너무나 당연해서 생각해보지 못했다.
우리는 브라우저의 주소창에 www.naver.com 을 입력한다.
그러면 자동으로 멋진 웹사이트가 나타난다.

너무나 당연하지만, 이러한 동작이 어떻게 가능한건지 생각해본적이 없었다. 그래서 오늘 웹사이트 동작 원리에 대해 알아보려고 한다.
질문과 대답
Q: 주소창에 입력하면 어떻게 사이트가 나타날까?
앞서 말했듯이, 우리는 브라우저의 주소창에 www.naver.com이라는 문자를 입력하고 엔터를 누른다. 이 행위는 아래와 같은 행위를 하라고 브라우저에게 명령하는 것이다.
www.naver.com의 IP 주소 알아내기

- 알아낸 IP 주소로 파일 요청하기

위의 과정에서 알 수 있듯이 아래의 두 문장은 동일한 의미입니다.
- 도메인(www.naver.com)을 주소창에 입력한다.
- 해당 IP주소(223.130.195.95)로 GET요청을 보낸다.
참고) 네이버에 접속한 후, 개발자도구의 Network 탭을 보면, www.naver.com에 GET요청을 보낸 것을 확인할 수 있다. 그리고 그 Response로 HTML코드를 보냈다.


A: 주소창에 입력하는 것은, 해당 주소의 서버에 HTML파일을 달라고 요청하는 것이기 때문이다.
Q: HTML 파일은 텍스트 문서일 뿐인데, 어떻게 버튼이 그려지고 이미지가 그려지는걸까?
우리가 알고 있는 HTML 파일은 대략 아래와 같은 텍스트 문서이다.
<html>
<head>
<meta charset="UTF-8">
</head>
<body>
<button>click!</button>
</body>
</html>그런데 이런 텍스트가 어떻게 네이버의 수많은 요소들로 바뀌는걸까?🧐

앞서 등장했던 사진이다. 당연한 말이지만, 우리는 네이버 서버로부터 index.html 파일을 이진수인 바이트로 받는다. 그리고 또 당연히 브라우저는 바이트를 이해하지 못한다. 우리의 목적은 서버로 전달받은 바이트를 브라우저가 이해할 수 있는 형태로 변환하는 것이다. 여기서부터 시작해보자 🏃🏻♀️
브라우저에선 서버로부터 받은 바이트 정보를 이해하기 위해 렌더링 엔진을 사용한다.
이제 렌더링 엔진이 어떻게 동작하는지 알아보자!
서버는 바이트와 함께, 어떤 방식으로 인코딩해야하는지 알려준다. 그 정보는 Response Header에 content-type을 보면 알 수 있다. 아래의 경우는 UTF-8의 방식이다.

.
인코딩을 하면, 우리에게 익숙한 HTML 코드의 결과물이 나온다!
<html>
<head>
<meta charset="UTF-8">
</head>
<body>
<button>click!</button>
</body>
</html>.
렌더링 엔진은 이 텍스트를 토큰으로 변경한다.
토큰?
토큰이란, 의미를 가진 가장 작은 단위를 뜻한다. 한글로 생각하자면 형태소단위이다.
: 구글 검색
.
위의 HTML코드를 토큰화하면 아래와 같다.
// 토큰
{
startTag: "head",
contents: {
startTag: "head",
contents: { ... }
},
endTag: "head"
}.
토큰을 객체로 변환하여 노드를 생성한다. 노드는 이 다음 단계에서 만들 DOM의 최소 단위이다.

.
노드를 트리구조로 연결하여 브라우저가 이해할 수 있는 DOM 을 구성한다. DOM 이란, 브라우저가 이해할 수 있는 트리 형태의 자료구조이다. 렌더링 엔진은 이 DOM의 구조에 따라 레이아웃을 잡는다.

.
지금까지 바이트에서 DOM트리 구조까지 변화하는 과정을 살펴보았다. 우리는 이 과정을 파싱(Parsing)이라고 한다!
A. 서버로부터 받은 HTML파일을 파싱하여 DOM트리 구조를 만든다.
Q. 그렇다면 CSS는 어떻게 적용되는걸까?
우리는 위에서 HTML 코드를 파싱하는 과정을 알아봤다. HTML 코드를 위에서 아래로 쭉 읽다보면 css파일을 불러오는 코드를 마주하게된다.
<html>
<head>
<meta charset="UTF-8">
<!-- css 파일 등장!-->
<link rel="stylesheet" href="style.css">
</head>
</html>렌더링 엔진은 css 코드를 마주하게되면, HTML 파싱을 잠시 멈추고 해당하는 css파일을 다시 서버에 요청한다. (왜냐면 우리는 index.html 파일밖에 없기 때문!)
css파일을 정상적으로 받아오면, HTML을 파싱한 방식과 마찬가지로 아래의 파싱과정을 거쳐 CSSOM 을 생성한다.
- 바이트
- HTML 텍스트
- 토큰 생성
- 노드 생성
- CSSOM 생성
CSSOM은 CSS Object Model의 약자로, DOM과 마찬가지로 트리 형태의 자료구조이다.

.
CSSOM 생성이 마치면, 중단되었던 HTML파싱을 다시 시작한다. HTML파싱까지 마무리되었다면, DOM과 CSSOM을 합쳐 Render Tree 를 만든다.
브라우저는 이 Reder Tree를 보고 레이아웃, 위치, 색 등을 판단하여 UI를 구성하고 브라우저에 띄운다!
단, 여기서 주의해야할 점은 Render Tree는 말 그대로 화면에 보여줄 노드들의 집합체이다. 따라서 렌더링되지 않는 노드(meta, link 등)와 CSS에 의해 숨김처리된 노드(display: none)들은 Render Tree에 포함되지 않는다.
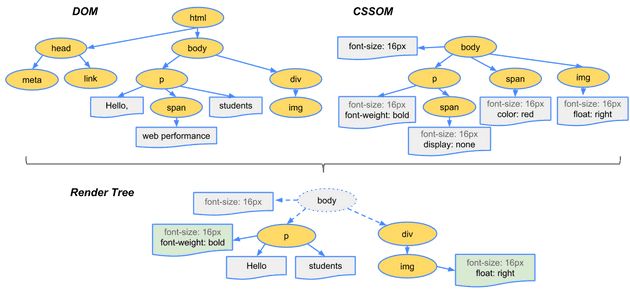
A. HTML을 파싱하는 것 처럼 CSS파일을 파싱하여 CSSOM을 만들고, DOM과 CSSOM을 합쳐서 Render Tree를 만든다.
Q. Render Tree가 어떻게 화면에 나타나는걸까?
Render Tree를 보면 노드간의 부모/자식 관계를 알 수 있으며, 각각의 노드가 어떤 스타일을 갖고 알 수 있다. 따라서 렌더링 엔진은 Render Tree를 보며, 레이아웃(A)을 잡고, 각각의 노드에 스타일을 입힌상태로 브라우저에 그린다(B). 이 과정을 레이아웃(A)과 페인팅(B)이라고 한다.
A. 렌더링 엔진이 Render Tree를 보며 레이아웃을 잡고 스타일을 입혀 브라우저에 그린다.

