알고리즘 스킬
1.구간의 합
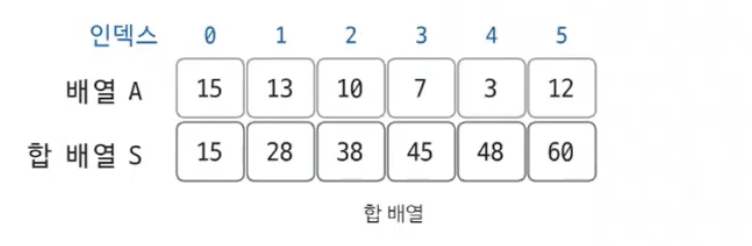
구간 합은 합 배열을 이용해 시간 복잡도를 더 줄이기 위해 사용하는 특수한 목적의 알고리즘 이다.배열의 특정 구간만의 값을 빠르게 구할 때 사용하는 기술이다.코딩 테스트에서 사용 빈도가 높은 기술이다.합배열은 기존 배열을 전처리한 배열이다.합배열은 기존 배열의 0번 인
2.투 포인터
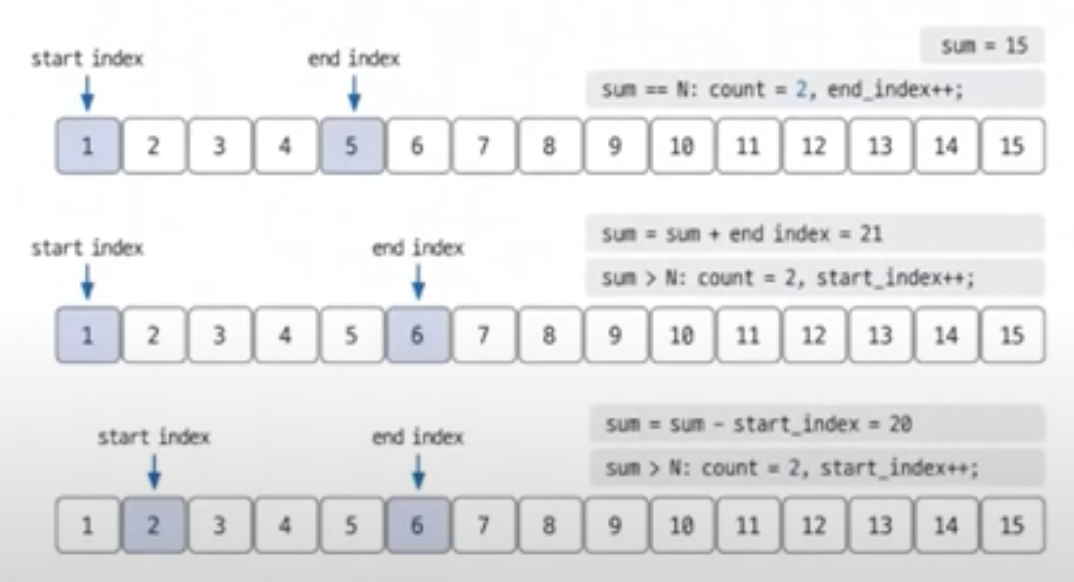
투 포인터는 배열에서 두개의 포인터를 사용해 원하는 조건을 만족시키는 부분을 찾거나,원하는 값을 찾는 기술이다. \- 이 방식으로 시간복잡도 문제를 해결할 수 있다. \- 주로 정렬된 배열이나 리스트와 관련된 문제에서 유용하게 사용되는 기술이다.🔗 투 포인
3.슬라이딩 윈도우

투 포인터 알고리즘과 매우 비슷한 방식으로,2개의 포인터로 범위를 지정한 다음 범위를 유지한 채로 이동하며 문제를 해결하는 방식 \- 윈도우는 지정된 범위를 뜻한다. \- 🔗 투 포인터윈도우를 처음 생성할 때는 윈도우 안의 요소를 배열에 저장시킨다.윈도우를
4.DFS - 깊이 우선 탐색
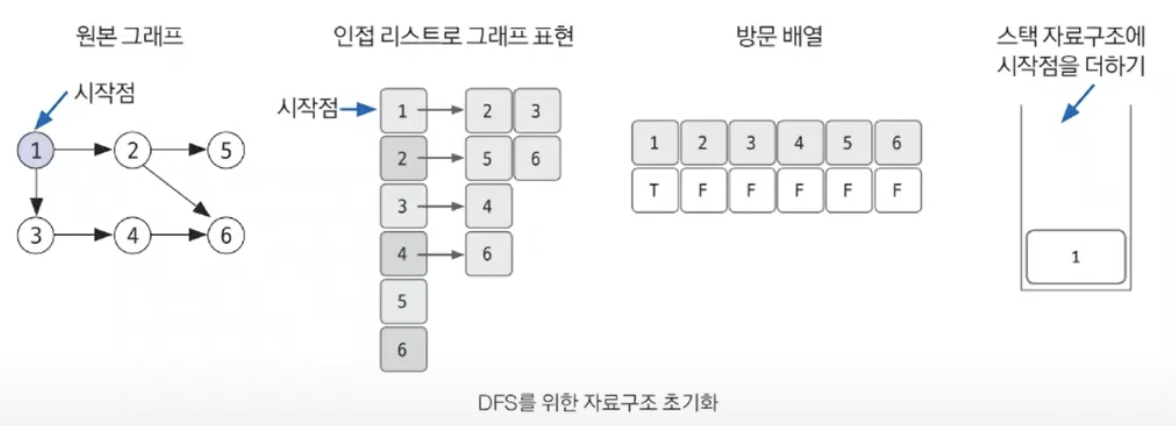
그래프 완전 탐색 기법 중 하나이다.그래프의 시작 노드에서 출발해 탑색할 한 쪽 분기를 정하여 최대 깊이까지 탐색을 마친 후,다른 쪽 분기로 이동해 다시 탐색을 수행하는 알고리즘이다. \- DFS 는 후입 선출의 특성을 가지므로 재귀 함수 또는 Stack 을 이용
5.세그먼트 트리
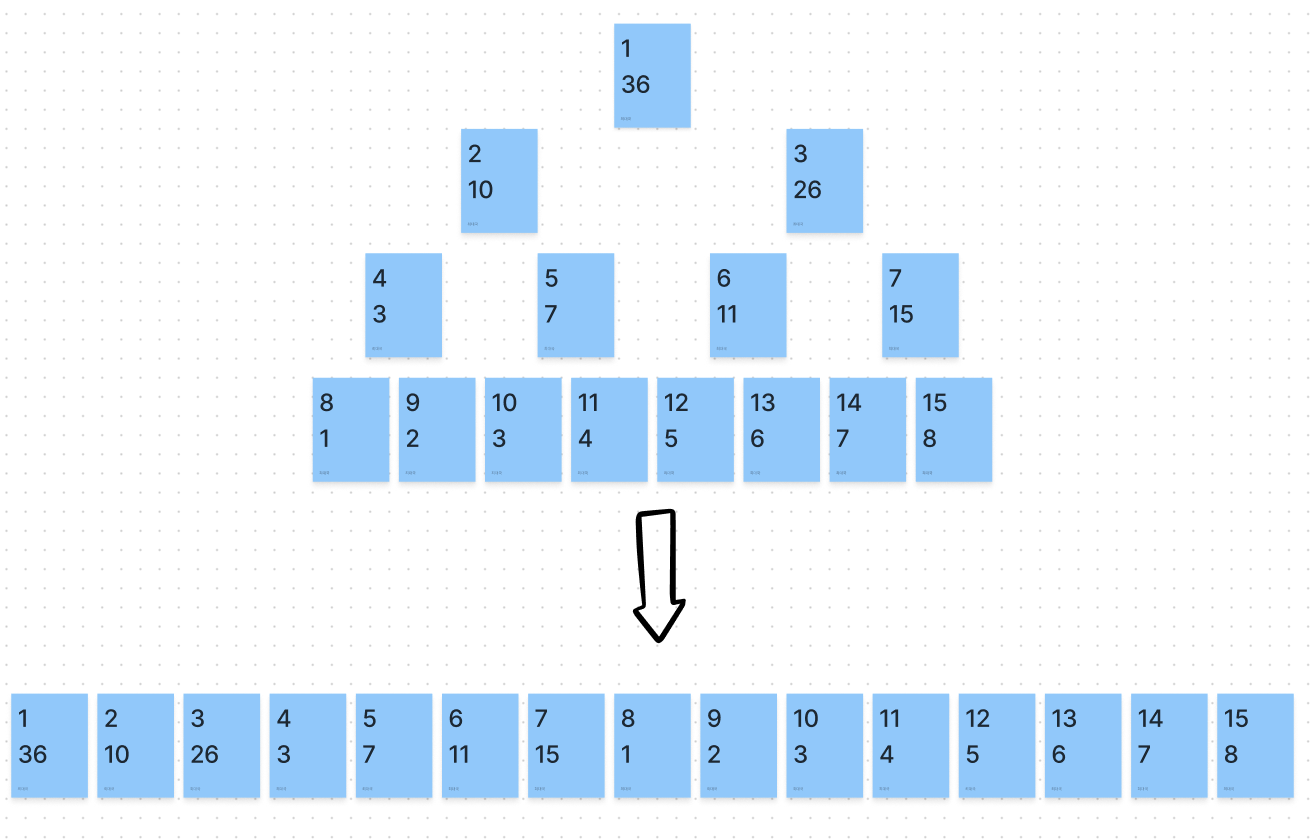
주어진 데이터의 구간 합과 데이터 업데이트를 빠르게 수행하기 위해 만들어진 자료구조의 형태더 큰 범위는 인텍스 트리 라고 불리는데, 코테 영역에서는 큰 차이는 없다.🔗 합배열 구하기구간 합, 최대 값, 최소 값 구하기로 나눌 수 있다.트리 초기화 하기 → 질의값 구하
6.java util 의 정렬
직접 정렬 알고리즘을 구현하는 것 보다 java util 의 라이브러리를 사용한 정렬이 더욱 디테일하게 최적화가 되어있기 때문에접근성과 효율적인 측면 모두 사용하지 않을 이유가 없다.🔗 퀵 정렬dual-pivot Quick Sort 즉, 퀵 정렬 알고리즘을 사용해 정
7.2차원 배열 정렬하는 방법
이 방법으로 객체등 다양한 배열들을 원하는 조건으로 정렬시킬 수 있다.2차원 배열은 Arrays.sort() 를 사용해 정렬하면 아래와 같은 오류가 발생한다.2차원 배열을 정렬하기 위해선 구체적인 비교 기준을 정해줘야 한다.규칙반환값이 양수, 음수 기준으로 정렬이 된다
8.BFS - 너비 우선 탐색
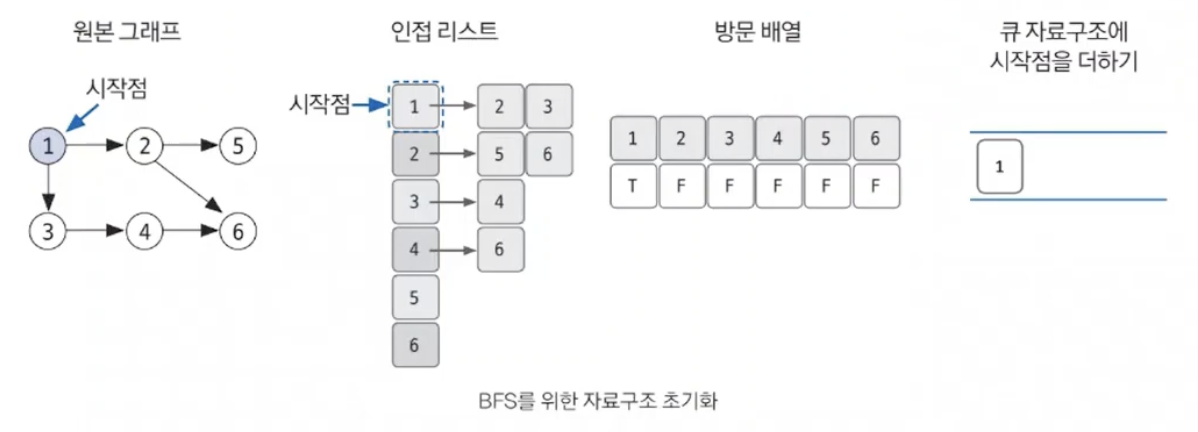
그래프를 완전탐색하는 방법 중 하나로,시작 노드에서 출발해 시작 노드를 기준으로 가까운 노드를 먼저 방문하면서 탐색하는 알고리즘이다. \- 목표노드의 끝에 도착하는 경로가 여러개일 때 최단 경로를 보장한다.DFS 와 반대로 FIFO 방식인 Queue 가 사용된다.
9.이진 탐색
이진 탐색은 data 가 정렬돼 있는 상태에서 원하는 값을 찾아내는 알고리즘 이다.대상 data 의 중앙값과 찾고자 하는 값을 비교해 data 의 크기를 절반씩 줄이면서 대상을 찾는다.O(logN) 의 시간 복잡도를 갖고 있다.오름차순으로 정렬된 data 일 경우 아래
10.탐욕법 - Greedy
현재 상태의 선택지 중 최선의 선택지를 계속 선택하면 전체의 선택지중 최선의 선택일거라 가정하는 알고리즘 이다.현재의 선택이 미래의 선택에 영향을 주지 않는경우부분의 초적 해가 모여 전체의 최적 해가 되는 경우위 2가지 조건을 만족할 때 어떻게 정렬해야 합리적인 선택을
11.DP - 동적 계획법
큰 문제를 작은 문제로 나눌 수 있어야 한다.작은 문제들이 반복돼 나타나고 사용되며 이 작은 문제들의 결괏값은 항상 같아야 한다.모든 작은 문제들은 한 번만 계산해 DP 테이블에 저장하며 추후 재사용할 때는 이 DP 테이블을 이용한다.이 방식을 메모이제이션 기법이라고
12.replace()
replace 는 String 내의 모든 특정한 text를 원하는 text로 바꾸는 method 이다. ex)보는바와 같이 특정을 한번에 한가지 밖에 할 수 없다.바꿔야 하는 부분이 다양할 경우 하나하나 새로운 변수를 지정해야만 하기때문에그런 경우에는 replace
13.String Builder 와 String Buffer
기본적인 string 의 경우 이렇게 변수를 설정할경우v1 의 값 , v2 ,v3 의값 3개의 변수와v1 + v2 의 값을 가진 변수 , 거기에 v3를 더한 값을 가진변수총 5개의 변수가 필요하므로 데이터가 불필요하게 소진된다 이를 방지하기 위해서 Builder 를
14.Hash Map
map 은 기본적으로 key 와 value 2개의 container를 가지게 된다.예를 들어 key 값으로 "one" / value 에 1 을 넣을경우intput : "one" 을 할경우output : 1 이 출력된다. 💡 ket 값은 중복이 불가하지만 value
15.Arrays
배열을 다루기 편리한 static 메서드를 담고있는 라이브러리괄호안에 배열을 넣으면 for 문 없이도 index 출력가능다차원 배열일 경우는 deepToString() 을 사용하면 된다.배열을 오름차 순으로 정렬한다.배열의 index 의 위치를 출력하는 기능❗️배열이
16.Set 과 List
🔗 Collections Framework 의 구성Collection 을 상속하고 있는 interface 임 (Class 아님)Setindex 값 중복 불가index 순서가 보장되지 않음List \- index 값 중복 가능 \- add 한 순서대로 값이
17.Stream
다양한 데이터 소스를 표준화된 방법으로 다루기 위한 것데이터 소스 : Collection (Set, List, Map) , Array …Stream 은 데이터 소스로 부터 데이트를 읽기만 할 뿐 변경하지 않는다.원본에 영향을 주지안고 작업을 할 수 있음일회성으로 사용
18.Stack
사전적 의미로는 쌓다, 더미 라는 뜻을 갖고 있는 Stack 은상자에 물건을 쌓아 넣듯이 data 를 쌓는 구조라고 할 수 있다.Stack 의 특징은 가장 먼저 넣은 값이 가장 나중에 나온다는 것이다.LIFO (Last In First Out) 구조다른 제네릭을 사용하
19.Queue
큐는 반대로 선입선출(First-in / First-out) 으로 이뤄진 자료구조이다.삽입과 삭제가 양방향 에서 이뤄진다.rear : 가장 나중에 추가된 인덱스front : 가장 처음에 추가된 인덱스add : rear 에 데이터를 추가하는 연산poll : front 의