
🎫프로세스
OS는 다양한 프로그램을 수행
- 일괄 처리 시스템(batch system)은 작업(job)들을 실행
- 시분할 시스템(time-shared system)은 사용자 프로그램들 또는 태스크(task)들을 수행
- 작업, 태스크, 프로세스는 거의 비슷한 단어
- 프로세스란 수행중인 프로그램!
프로세스 구성 요소
- 텍스트 섹션(text section) : 프로그램 코드
- 프로그램 카운터(pc, program counter), 레지스터
- 스택(stack) : 임시 데이터 저장소 (매개 변수, 복귀주소, 지역 변수)
- 데이터 섹션(data section) : 전역변수
- 힙(heap) : 실행 중에 동적으로 할당되는 메모리

프로그램? 프로세스?
- 프로그램은 디스크에 저장된 수동적 존재 : 실행파일
- 프로세스는 능동적 존재 : 프로그램의 실행파일이 메모리에 적재될 때 프로세스가 됨
- 동일한 프로그램(실행파일)이 여러 개의 프로세스가 될 수 있음
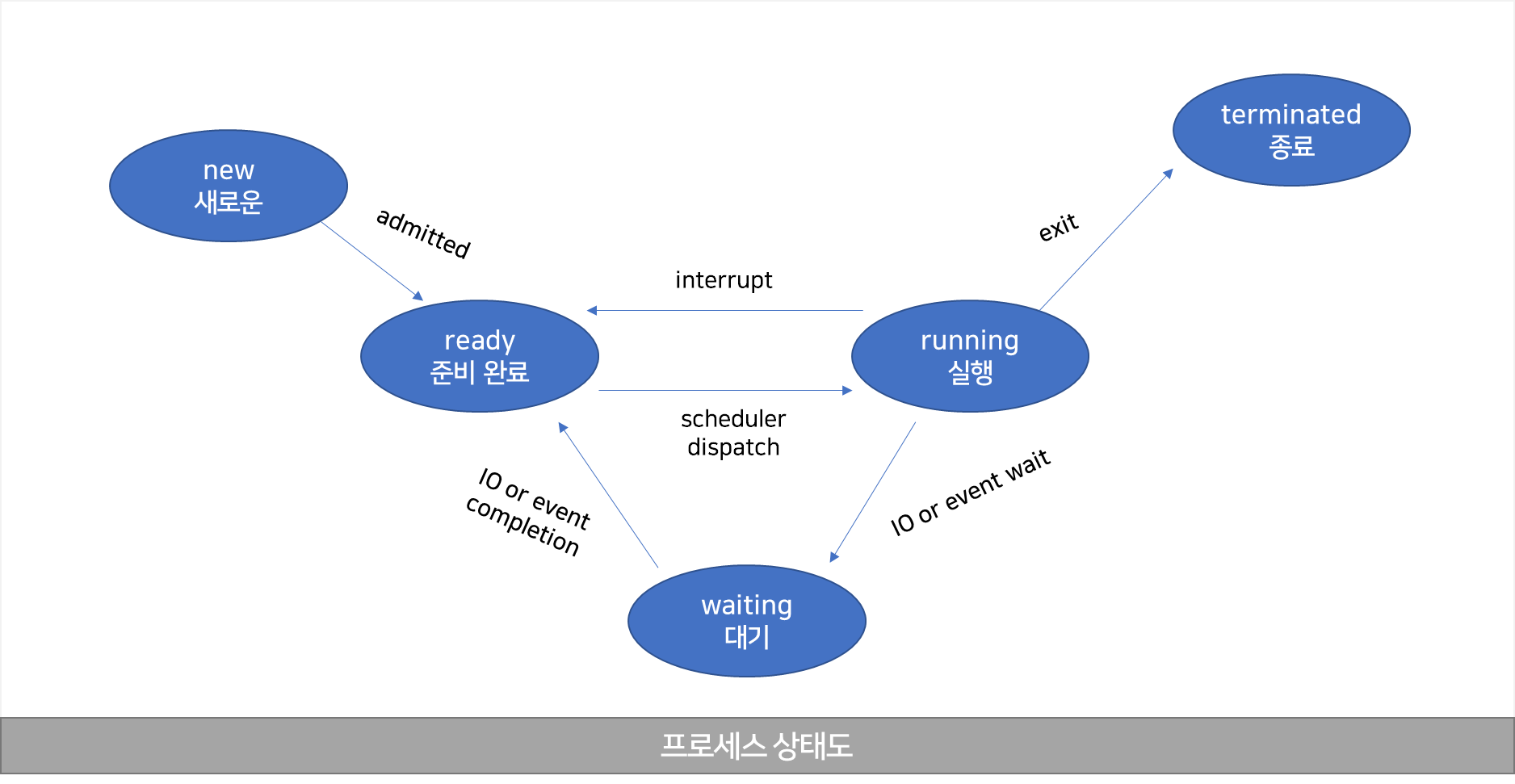
프로세스 상태
- new (새로운) : 프로세스 생성 중
- ready (준비 완료) : 프로세스가 처리기(CPU)에 할당되기를 기다림
- running (실행) : 명령어들이 실행되고 있음
- waiting (대기) : 프로세서가 어떤 사건(입출력 완료 || 신호의 수신)이 일어나기를 기다림
- terminated (종료) : 프로세스 실행 종료
PCB (Process Control Block, 프로세스 제어 블록)
PCB 구성 요소
- 프로세스 상태, 번호
- 프로그램 카운터
- CPU 레지스터들
- CPU 스케줄링 정보 : 우선 순위, 스케줄링 큐 포인터
- 메모리 관리 정보 : 프로세스에 할당된 메모리
- 회계(accounting) 정보 : CPU 사용량, 경과시간
- 입/출력 상태 정보 : 프로세스에 할당된 입출

프로세스 간 CPU 스위치 (context change, 문맥 교환)
- 프로세스1의 진행되는 동안 프로세스2를 호출할 때, 인터럽트 및 시스템콜 후 PCB1의 상태 저장
- PCB2의 상태 불러오고, 프로세스2 수행 후 다시 PCB2 상태 저장
- 프로세스1로 복귀

🧩스레드
스레드 개요
- CPU 이용의 기본 단위
- 스레드 ID, 프로그램 카운터, 레지스터 집합, 스택으로 구성
- 같은 프로세스에 속한 다른 스레드의 코드, 데이터 섹션, 열린 파일이나 신호와 같은 운영체제 자원들을 공유
- 프로세스 생성보다 가볍게 스레드 생성 : 코드 산소화 및 효율 증가
- 일반적으로 커널은 멀티스레드로 동작
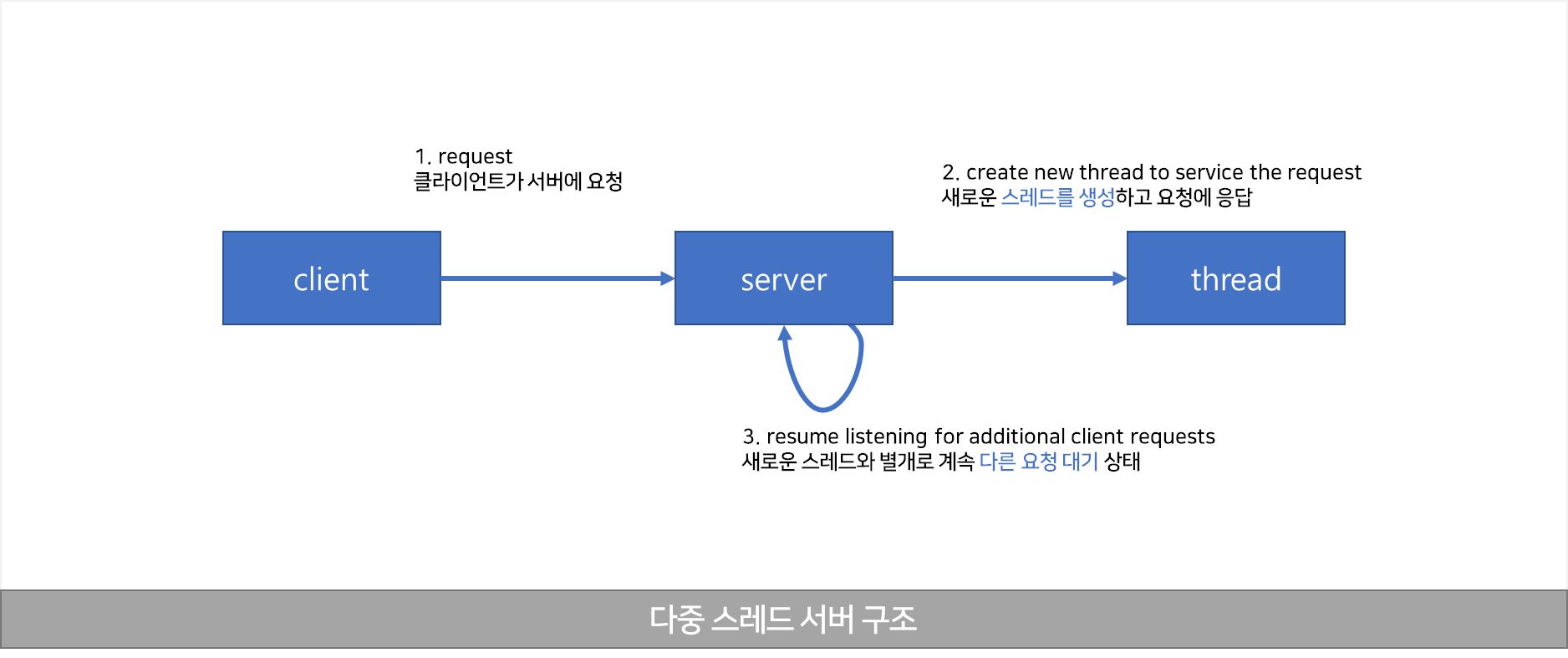
다중 스레드 서버 구조
- 클라이언트가 서버에 요청
- 새로운 스레드를 생성하여 요청에 상응하는 서비스 제공
- 다시 다른 클라이언트 요청을 위해 수신 대기
다중 스레드와 다중 스레드 프로세스
코드, 데이터, 파일은 공유하지만 레지스터 스택은 스레드간 공유x

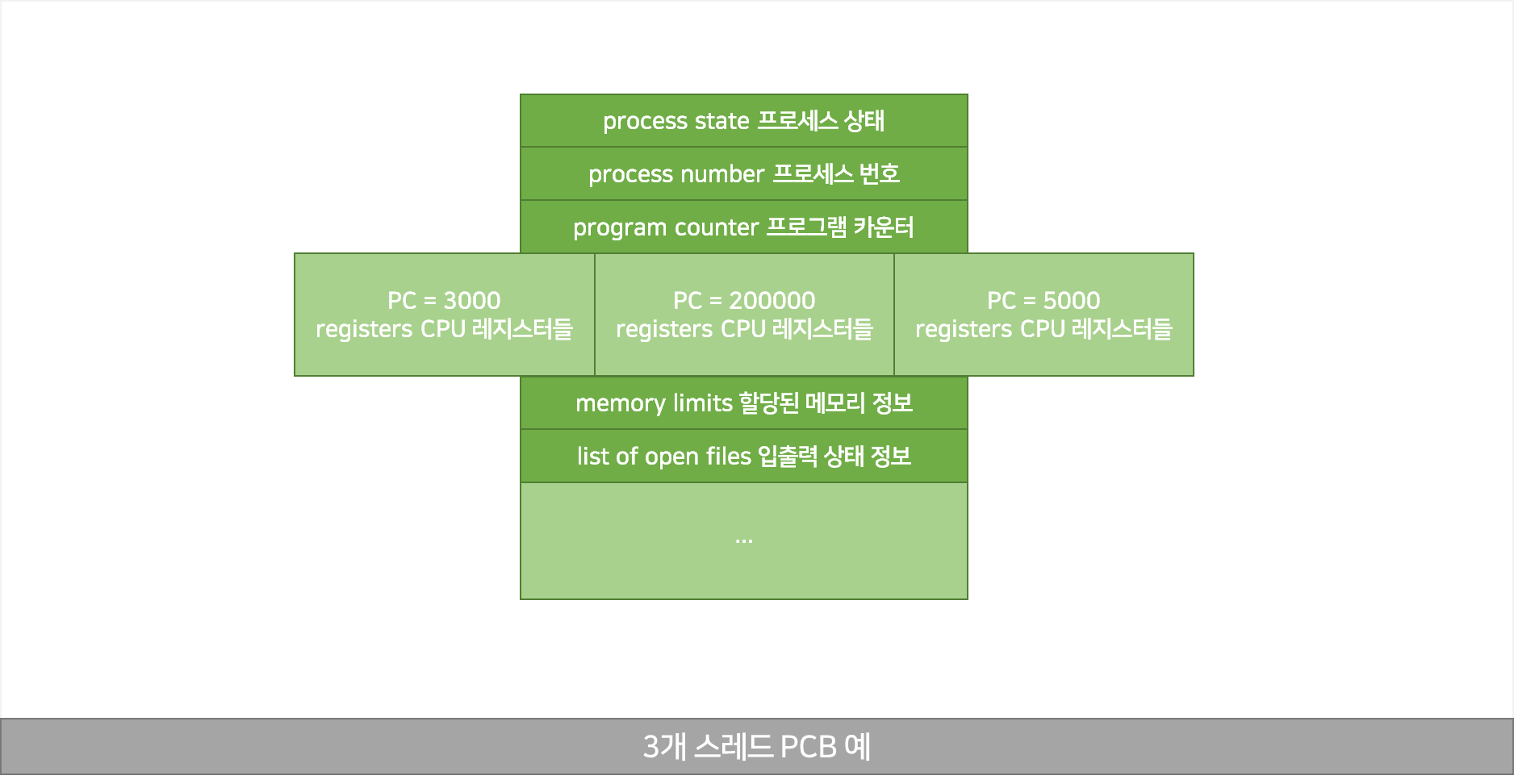
한 프로세스 - 3개 스레드 PCB 예
PCB 하나에 PC 및 레지스터는 3개가 병렬로 존재
다중 스레드 장점
- 응답성 : 다른 일부분이 중단되거나 긴 작업이 수행되어도 다른 부분 수행 허용하기 때문에 사용자에 대한 응답성 증가
- 자원 공유 : 한 응용 프로그램이 같은 주소 공간의 다른 스레드와 메모리 공유
- 경제성 : 스레드 생성과 문맥교환 오버헤드가 프로세스 보다 적음
- 규모 적응성 : 다중처리기 구조(multiprocessor architectures)에서 각각의 스레드가 처리기(CPU)에서 병렬(Parallelisim)로 수행
- (그럼 다중처리기구조가 아니면 멀티 스레드 불가인가? 놉놉 단일 코어에서는 병행적으로 실행, 스케줄링!)
다중 코어 프로그래밍
다중 코어 시스템에서 프로그래밍을 할 때 고려해야하는 과제
- 태스크 인식 : 응용을 분석하여 독립된 병행 태스크로 분리
- 균형 : 전체 태스크들이 전체 작업에 균등한 기여도를 갖는 것이 중요
- 데이터 분리 : 데이터도 개별 코아에서 사용할 수 있도록 분리
- 데이터 종속성 : 둘 이상의 태스크가 동시에 접근하는 데이터 종속 여부 검토하고 종속적이면 동기화 처리
- 시험 및 디버깅 : 병렬로 실행되는 다양한 실행 경로로 인해 프로그램 시험과 디버깅이 어려움
- 병행성과 병렬성(Concurrency and Parallelism)

- 데이터 병렬 실행
- 동일한 데이터의 부분집합을 다 수의 계산 코어에 분배
- 각 코어에서 동일한 연산 수행
- 태스크 병렬 실행
- 데이터가 아닌 태스크를 다수의 코어에 분배
- 각 코어의 스레드는 각각 고유 연산을 수행
- 스레드 수가 커지면서 하드웨어 아키텍처가 스레드 지원
다중 스레드 모델
사용자 스레드와 커널 스레드와의 연관관계
다대일 모델
사용자 수준 스레드 N → 1 커널 스레드
- 한 스레드가 봉쇄형 시스템 호출을 할 경우, 전체 프로세스가 봉쇄
- 다중 스레드가 다중 처리기에서 병렬로 작동
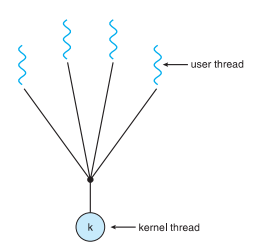
일대일 모델
사용자 스레드 1 → 1 커널 스레드
- 하나가 봉쇄적이라도, 다른 스레드 실행 가능
- 다중 처리기에서 다중 스레드가 병렬로 수행되는 것을 허용
- 커널 스레드 생성해야 하는 오버헤드로 응용 프로그램의 성능 저하
- Windows, Linux, Solaris 9
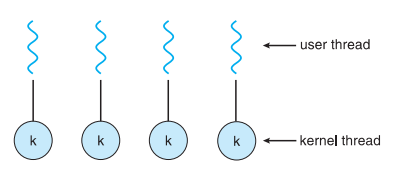
다대다 모델
사용자 스레드 N → N 커널 스레드
- OS가 필요한 만큼 커널 스레드 생성 허용
- Solaris 9 이전 버전
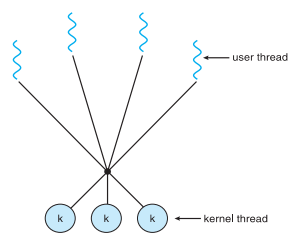
두 수준 모델
다대다 모델과 비슷하며, 하나의 사용자 스레드가 하나의 커널 스레드에 종속되는 것을 허용

🦴참고
Operating System Concepts, 10th Ed.

210's Velog :: Ambition Makes Us Diligent