 앞으로 배울 LEGv8은 64비트의 레지스터를 32개 가지고 있다. 우리는 64-bit의 데이터를 double word라고 하며 32-bit의 데이터는 word라고 한다.
LEGv8에서 사용하는 레지스터들에 대해서 간단하게 알아보자면

먼저 0번부터 7번까지는 프로시저(쉽게 말해서 함수)에서 사용하는 값들을 저장하는 곳이다. 9번부터 15번까지는 임시 레지스터이다. 프로그래머가 사용할 수 있는 레지스터는 9번부터 15번까지이다. 참고로 다른 레지스터를 이용하고자 한다면 기존에 있었던 데이터를 메인에 백업을 해두고 사용해야한다.
그리고 28번은 SP(Stack Pointer)로 현재 스택의 최상위 값을 나타낸다. 30번은 LR(Link Register)로 현재 프로시저가 값을 반환해야하는 주소를 나타낸다. 그리고 우리가 프로그래밍을 하다보면 0을 쓸 일이 굉장히 많은데 그래서 0은 그냥 31번째 레지스터에 고정값으로 넣어두었다.
이렇듯 레지스터는 64비트가 32개가 있으니까 총 256byte이다. 그에 비해 메인 메모리는 단위가 기가바이트이니 우리는 그 사이에서 데이터를 주고 받아야 한다. 데이터를 메인에서 가져오는 것을 Load라고하고 메인에 저장하는 것을 Store라고 한다.
Memoery Operands
우리가 일반적으로 데이터를 저장하는 단위는 8bit, 즉 1byte이다. 메모리에서 주소가 1올라갔다는 것은 1byte가 증가했닫는 의미이다. 하지만 메모리에 실제로 데이터를 저장할 때는 일반적으로 4byte씩 저장한다. int나 long, pointer, size_t같은 타입은 4byte씩 저장하고 우리는 이렇게 4byte를 1word라고 한다.
메모리를 가져오는 것의 예제를 한 번 봐보자.

위 사진의 오른쪽에 메모리를 먼저 보면은 주소가 8씩 증가하고 있다. 이는 8byte씩 증가하고 있는 것으로 메모리의 한 셀의 크기가 8byte라는 것을 알 수 있다. 먼저 A[12]에 데이터를 저장하기 위해 A[8]에 있는 데이터를 가져와야 한다. A배열의 시작 주소(base address)가 x22에 있다고 했으니 x22에서 index가 8만큼 떨어진 곳에 있는 주소를 구해야하는데, index 1개당 8byte이니 64만큼 떨어진 곳에서 데이터를 가져와야 한다. 그래서 x22에 #64를 더한 주소를 x9에 저장하고, x9에 있는 값과 h(x21)을 더해서 x9에 있는 값을 x22에서 96byte만큼 떨어진 주소에 저장하면 연산이 완료된다.
Immediate Operands
우리의 연산에 상수가 사용된다면 우리는 immediate 더할 수 있다. 명령어 집합에는 각 상수를 정의하는 값들이 있고 상수를 메모리에서 꺼내오는 것이 아니라 명령어 집합에 있다면은 훨씬 빠르게 꺼내올 수 있을 것이다.
그래서 똑같이 ADD연산을 해도 뒤에 immediate를 뜻하는 I가 붙으면은 상수값을 가져와서 연산을 하는 명령어가 된다. 그래서 훨씬 더 빠르게 연산을 할 수 있다. 여기서 우리는 일반적인 경우라면 더 빠르게 하자라는 3번째 디자인 원칙을 엿볼 수 있다.
