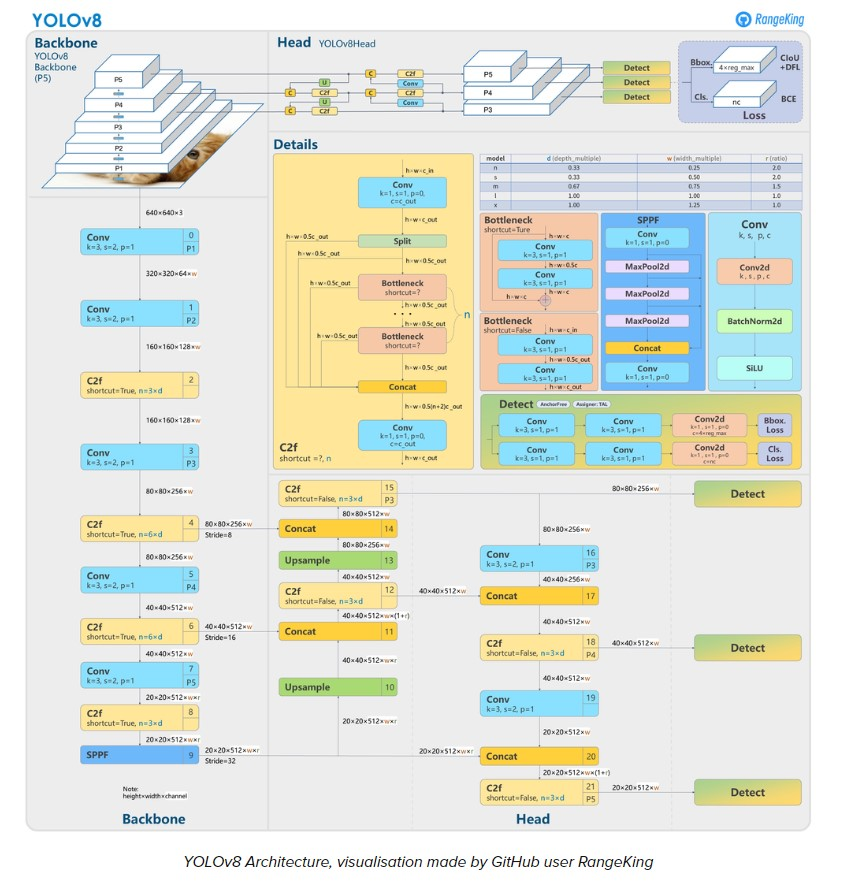
다시 yolov8의 architecture가 어떻게 구성되어 있는지 공부해보려 한다.
yolo는 backbone과 head로 구성되어 있으며, backbone에서는 input 데이터의 feature들을 추출하고, head에서 추출한 feature를 이용하여 classification 혹은 detection 등 여러 task를 진행하게 된다. 다른 DNN 기반 혹은 다른 모델 프레임워크는 head에서 fully connected layer를 이용하게 되는데 이 YOLOv8에서는 head에서도 convolution layer를 이용한다. 이 부분은 코드를 통해 더 공부해야할 부분이다.
nn > block.py
block.py 부분이다. 여기서는 YOLOv8을 구성하는 블락을 함수 클래스로 정의하고 있다. 예를 들어 C2f, SPPF, BottleNeck, v8뿐만 아니라 다른 YOLO 버전에서 사용된 c1, c2 , c3 등이 있다.
간단하게 설명하자면, c 뒤에 붙어있는 숫자는 block을 구성하는 convolution layer의 수이다. 예를 들어, C2F는 convolution layer가 2개로 구성된 블락이라는 뜻이다. bottleneck 은 2개의 convolution layer로 구성되어 있는데 다른 블락과 구분되는 점은 bottleneck에서는 convolution layer를 통과하기 전 초기 input값과 convolution layer을 통과한 outputs 값을 concat하는 과정을 거치는데 이는 convolution layer를 통과하면 input 값의 데이터 손실이 발생할 우려를 보완하기 위해 이와 같은 과정을 거친다.
nn > conv.py
다음을 block을 구성하는 convolution layer이다.
class Conv(nn.Module): #convolution layer정의
"""Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)."""
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
"""Initialize Conv layer with given arguments including activation."""
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False) #convolution layer
self.bn = nn.BatchNorm2d(c2) #batch normalization
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
"""Apply convolution, batch normalization and activation to input tensor."""
return self.act(self.bn(self.conv(x))) #convolution layer -> batch normalization -> activation function (siLU)
#siLU ?
def forward_fuse(self, x):
"""Perform transposed convolution of 2D data."""
return self.act(self.conv(x))convolution layer가 forward 함수를 통해 실행될 경우, 먼저 convolution layer를 거친 후, 배치 정규화를 진행한다. 그 후 activation function인 SiLU를 이용한다. SiLU는 ReLU의 변형 형태의 활성화 함수이다.
nn > head.py
head는 feature를 추출한 후, task를 수행하는 부분이다. YOLOv8에서 정의한 task는 총 4가지로, 그 중에서도 detect task 코드만을 살펴보도록 하겠다.
class Detect(nn.Module):
"""YOLOv8 Detect head for detection models."""
dynamic = False # force grid reconstruction
export = False # export mode
shape = None
anchors = torch.empty(0) # init
strides = torch.empty(0) # init
def __init__(self, nc=80, ch=()): # detection layer
super().__init__()
self.nc = nc # number of classes
self.nl = len(ch) # number of detection layers
self.reg_max = 16 # DFL channels (ch[0] // 16 to scale 4/8/12/16/20 for n/s/m/l/x)
self.no = nc + self.reg_max * 4 # number of outputs per anchor
self.stride = torch.zeros(self.nl) # strides computed during build
c2, c3 = max((16, ch[0] // 4, self.reg_max * 4)), max(ch[0], self.nc) # channels
self.cv2 = nn.ModuleList(
nn.Sequential(Conv(x, c2, 3), Conv(c2, c2, 3), nn.Conv2d(c2, 4 * self.reg_max, 1)) for x in ch)
self.cv3 = nn.ModuleList(nn.Sequential(Conv(x, c3, 3), Conv(c3, c3, 3), nn.Conv2d(c3, self.nc, 1)) for x in ch)
self.dfl = DFL(self.reg_max) if self.reg_max > 1 else nn.Identity()
def forward(self, x):
"""Concatenates and returns predicted bounding boxes and class probabilities."""
shape = x[0].shape # BCHW
for i in range(self.nl):
x[i] = torch.cat((self.cv2[i](x[i]), self.cv3[i](x[i])), 1)
if self.training:
return x
elif self.dynamic or self.shape != shape:
self.anchors, self.strides = (x.transpose(0, 1) for x in make_anchors(x, self.stride, 0.5))
self.shape = shape
x_cat = torch.cat([xi.view(shape[0], self.no, -1) for xi in x], 2)
if self.export and self.format in ('saved_model', 'pb', 'tflite', 'edgetpu', 'tfjs'): # avoid TF FlexSplitV ops
box = x_cat[:, :self.reg_max * 4]
cls = x_cat[:, self.reg_max * 4:]
else:
box, cls = x_cat.split((self.reg_max * 4, self.nc), 1)
dbox = dist2bbox(self.dfl(box), self.anchors.unsqueeze(0), xywh=True, dim=1) * self.strides
y = torch.cat((dbox, cls.sigmoid()), 1)
return y if self.export else (y, x)
def bias_init(self):
"""Initialize Detect() biases, WARNING: requires stride availability."""
m = self # self.model[-1] # Detect() module
# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1
# ncf = math.log(0.6 / (m.nc - 0.999999)) if cf is None else torch.log(cf / cf.sum()) # nominal class frequency
for a, b, s in zip(m.cv2, m.cv3, m.stride): # from
a[-1].bias.data[:] = 1.0 # box
b[-1].bias.data[:m.nc] = math.log(5 / m.nc / (640 / s) ** 2) # cls (.01 objects, 80 classes, 640 img)init 함수에서 클래스 확률 및 bounding box 예측을 위해 필요한 변수 초기화를 진행한 후, head에서도 convolution layer를 사용하기 때문에 이 역시 정의한다. detect는 두가지 sequential한 과정이 병렬적으로 진행된다. bounding box loss 계산 및 class loss 계산을 convolution layer2개, convolution2D layer 1개를 거쳐 계산하게 된다.forward 함수에서 if-else문을 보면 box, cls를 구하게 되는데, 이는 다시 dfl이라는 손실 함수에 값을 전달하여 loss값을 구하게 된다.
이제 대충은 어떠한 과정으로 YOLO detection 과정이 진행되는지는 알 수 있지만, YOLO architecture가 워낙 복잡한지라 이해하는데 많은 시간이 걸릴 것 같다. 그래도 지금 조금이라도 공부해두면 나중에 다시 사용해볼 때는 지금보다는 더 많이 이해할 수 있을 거라 믿는다..
