
- 컴퓨터 파워가 기하급수적으로 향상
- 자바도 언어 및 런타임 설계가 프로세서가 강력해지는 시류와 잘 맞아떨어짐
- 하지만 자바 프로그래머는 가용 리소스를 최대한 활용할 수 있도록 근간 원리와 기술을 알아야 함
📕 3.1 최신 하드웨어 소개
- 하드웨어를 레지스터 기반으로 산술, 로직 등으로 연산 수행하는 뻔한 머신으로 인식하지 않기
- 1990년대 이후, x86/64 아키텍처 위주
- 프로세서 작동 원리를 단순화한 멘탈 모델(정신 모형)은 맞지 않아서 생뚱맞은 결론 내리기 쉬움
🧽 3.2 메모리
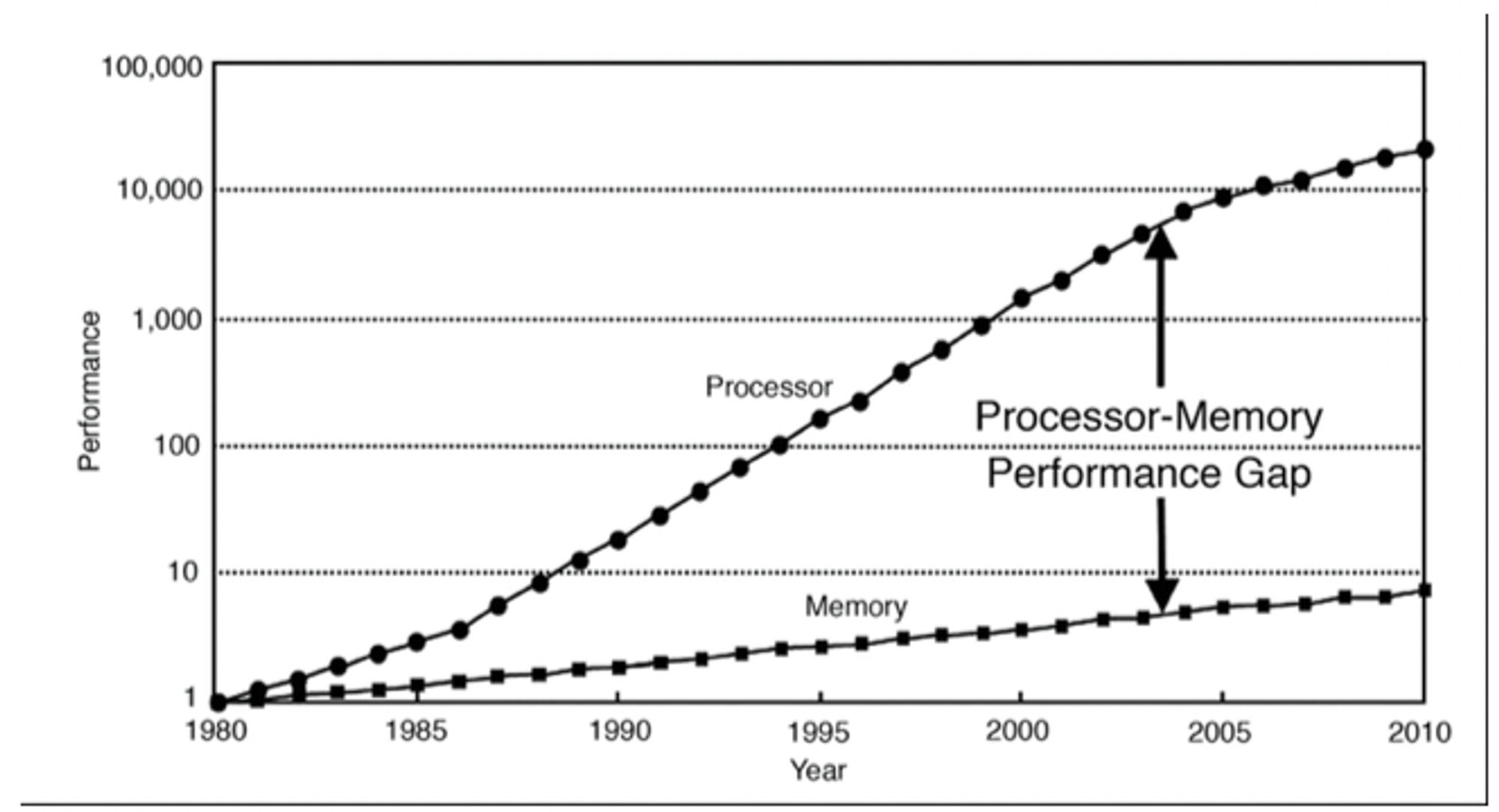
- 무어의 법칙에 따라 급증한 트랜지스터는 처음에 클럭 속도를 높이는 게 쓰임
- 그러나 빨라진 칩의 속도를 메인 메모리가 맞추기 어려워짐
- 그래서 클럭 속도 향상은 의미 없어짐
3.2.1 메모리 캐시
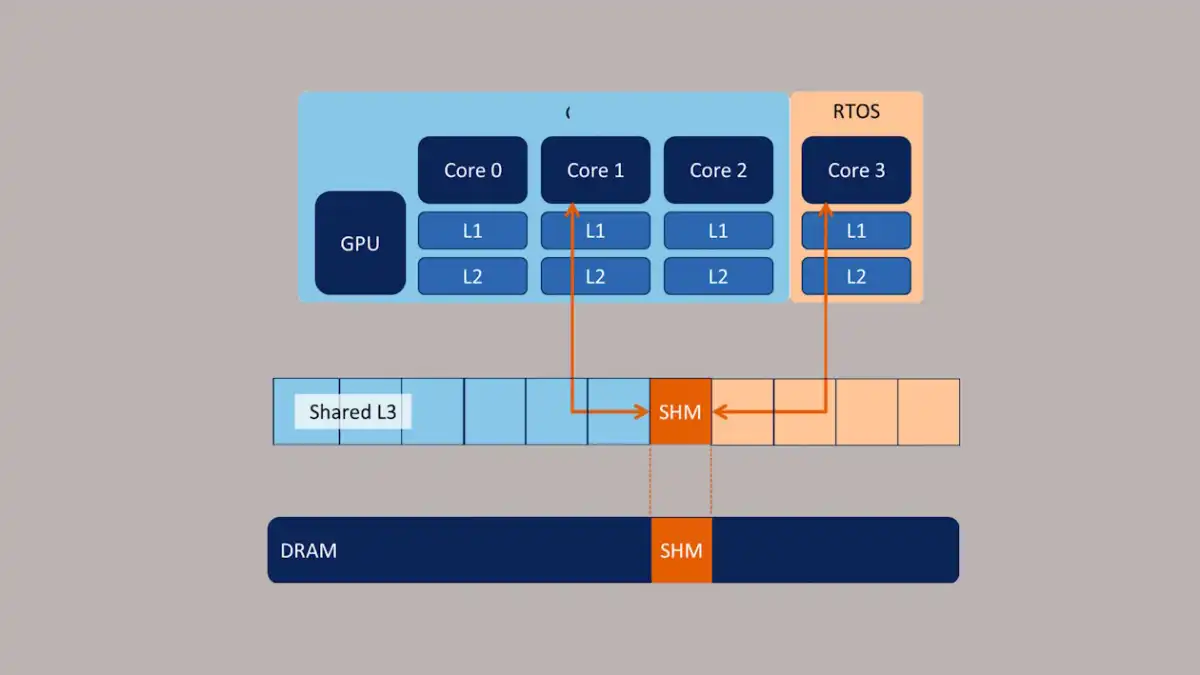
- CPU 활용을 위해 CPU 캐시 고안
- 속도: 레지스터 > CPU 캐시(= CPU에 있는 메모리 영역) >> 메인 메모리
- 요즘 CPU 캐시 계층 존재
- 액세스 빈도가 높을수록 프로세서 코어와 더 가까이 위치
- CPU와 가장 가까운 캐시 L1, 그 다음은 L2 ~
- 일반적으로 L1, L2는 각 실행 코어 전용 프라이빗 캐시, L3은 일부 또는 전체 코어의 공유 캐시
- 캐시 아키텍처를 이용해 액세스 시간 감소 및 처리율 개선
- 하지만 메모리 데이터를 어떻게 캐시로 가져오고, 캐시 데이터를 어떻게 메모리에 다시 써야하는지 결정
- 캐시 일관성 프로토콜로 해결
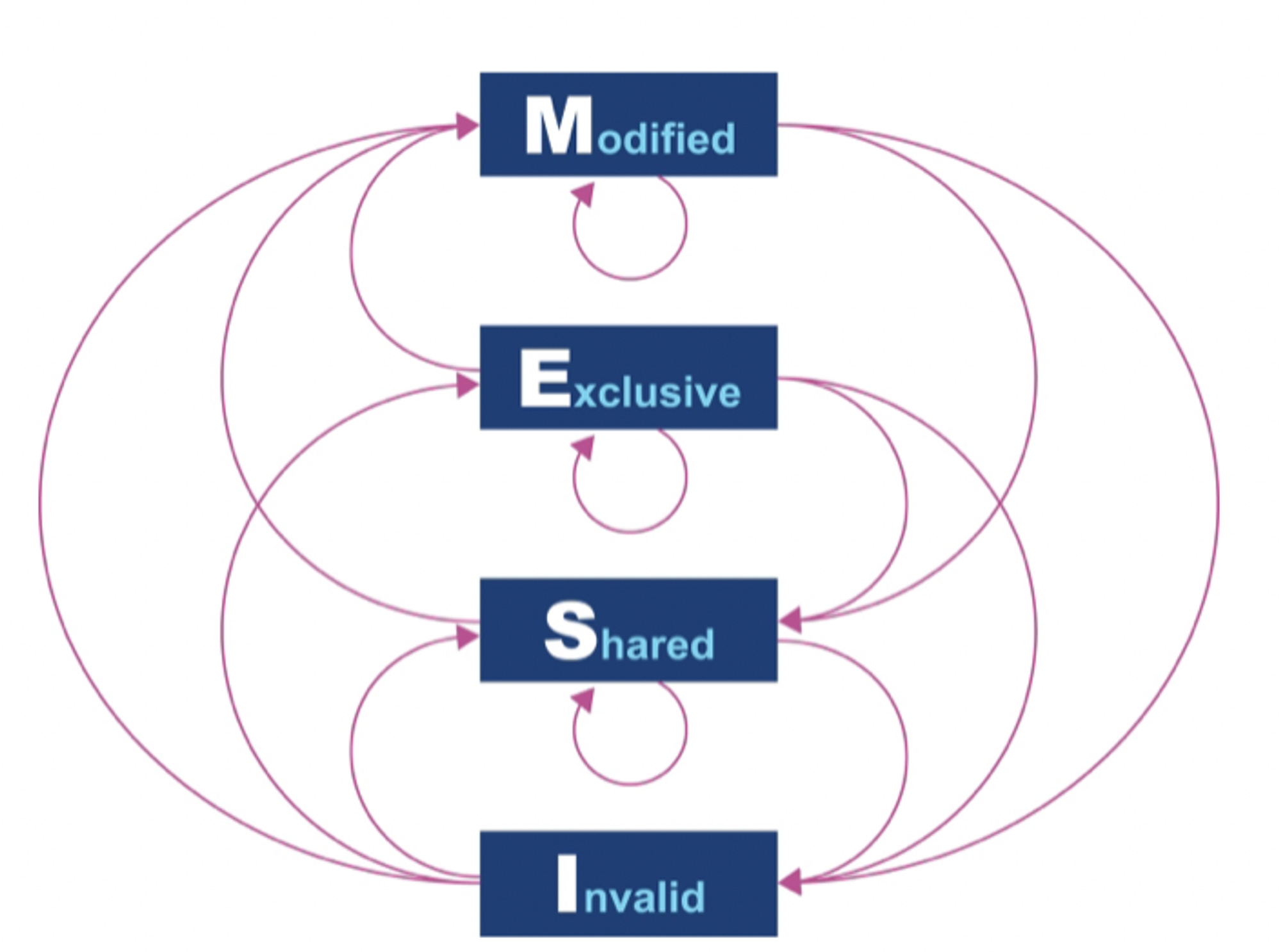
MESI 프로토콜
- 캐시 라인(보통 64바이트) 상태를 네가지로 정의
- Modified(수정): 데이터가 수정된 상태
- Exclusive(배타): 이 캐시에만 존재하고 메인 메모리 내용과 동일한 상태
- Shared(공유): 둘 이상의 캐시에 데이터가 들어 있고 메모리 내용과 동일한 상태
- Invalid(무효): 다른 프로세스가 데이터를 수정하여 무효한 상태
- 멀티 프로세서가 동시에 공유 상태에 있을 수 있다
- 어느 한 프로세서가 배타나 수정 상태로 바뀌면 다른 프로세서는 모두 강제로 무효 상대가 됨
캐시 동작 방식
-
초기: 프로세서가 처음 나왔을 때는 매번 캐시 연산 결과를 바로 메모리에 기록(동시 기록: write-through)
- 메모리 대역폭을 너무 많이 소모하여 효율이 낮아 요즘은 사용하지 않음
-
최근: 후기록(write-back) 방식을 채택
- 캐시 블록을 교체해도 프로세서가 변경된 캐시 블록만 메모리에 기록하여 메인 메모리 트래픽 감소
-
데이터 업데이트의 성능에서 중요한 것은 메모리 버스 예열
-
자바 성능에서 중요한 것은 객체 할당률에 대한 애플리케이션 민감도 → 이후 자세히
🪛 3.3 최신 프로세서의 특성
- 메모리 캐시는 점점 증가한 트랜지스터를 가장 확실하게 활용하지만, 지난 수년간 여러가지 다른 기술도 등장
3.3.1 변환 색인 버퍼(TLB, Translation Lookaside Buffer)
- 캐시에서 요긴하게 사용되는 장치
- TLB는 가상 메모리 주소를 물리 메모리 주소로 매핑하는 페이지 테이블의 캐시 역할을 수행
- 덕분에 가상 주소를 참조해 물리 주소에 접근하는 빈번한 작업 속도가 매우 증가
- TLB 가 없다면 가상 주소 lookup 에 16 cycles 이 필요하여 성능 저하
3.3.2 분기 예측과 추측 실행(Branch prediction)
- 프로세서가 분기하는 기준값을 평가하느라 대기하는 현상을 방지
- 차세대 CPU 는 다단계 명령 파이프라인을 사용해 CPU 1 사이클도 여러 단계로 나누어 실행
- 이런 모델은 조건문을 다 평가하기 전까지 분기 이후 다음 명령을 모름
- 이 결과로 분기문 뒤에 나오는 파이프라인을 비우는 동안 프로세서는 여러 사이클(최대 20회) 동안 정지
- 이런일이 없도록 CPU 는 가장 발생 가능성이 높은 브랜치를 미리 결정하는 휴리스틱 이론을 통해 예측
- 예측이 맞다면 바로 해당 브랜치 작업을 실행
- 틀리면 실행한 명령을 모두 폐기한 후 파이프라인을 비우는 비용을 지불
3.3.3 하드웨어 메모리 모델
- multi-core 시스템에서 메모리에 대한 근본적인 질문: 어떻게 하면 CPU가 일관되게 동일한 메모리 주소를 access 할 수 있을까?
실행순서와 메모리
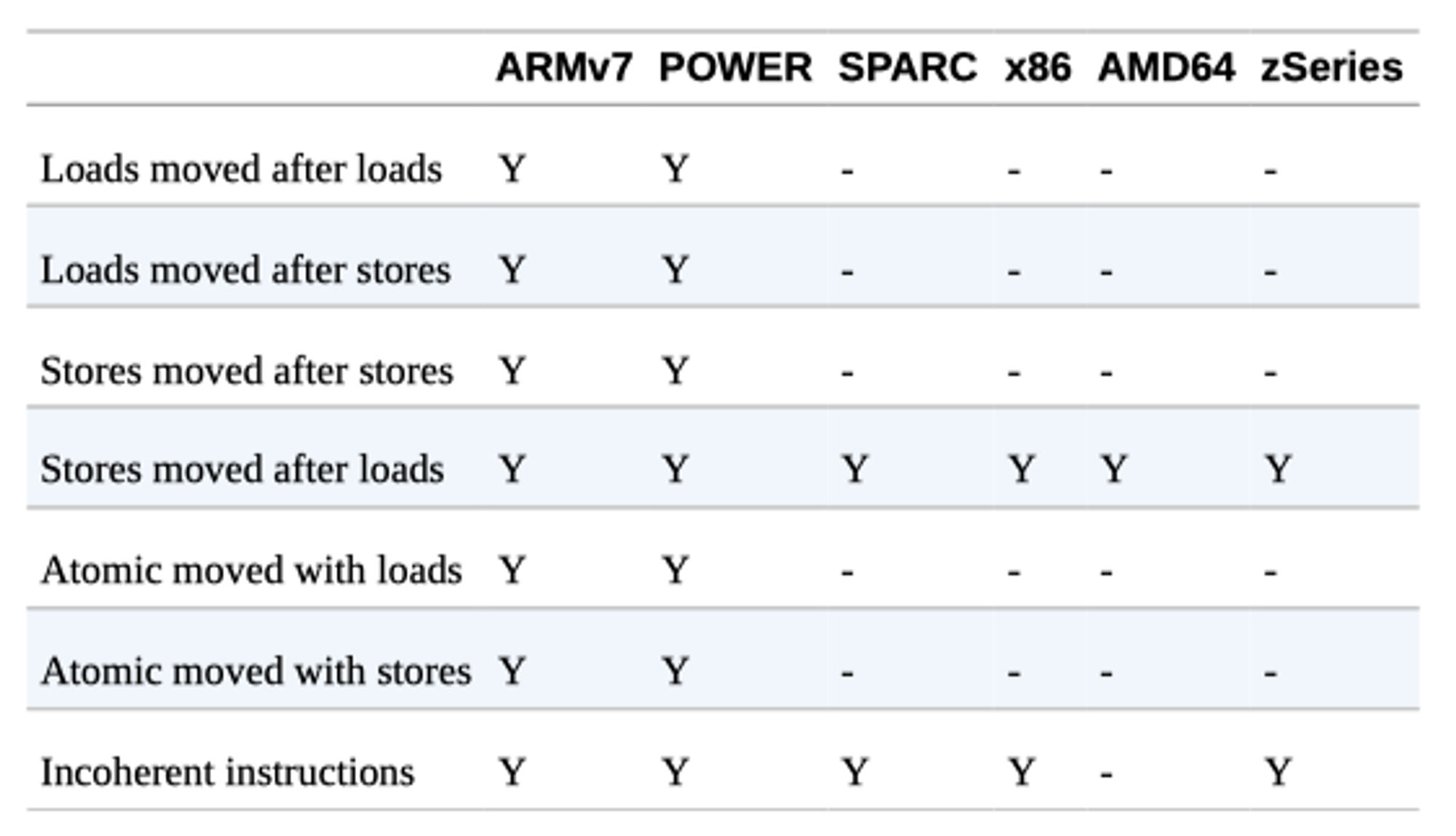
- JIT 컴파일러인 javac 와 CPU는 일반적으로 코드 실행 순서를 바꿀 수 있음
myInt = otherInt;
intCharged = true;- 두 할당문 사이에 다른 코드가 없으니 thread 입장에선 어떤 순서로 오든 상관 없어, 순서변경 가능
- 바라보는 다른 thread 입장에서 순서가 달라지만 intChareged 는 true 로 보여도 myInt 는 이전 값 일 수도
- 이런 방식은 x86 에선 불가능하고, CPU 아키텍처 마다 조금씩 상이
💊 3.4 운영체제
- OS 의 임무는 실행하는 프로세스가 공유하는 리소스 액세스를 관장하는 것
- Memory Management Unit(MMU, 메모리 관리 유닛)을 통한 가상 주소 방식과 페이지 테이블은 메모리 액세스 제어의 핵심으로, 한 프로세스가 소유한 메모리 영역을 다른 프로세스의 훼손 방지
- 앞에서 설명한 TLB의 경우는 물리 메모리 주소 look up을 줄이는 하드웨어 기능이다
- 메모리를 사용하면 S/W 가 엑세스 하는 시간이 빨라진다
- 메모리는 개발자가 다루기엔 너무 low level 이므로 스케쥴러에 대해 살펴본다.
3.4.1 스케쥴러
- 프로세스 스케쥴러는 CPU 접근을 통제 → 이때 실행 큐(Run Queue)를 사용
- 스케쥴러는 인터럽트에 응답하고, CPU 코어 액세스를 관리한다.
자바 스레드가 OS에서 사용하는 스레드와 일치하는 것이 성능적으로 이득→ 아니죠 이젠?
자바 스레드 생명 주기
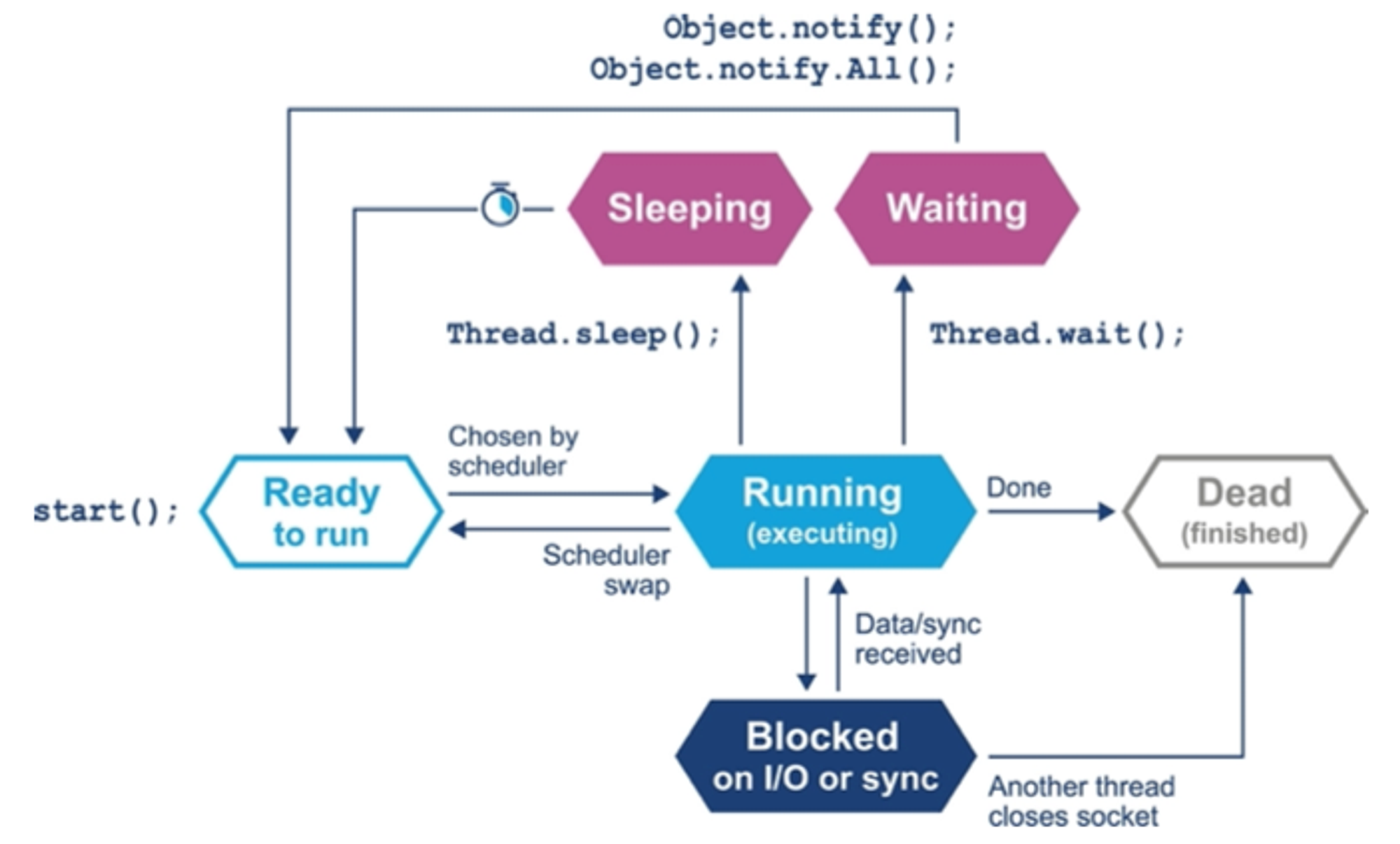
- 스케줄러는 할당시간 끝에 실행 큐를 사용해 스레드를 되돌려 큐의 맨 앞으로 배치시켜 다시 실행
- 스레드는 자신이 할당받은 시간을 포기하려면 sleep(), wait() 을 사용
- sleep() 잠드는 시간 명시
- wait() 대기조건 명시
- s/w 락에 걸려 blocking 될 수 있음
- 멀티 프로세스 환경에서 어떻게 실행될지 매우 복잡하고 예측이 어려움
- OS는 특성상 CPU에서 코드가 실행되지 않는 시간을 유발
- 정작 코드가 실행되는 시간 < 대기하는 시간
스케줄러의 동작
long start = System.currentTimeMillis();
for (int i = 0; i < 1_000; i++) {
Thread.sleep(1);
}
long end = System.currentTimeMillis();
System.out.println("Millies elasped: " + (end - start) / 4000.);- 1000회를 sleep == 1초간 sleep
- 스레드는 한번 잠 들때마다 큐의 뒤로가고 새로 시간을 할당받을 때까지 대기
- OS마다 코드의 실행 결과는 천차만별
- unix 는 10~20%가 오버헤드, 윈도우 초기 버전 180% 정도의 비효율
3.4.2 시간 문제
- 타이밍은 POSIX(Portable Operating System Interface) 표준이 있더라도 OS마다 다르게 동작
- java의 System.currentTimeMillis() 는 OS의 os::javaTimeMillis() 를 사용하는데 그 구현이 다름
OS별 차이
// BSD 유닉스(macOS) (솔라리스, 리눅스, AIX 등)
jlong os::javaTimeMillis() {
timeval time;
int status = gettimeofday(&time, NULL);
assert(status != -1, "bsd error");
return jlong(time.tv_sec) * 1000 + jlong(time.tv_usec / 1000);
}// 윈도우 MS
jlong os::javaTimeMillis() {
if (UseFakeTimers) {
return fake_time++;
} else {
FILETIME wt;
GetSystemTimeAsFileTime(&wt);
return windows_to_java_time(wt);
}
}- 윈도우는 유닉스의 timeval 구조체 대신 64bit FILETIME 구조체를 이용해 1601년 이후 경과한 시간을 100나노초 단위로 기록
- timeval: 1970년 1월 1일 자정 기준으로 1초씩 흐른 시간을 4byte로 나타냄
- 윈도우는 HW 따라 상이
3.4.3 컨텍스트 교환
- 컨텍스트 교환: OS 스케쥴러가 현재 실행중인 스레드/태스크를 없애고 대기중인 다른 스레드/태스크로 대체하는 프로세스
- 유저 스레드 사이에서나 특히 유저 모드에서 커널 모드로 바뀌는 모드 교환은 비싼 작업
- 유저 공간에 있는 코드가 액세스 하는 메모리 영역은 커널 코드와 거의 공유할 부분이 없기 때문에 모드가 변경되면 명령어와 다른 캐시를 강제로 초기화
- 이때 TLB를 비롯한 다른 캐시도 무효화
- 이 캐시들은 시스템 콜 반환 시 다시 채워야 하므로 커널 모드 교환의 영향은 유저 공간으로 다시 제어권이 넘어가도 당분간 이어져 성능 하락
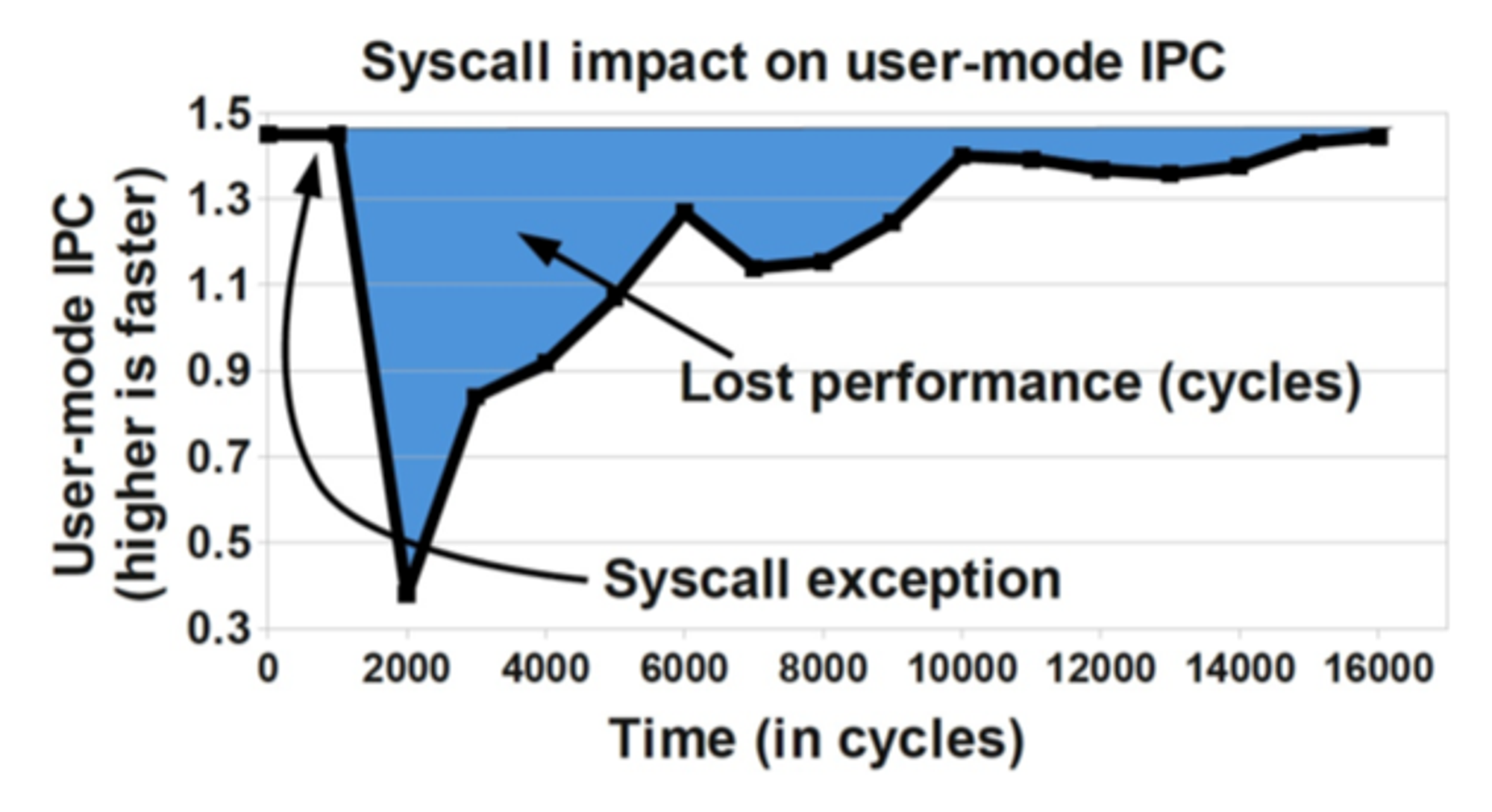
- 리눅스는 이 성능하락을 만회하기 위해 가상 동적 공유 객체(vDSO: Virtual Dynammically Shared Object) 라는 장치를 제공
- vDSO는 커널 프리빌리지드가 필요 없는 시스템 콜의 속도를 높이는데 사용하는 유저 공간의 메모리 영역
- 커널 모드로 컨텍스트 교환을 하지 않기 때문에 그만큼 속도가 빠름
gettimeofday() 시스템 콜 실제 동작
- 커널 자료 구조를 읽어 시스템 클록 시간을 얻음
- 부수 효과가 없어 프리빌리지드(=운영자 모드) 액세스가 필요 없음
- 이 자료구조를 vDSO 로 유저 프로세스 주소 공간에 매핑만 된다면 커널 모드로 변경할 필요 없음
- 따라서 위 그래프의 파란색 만큼의 손실을 감내하지 않아도 됨
- 타이밍 자료를 빈번하게 호출하는 java application 에서는 이러한 식으로 성능 개선
💒 3.5 단순 시스템 모델
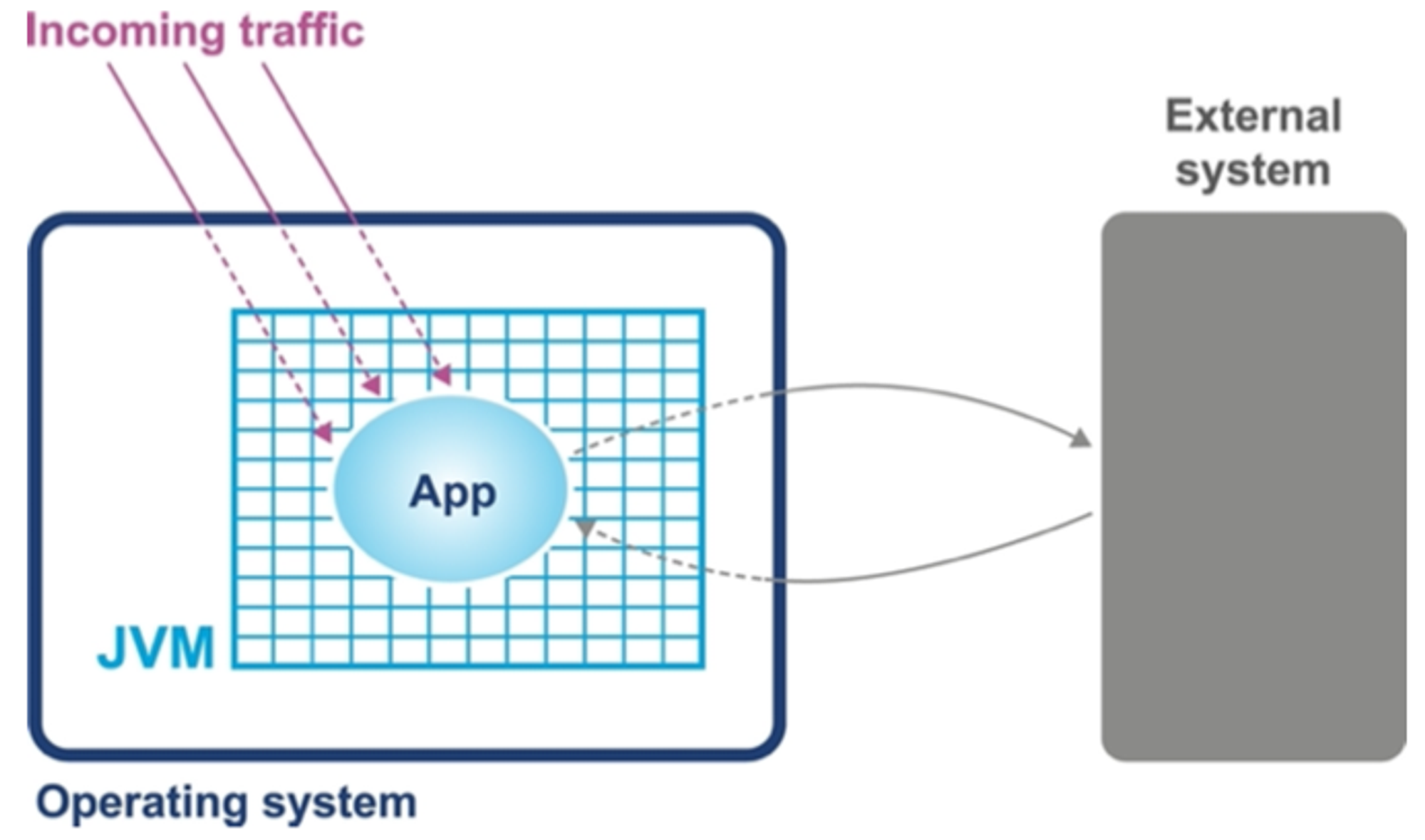
- 단순한 시스템 모델 A를 예로 들어 성능 문제를 일으키는 근원 탐색
- A는 근본 서브시스템의 OS 측정값으로 나타낼 수 있고, 표준 유닉스 명령줄 툴의 출력 결과와 직접 연관
- 유닉스 계열 OS에서 작동하는 자바 애플리케이션의 단순한 개념
- 기본 컴포넌트 구성
- 애플리케이션이 실행되는 하드웨어와 OS
- 애플리케이션이 실행되는 JVM/컨테이너
- 애플리케이션 코드 자체
- 애플리케이션이 호출하는 외부 시스템
- 애플리케이션으로 유입되는 트래픽
🪇 3.6 기본 감지 전략
- 애플리케이션이 잘 돌아간다 == CPU 사용량, 메모리, 네트워크, 등 리소스를 효율적으로 잘 이용하고 있다
- 성능 진단의 첫 단추는 어느 리소스가 한계에 다다랐는지 밝히는 일
- OS는 유저 프로세스 대신 리소스를 관리하는 것이기 때문에 OS가 리소스 소모하는 건 지양
3.6.1 CPU 사용률
- 애플리케이션 성능을 나타내는 핵심 지표
- 부하가 집중되는 도중에는 사용률이 가능한 한 100%에 가까워야 함
- 성능 엔지니어 기본 툴 두 가지: vmstat, iostat (사용법 생략)
3.6.2 가비지 수집
- 핫스팟 JVM은 시작 시 메모리를 유저 공간에 할당/관리
- 그래서 메모리를 할당하느라 sbrk()같은 시스템 콜을 할 필요가 없음
→ 가비지 수집을 하려고 커널 교환을 할 일이 거의 x
CPU 사용률과 GC
- 어떤 시스템에서 CPU 사용률이 아주 높다? GC는 주범 X
- GC 자체는 유저 공간의 CPU 사이클을 소비하되 커널 공간의 사용률에 영향 x
- 어떤 JVM 프로세스가 유저 공간에서 CPU를 거의 100% 사용? GC 의심
- JVM에서 유저 공간의 CPU 사용률이 높은 건 대부분 GC 서브시스템 탓
- 꼭 GC 로그 확인하기
3.6.3 입출력
- 파일 I/O는 예로부터 전체 시스템 성능에 암적인 존재
- I/O는 다른 OS 파트처럼 분명하게 추상화되어 있지 않음
- 다행히 자바 프로그램은 대부분 단순한 I/O만 처리하며 I/O 서브시스템을 심한 가동도 적은 편
커널 바이패스 I/O
- 커널을 이용해 데이터를 복사해 user 공간에 넣는 작업이 비싼 고성능 작업
- 커널 대신 직접 네트워크 카드에서 유저가 접근 가능한 영역을 데이터를 매핑하는 전용 하드웨어/소프트웨어를 사용
- 커널 공간과 유저 공간 사이를 넘다드는 행위 "이중 복사"를 예방
- 자바는 이러한 구현체를 제공하지 않으므로 필요한 기능을 구현하려면 커스텀 라이브러리 필요
- 유용한 기능이기 때문에 고성능 I/O가 필요한 시스템에서 일반적으로 구현
3.6.4 기계 공감
- 기계 공감: 성능을 조금이라도 쥐어짜내야 하는 상황에서 하드웨어를 폭넓게 이해하고 공감해야하는 것이 중요
- JVM이 하드웨어를 추상화하였지만, 하드웨어와 어떻게 상호작용하는 이해해야 함
캐시 라인 동작 예시
- 멀티 스레드 환경에서 두 스레드가 동일한 캐시 라인에 있는 변수를 읽기/쓰기
- 경합이 발생한다 (race condition)
- 첫번째 스레드가 두번째 스레드의 캐시 라인을 무효화 하면 메모리에서 다시 읽어야 한다
- 두번째 스레드가 작업을 마치면 첫번째의 캐시라인을 무효화
- 이러한 문제를 어떻게 해결하여 캐시를 효율적으로 사용?
-
자바의 객체는 필드 배치가 고정돼 있지 않기 때문에 캐시 라인을 공유할 변수를 탐색 가능
-
변수 주변에 padding 을 넣어 강제로 다른 캐시 라인으로 보내는 것도 방법
→ 이러한 방법을 생각할 수 있는건 기계적 공감 덕분 (14장 더 자세히)
-
🚙 3.7 가상화
- 가상화는 1970년대 초 IBM 메인프레임 환경에서 최초로 개발
가상화의 특징
- 가상화 OS에서 실행하는 프로그램은 베어 메탈(즉, 비가상화 OS)에서 실행할 때와 동일하게 작동
- 하이퍼바이버는 모든 하드웨어 리소스 액세스를 조정
- 가상화 오버헤드는 가급적 작아야 하며 실행 시간의 상당 부분을 차지해선 안 됨
가상화에서의 성능 튜닝
- 비가상화 시스템에서 OS 커널은 프리빌리지드 모드로 동작 → HW 직접 제어 가능
- 가상화 시스템에서는 게스트 OS가 HW 제어 불가
- 그래서 프리빌리지드 명령어를 언프리블리지드 명령어로 치환
- 컨텍스트 교환이 발생하는 동안 캐시 플러시 방지를 위해 커널의 자료구조 섀도
3.8 JVM과 운영체제
- JVM은 자바 코드에 공용 인터페이스를 제공하여 OS에 독립적인 휴대용 실행 환경 제공
JNI (Java Native Interface)
- native 키워드를 붙인 네이티브 메서드
- 스레드 스케줄링같은 서비스를 위해 하부 OS에 액세스하는 용도
- 비교적 저수준의 플랫폼 관심사 처리
public Final native Class<?> getClass();
public native int hashCode();
protected native Object clone() throws CloneNotSupportedException;
public Final native void notify();
public Final native void notifyAll();
public native void wait(long timeout) throws InterruptedException- 예시) 시간 조회 플로우
-
네이티브 메서드
System.currentTimeMillis()는JVM_CurrentTimeMillis()라는 JVM 엔트리 포인 메서드에 매핑 -
.java/lang/System.c파일에 포함된JNI Java_java_lang_System_registerNatives()에 이러한 매핑 관계 설정 -
JVM_CurrentTimeMillis()는 VM 진입점에 해당하는 메서드 호출→ C 호출 관례에 따라 export된 C++함수를 os::javaTimeMillis()를 호출하는 구조
-
🔅 3.9 마치며
- 프로세서 설계 및 최신 하드웨어 성장 미쳣넹~
- 다음에는 성능 테스트의 핵심 방법론 소개 ㄱㄱ
🦴 참고
