ModernTCN: A Modern Pure Convolution Structure for General Time Series Analysis
Paper Reading
이 논문은 현재 ICLR 2024에서 under review받는 논문이며, openreview 홈페이지에서 볼 수 있습니다!
시계열 분석 분야에서 transformer-based models들과 MLP-based models들이 지배적이다. convolution을 시계열 분석에서 어떻게 사용하는 것이 좋을지 에 대한 문제를 다룬다.
- Traditional TCN을 현대화하고 시계열 작업에 더 적합하도록한다.
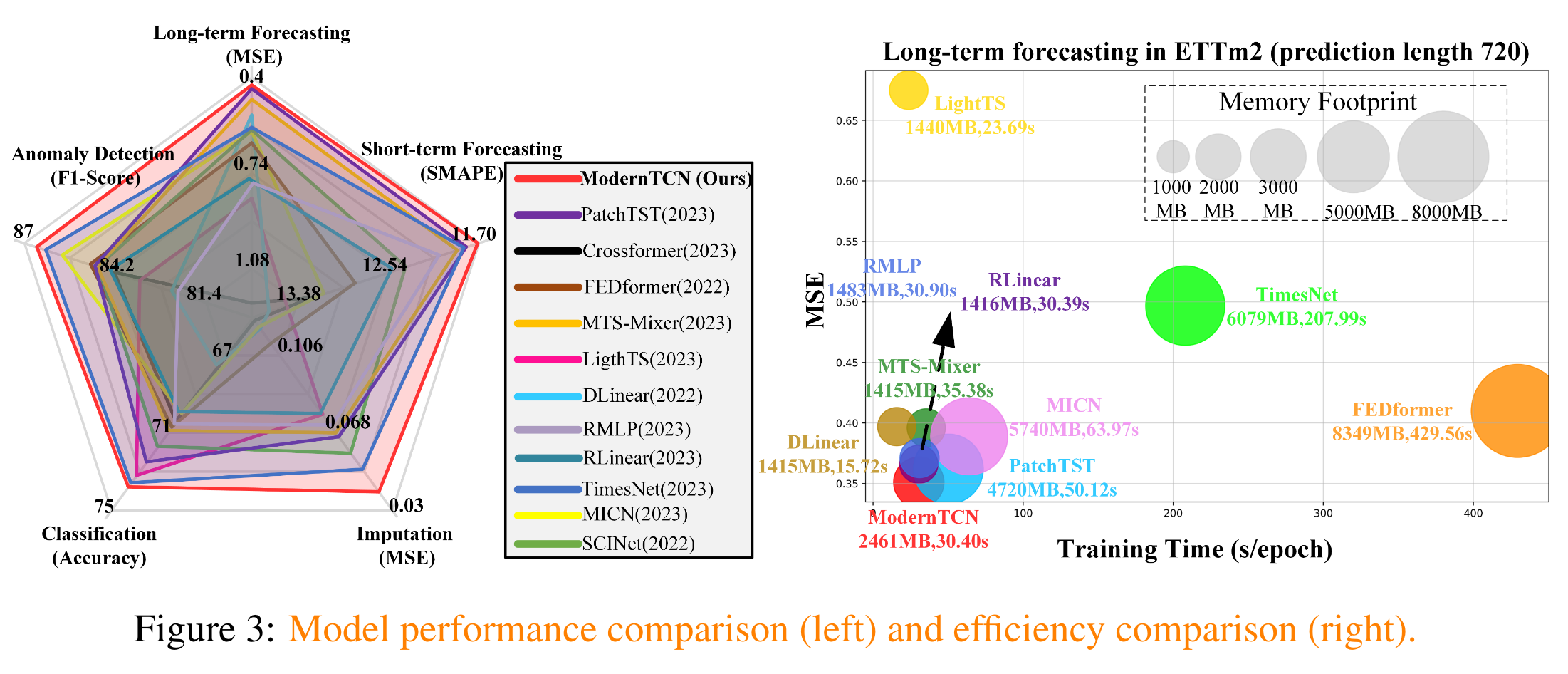
- ModernTCN은 LTSF, STSF, Imputation, Classification , Anomaly detection에서 transformer-based / MLP-based 모델들보다 균형적이고 우수한 성능을 보여준다.
- 어떻게 ModernTCN을 설계했는지가 관건
- 기존의 convolution-based model들과 비교했을때, Effective Receptive Fields 가 크기떄문에 시계열에서의 convolution의 잠재력을 더 보여줄 수 있었다.
- Effective Receptive Fields?
- Receptie field 는 수용 필드 크기로 neural network가 볼 수 있는 정보를 말한다. 즉, 고려할 수 있는 컨텍스트의 양을 결정하는 것. 즉, receptive field가 크면 더 많은 부분을 볼 수 있고, 더 크고 전역적인 특징에 민감하다.
- Effective Receptive Fields?
Cross-time / Cross-variable dependency 을 효율적으로 활용하기 위해서 convolution 구조를 적용한 것이라고 볼 수 있다.
<A convnet for the 2020s> → 이 논문의 아이디어를 따라서 1D convolution block을 오른쪽 그림과 같이 새롭게 디자인한다.
→ DWConv는 변수 별로token간의 temporal information을 학습하는 역할이며, Transformer의 self-attention과 동일한 역할을 한다.
→ ConvFFN는 Transformer의 Feed-Forward Network의 역할을 한다.
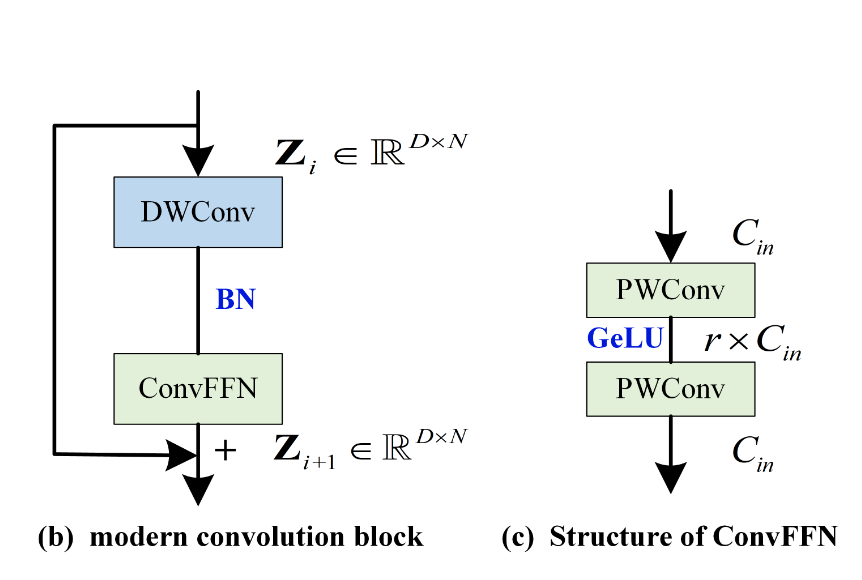
ConvFFN은 두개의 PWConv로 이루어져있다.
구조를 보면, 역병목 구조(1 → r → 1 )를 보여줌
새로운 feature representation을 독립적으로 학습하는 것.
위의 두 구조는 temporal / feature information을 혼합해서 학습한다는 점이 기존의 Convolution-based model들과의 차이점이다. → convloution-based model의 현대화한 포인트!
하지만, 기존 CV의 convolution의 아이디어를 이용해서 현대화한 것이 성능향상을 보여주진 않았다.
위의 설계는 단순히 CV의 아이디어를 빌려온 것 뿐 시계열의 특성을 고려한 것이 아니다.feature dimension과 temporal dimention외에도 시계열에는 variable dimension이 존재한다.
→ Variable dimension?
variable이 의미하는 바가 batch인 것 같다.
기존의 embedding 디자인은 variable dimension을 무시하도록 하기 떄문에 cross-variable dependency 학습이 불가능하다. 그래서 patchify variable-independent embedding을 제안한다.
TimesNet vs ModernTCN
TimesNet : 1d 시계열 데이터를 2D 시계열 데이터로 바꾸는 것이 핵심이다.
ModernTCN : 1d 그 자체로 시계열을 위한 convolution을 제안. + memory cost측면에서도 더 좋다.