- Jsoup 으로는 정적 웹 에서의 크롤링만 가능하다.
- 동적 web 크롤링을 하려면 selenium 을 사용해야 한다.
- 🔗 selenium 으로 크롤링 하기
✏️ Jsoup 으로 백준 크롤링 하기
📍 환경설정
- dependency
implementation 'org.jsoup:jsoup:1.14.2'📍 HTML 코드 확인
- 크롤링을 하기위해서 대상이 되는 웹페이지의 html 태그를 찾아야 한다.
- 백준의 랭킹 리스트를 크롤링으로 알아보려고 한다.
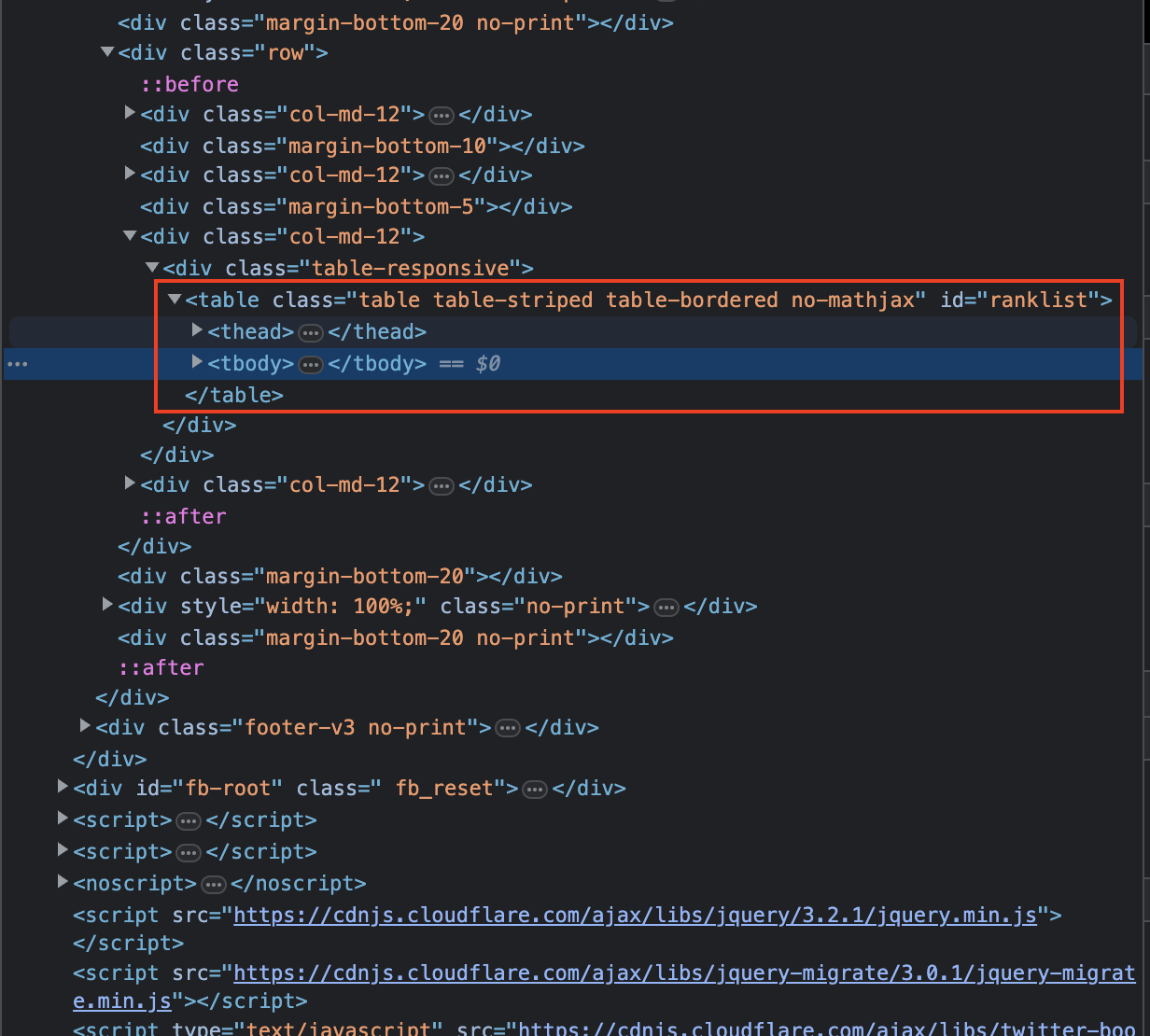
- 개발자 도구 (F12) 의 Elements 항목에서 원하는 소스를 확인할 수 있다.
- 백준의 랭킹 리스는 보는것처럼 테이블로 되어있고, id 값은
ranklist로 되어있다.
📍 Connection 하기
- 크롤링을 하려는 url 에 connenction 을 한 후,
모든 html 문서를document변수에 저장한다. - 이제 생성한
document변수에서 원하는Element를 추출하면 web page 의 원하는 값을 변수로 저장할 수 있다.- 목표로하는 태그가 복잡할수록 별도의 method 로 분리해 관리하는것이 좋다.
public static void getWebData() {
// 커넥션 생성
final String url = "https://www.acmicpc.net/ranklist";
Connection con = Jsoup.connect(url);
try {
// html 조회
Document document = con.get();
// table head 조회
String data = getData(document);
// 콘솔에 data 출력
System.out.println(data);
// 예외 처리
} catch (IOException e) {
}
}- 선택자로 크롤링하기
select()를 사용해 원하는 태그를 찾을 수 있다.태그+class 명 , id 명- 내부에서 한번 더 찾아할 경우 띄어쓰기로 구분한 뒤 같은방법으로 입력해주면 된다.
- class 나 id 가 없다면 입력하지 않아도 된다.
a[href]처럼 특정 속성이 있는 태그만 선택하는것도 가능하다.
- elements 에는 선택자로 지정한 페이지 내에 존재하는 모든 태그가 담기게된다.
- 만약 elements 의 모든 text를 출력하고 싶다면 바로
text()를 사용하면 된다. - 한번 더 걸러주고 싶다면
select()를 한번 더 사용해 걸러줄 수 있다.
- 만약 elements 의 모든 text를 출력하고 싶다면 바로
private static String getData(Document document) {
// 찾고있는 태그와 id 또는 class 를 입력해 원하는 태그를 찾을 수 있다.
Elements elements = document.select("div.username span");
System.out.println(elements.size());
return elements.text();
}
잘못된 내용 PR 환영