시계열 분야의 foundation model은 어떤 데이터셋으로 model을 pre-train했는지를 기준으로 나눌 수 있다.
1. LLM pre-trained model : 시계열이 아닌 데이터로 학습이 된 모델을 시계열 데이터에 맞게 fine-tuning하는 모델. (Time-LLM, LLM4TS, GPT2, UniTime, TEMPO)
2. TS pre-trained model : 시계열 데이터로부터 학습한 모델.
이번 시리즈 포스팅에서는 2번째 케이스에 대한 3가지 모델을 간단하게 비교한다.
Motivation and Contribution
1. TimeGPT
- The first time-series forecasting foundation model.
- Reduce uncertainty
- TimeGPT zero-shot inference excels in performance, efficiency, and simplicity.
- TimesFM
- Train real-world dataset and synthetic dataset
- Pertaining a decoder style attention with input patching
- TimesFM zero-shot forecasts across different domains, forecasting horizons.
- Lag-Llama
- Foundation model for univariate probabilistic time-series forecasting
- Strong zero-shot generalization capabilities
- Strong few-shot adaptation performance of Lag-Llama
Architecture
1. TimeGPT
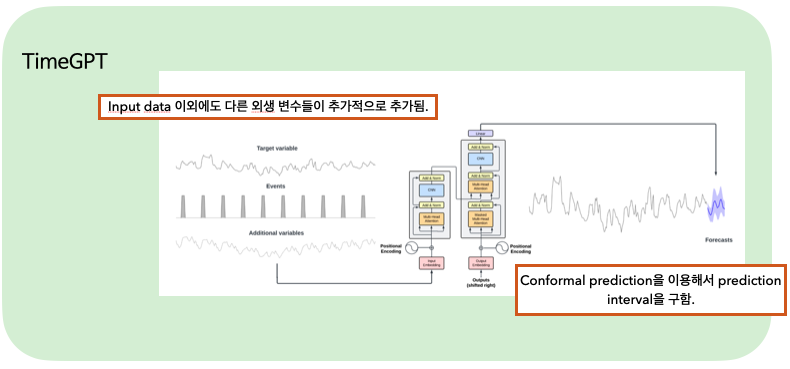
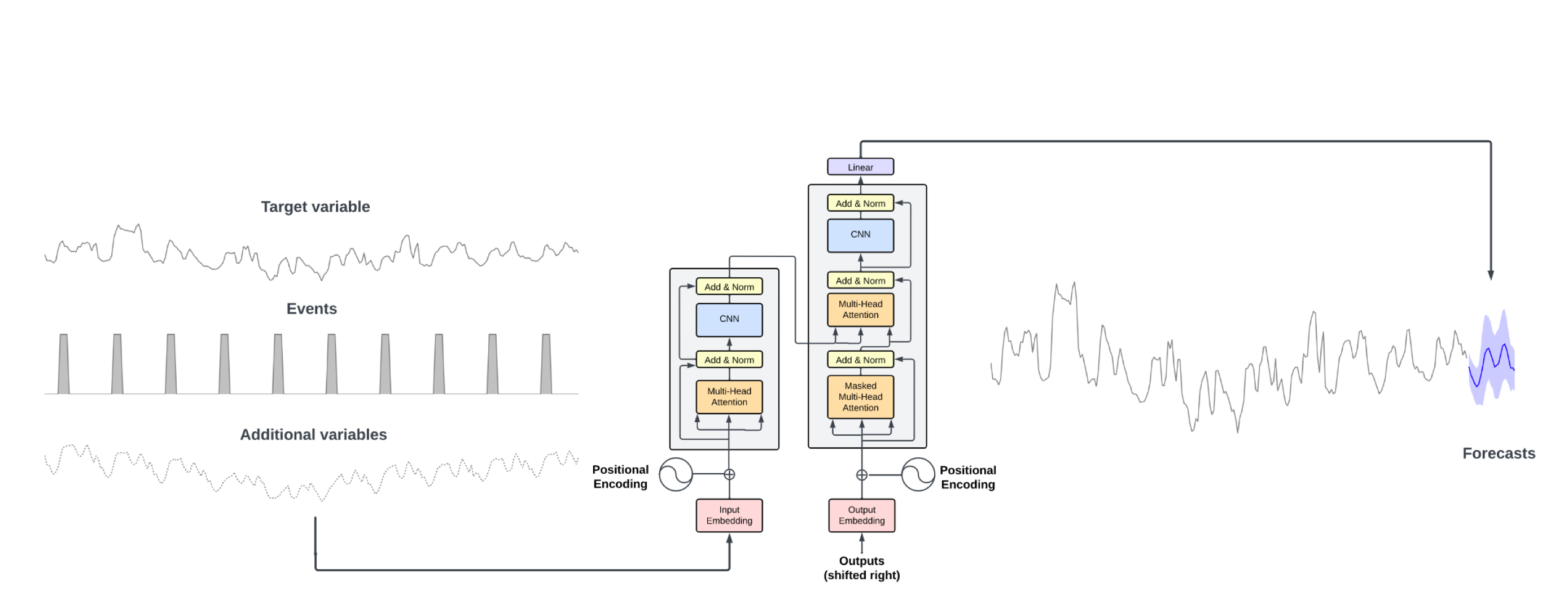
- Transformer-based time series model with self-attention mechanism.
- Input = target variables, exogenous variables
- Rely on conformal predictions based on historic errors to estimate prediction intervals.
- TimesFM
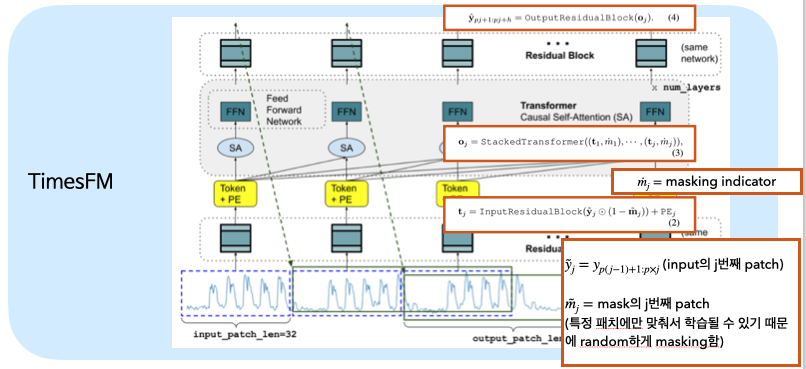
- MLP Token + PE Decoder-only model MLP
- Input = Patched data
- Decoder only based model (similar to LLM)
- Lag-Llama
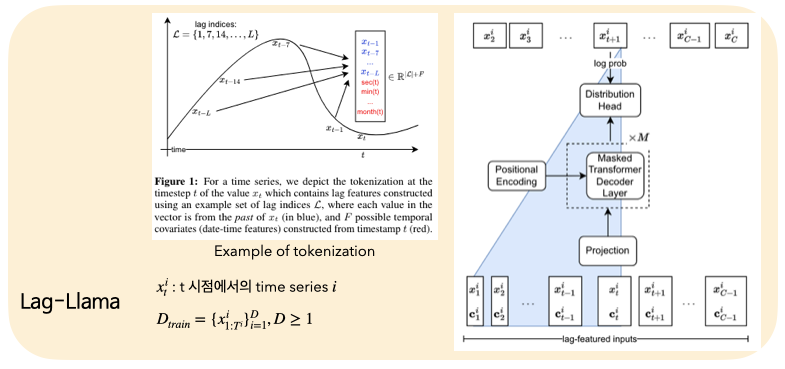
- MLP M-decoder layers Distribution head
- Lag-Llama incorporates pre-normalization via RMSNorm, Rotary Positional Encoding (As in LLaMA architecture) - Input = lag-featured inputs (token of a univariate time series, additional covariates (시차 정보 포함) )
- Distribution head : student’s t-distribution (Future work for distribution heads) wants to stay simple architecture
Foundation model for time-series
- TimeGPT
- = forecast horizon, = target time series, = exogenous covariates.
- TimesFM
- = forecast horizon, = target time series, = input window size
- Lag-Llama
- = forecast horizon, = target time series, = time lag as covariates, = context window
- C+1부터인 이유 : input 시계열의 전부를 보기 보다는, fixed context windows만 봄.
Training method
- TimeGPT
- Train to minimize forecasting error
- Conformal prediction을 이용해서는 불확실성만 측정함.
- TimesFM
- Train loss =
- For probabilistic forecasting, 각 output patch에 대해 여러 출력 헤드를 가질 수 있으며, 각 헤드는 별도의 quantile loss를 최소화할 수 있습니다.
- Lag-Llama
- Train to minimize the negative log-likelihood of the predicted distribution of all predicted timesteps.
- Self-supervised learning
Training dataset
- TimeGPT
- 100 billion data points
- Finance, economics, demographics, healthcare, weather, IoT sensor, energy, web traffic, sales, transport and banking
- TimesFM
- Real world data (40%) + synthetic data (60%)
- 각 데이터셋(real world) 마다 약 1 billion 부터 100 billion까지의 data point들로 이루어져있음.
- Lag-Llama
- 6개의 분야로부터 구한 27개의 시계열 데이터 셋
- 352 million data windows(tokens)

SheoYon.Jhin