안녕하세요!
오늘도 방끗 ☺️ 프로젝트를 진행하며 만난 문제와 해결 과정을 갖고 와 보았습니다
그러나 제목에 Help... 를 통해 혹시나 글을 보시는 분께 SOS를 곁들여 봅니다
지금부터 저의 8시간 구현 여정을 함께 가 봅시다 👊
아티클에 조회수를 넣으시오!
새로운 기능을 조금씩 구현하며 사용자 유치에 집중하던 그때,
홍보 방식뿐만 아니라 서비스적으로도 사용자 유치에 효과적인 방안을 모색 중이었어요
저희의 서비스는 지극히 개인화되어 있는 서비스라 하나의 유저가 다른 유저를 인식하지는 못하는 구조예요
하지만!
가시적으로 사용자가 있음을 보여주어 우리 유저 이렇게 많다~ 그리고 이 아티클 진짜 인기 많다~ 를 보여 주기 위해 조회수를 도입하기로 했어요
아주 간단한 필드 하나 추가, 증가 코드 한 줄 작성... 정도가 되리라 예측했어요
다른 크루가 해당 기능을 맡아 구현하다가 갑자기 연락이 옵니다
👨: 시소~ 저번에 캐시 도입했었지? 캐시가 있어서 조회수가 업데이트가 안 되네 DB에만 반영되고 있어 시간 관계상 다른 방안을 도입하진 못하겠어서... 캐시를 떼야 될 것 같은데?
🎡: 뭐? 하지만 아티클은 모든 유저에게 똑같이 보여주는 거라 매번 DB를 통하기 비효율적인 것 같은데 분명 방안이 있을 것 같아! 내가 해 볼게
이렇게... 제가 하게 되었습니다
조회수 어떻게 관리할래?
저는 조회수를 다른 곳에 저장해 두었다가 주기적으로 해당 데이터를 DB에 옮기는 방법을 생각해 보았습니다
두 가지 정도의 방안이 떠오르더라고요
1. 아티클 ID와 조회수를 Map 형태로 관리
이 방식은 로컬 메모리에 Map 형태로 아티클 ID와 조회수를 저장하는 구조입니다.
요청이 들어오면 Map에서 해당 아티클 ID의 값을 찾아 +1만 수행하면 되기 때문에 속도가 빠르고 간단합니다
추가적인 네트워크 호출이나 데이터 일관성 관리에 대한 부담이 없습니다
특히, 기존 코드의 변경이 거의 필요하지 않다는 점에서 도입하기가 매우 쉽습니다
그러나, 이 방식은 데이터가 서버의 로컬 메모리에 저장되기 때문에, 분산 서버 환경에서는 문제가 발생합니다
예를 들어, 여러 서버에서 동일한 데이터를 관리할 경우, 조회수의 일관성이 깨질 수 있으며, 서버가 재시작되면 데이터가 손실될 위험이 있습니다
따라서 단일 서버 환경이나 간단한 테스트/개발 환경에서 유용하지만, 확장성이나 안정성이 중요한 환경에서는 적합하지 않습니다
2. 캐시 데이터 자체를 수정하여 관리
이 방식은 외부 캐시를 활용하여 데이터를 변경하는 구조입니다
요청이 들어오면 캐시에 저장된 데이터를 읽어와 조회수를 증가시키고, 다시 캐시에 저장하는 작업을 수행합니다
이 방식은 데이터를 중앙화하여 관리하기 때문에, 분산 서버 환경에서도 데이터 일관성을 보장할 수 있습니다
예를 들어, 모든 서버가 동일한 캐시에 접근하기 때문에, 여러 서버에서 동시에 조회수가 증가해도 최종 결과가 정확히 반영됩니다
그러나, 이 방식을 도입하려면 캐시와 통신하는 로직을 추가해야 하므로 코드 수정 범위가 넓어질 가능성이 높습니다
또한, 캐시 서버의 부하, 네트워크 지연, 캐시 만료 정책 등 운영 중 추가적으로 고려해야 할 요소가 많아집니다
따라서 도입 코스트가 높은 편이지만, 대규모 트래픽이나 분산 서버 환경에서는 안정성과 확장성 측면에서 더 적합합니다
결론적으로
저는 2번 방안을 선택하였습니다
기존에 분산 서버 환경을 도입한 경험이 있어, 해당 상황을 고려할 필요가 있었습니다
또한, 조회수를 관리하는 데이터가 Map으로 분산될 경우, 관리 포인트가 증가하여 유지보수가 어려워질 우려가 있었습니다
Layer... 분리해야지?
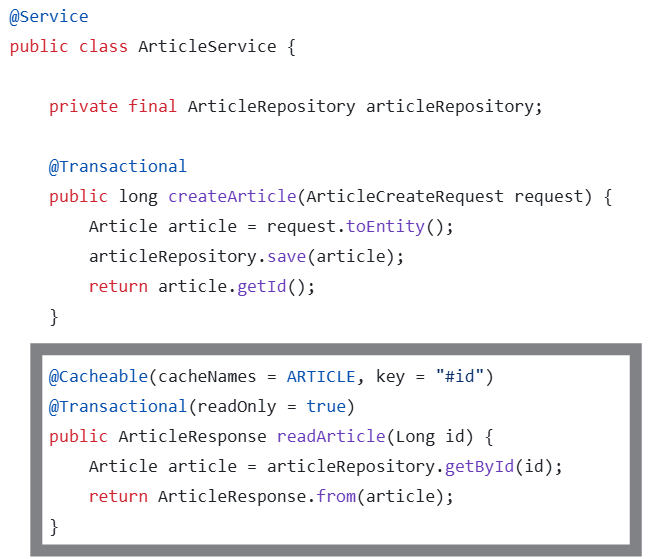
기존 코드에는 다음과 같은 구조가 적용되어 있습니다
@Cacheable 어노테이션은 함수 실행이 종료될 때 결과를 캐시에 저장하며, 이후 동일한 입력값으로 함수가 호출되면 AOP를 통해 캐시된 값을 반환합니다
즉, 해당 함수는 캐시가 비어 있을 경우 처음 한 번만 실행되고, 이후에는 캐시 데이터가 삭제될 때까지 실행되지 않습니다
ArticleReponse에서 조회수 값 수정?
현재 코드에서는 ArticleResponse 객체가 캐시 데이터로 저장되고 있습니다
이와 같은 구조에서 조회수 증가를 캐시에 반영하려면 ArticleResponse 객체의 값을 수정해야 합니다
하지만, DTO 객체인 Response의 값을 직접 수정하는 것은 비즈니스 로직이 DTO로 침투하는 상황으로 적절하지 않다고 판단했습니다
Repository에서 캐시?
그렇다면 현재 도메인은 Repository가 반환하고 있으니 Repository를 캐시해야 할까요?
하지만, 캐시 로직을 Repository에 추가하는 것도 적합하지 않았습니다
- Repository는 데이터베이스와의 상호작용을 책임지는 역할에 집중해야 하며, 캐시 관리까지 맡게 되면 역할이 모호해집니다
- 트랜잭션이 완료되지 않은 데이터를 캐싱할 경우, 데이터의 일관성이 깨질 우려도 있습니다
일반적으로 캐시는 비즈니스 로직을 처리하는 Service 레이어에 적용하는 것이 가장 적합하기 때문에, Repository에 캐싱 로직을 추가하는 방식은 권장되지 않습니다
이러한 이유로, 캐시 로직을 관리할 별도의 Service를 분리하는 것이 더 적합하다고 판단했습니다
ArticleManageService의 도입
새로운 구조에서는 ArticleService와는 별도로 조회수 증가 및 캐시 관리 기능을 담당하는 ArticleViewService를 추가하였습니다
이는 기존의 ArticleService가 본래 맡고 있던 비즈니스 로직에 영향을 주지 않으면서, 캐시에 관한 부분만 별도로 관리할 필요성이 있다고 판단했기 때문이에요
또한, 이 두 Service를 통합적으로 관리하는 ArticleManageService를 도입하여, 역할과 책임을 분리하고 코드의 가독성과 유지보수성을 높였습니다
결론적으로, Service 레이어를 분리하여 ArticleService와 ArticleViewService를 각각의 역할에 맞게 설계한 구조로 개선하였습니다
캐시 값 변경을 구현해 보자
드디어 정책적인 부분 고려가 끝나고 구현에 들어왔습니다
사실 전 위의 시행착오를 겪는 동안 그것을 모두 구현해 보아서 실제로 더 오랜 시간이 걸렸습니다
-
ArticleManageService에서 readArticle 요청을 받으면

-
ArticleService에서 Repository로 데이터를 조회한 뒤 캐시합니다
이 과정에서 이미 캐시된 데이터가 있으면 해당 함수는 실행되지 않습니다
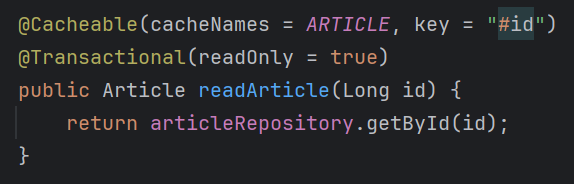
-
그 후 ArticleViewService에서 캐시된 데이터를 조회해 값을 증가시키고 다시 저장합니다

주기적으로 DB에 반영해야지
조회수 값을 캐싱에 성공하였어요
테스트도 아주 잘 돌아갑니다 👍
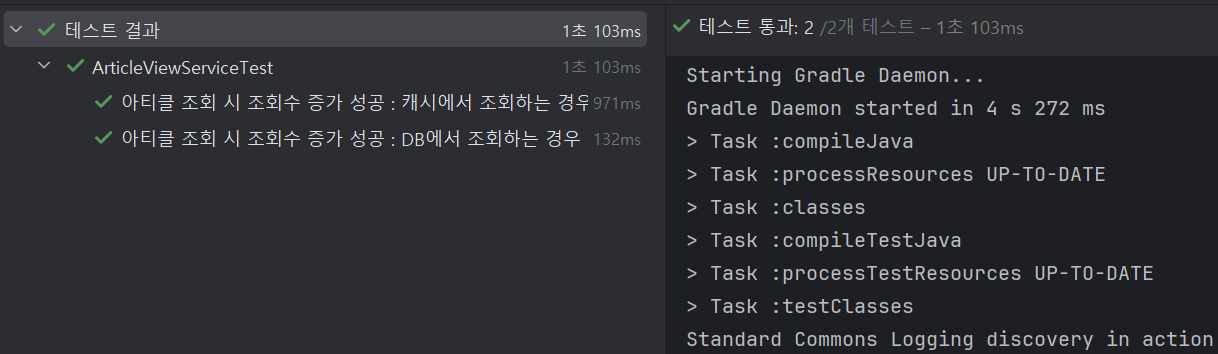
이제 주기적으로 캐시에 있는 모든 값을 DB에 반영할 차례입니다
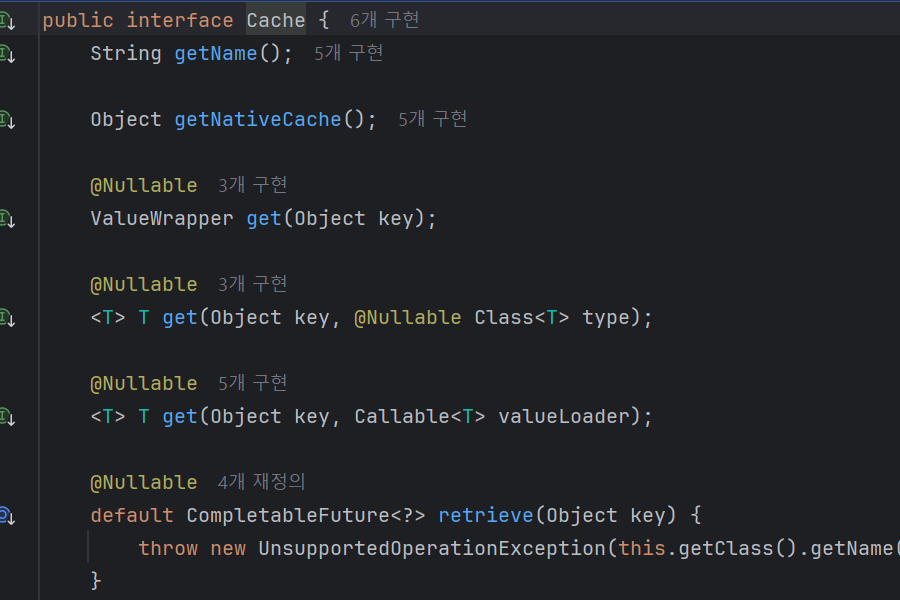
그러나 눈을 씻고 찾아 봐도 보이지 않는 모든 데이터 조회 😲
key가 있어야만 값을 가져오는 것이 가능하고, 존재하는 모든 key를 조회한다든가 모든 value를 조회하는 API가 아예 존재하지 않더라고요
이럴 수가 나는 어떡하라고
따라서 ArticleViewService에
private final Set<Long> cacheArticleIds = new HashSet<>(); 변수를 추가하여 캐싱되어 있는 id들을 관리하는 집합을 두었습니다
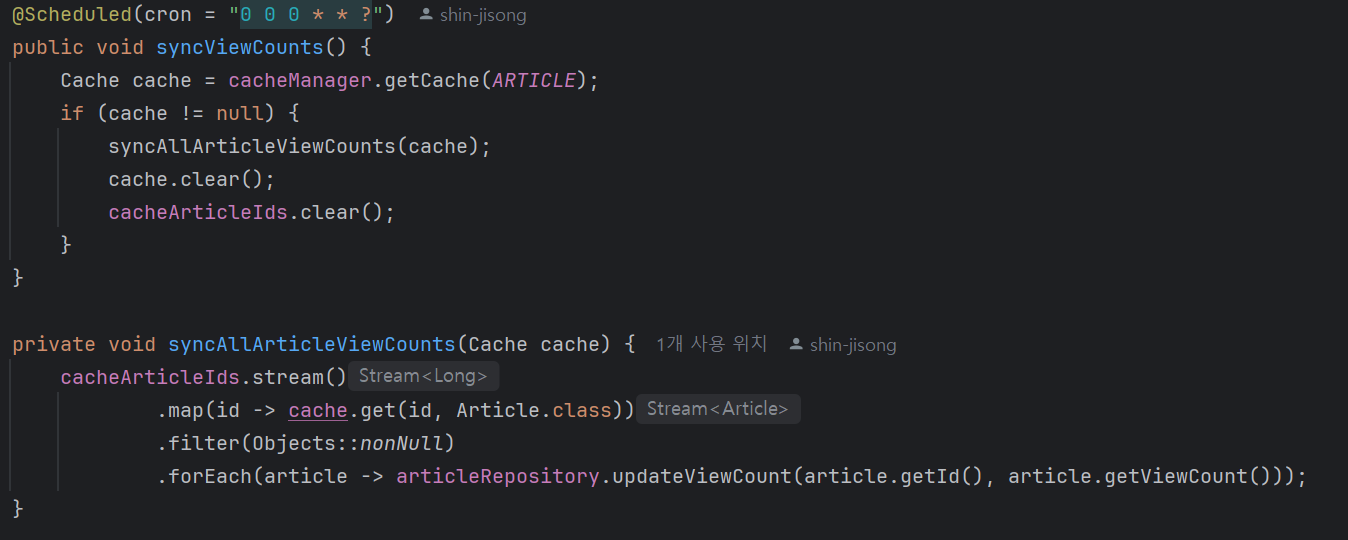
그리고 매일 자정마다 해당 집합을 조회에 DB로 데이터를 반영하는 로직을 작성해 주었습니다
이때, 자정으로 한 이유는 트래픽이 적은 시간대이며, 하루 단위로 조회수를 관리하기 용이하다는 점을 들 수 있습니다
해당 로직이 Service에 있어도 될까?
@Scheduled(cron = "0 0 0 * * ?") 함수가 Service에 위치해도 되는지에 대한 고민에서 다음과 같은 논리로 결론을 내렸습니다
-
동기화 로직을 비즈니스 로직에 명시
Service 계층에 해당 로직을 두면, 조회수 데이터를 매일 자정에 동기화한다는 의도를 명확하게 드러낼 수 있습니다
이는 비즈니스 로직에 포함되는 작업으로 간주할 수 있으며, 다른 개발자들이 해당 로직을 이해하고 유지보수하는 데 혼란을 줄일 수 있습니다 -
Repository와의 상호작용
해당 로직은 articleRepository를 사용하여 데이터를 업데이트합니다
Repository 계층은 데이터베이스와의 직접적인 상호작용을 담당하지만, 비즈니스 로직을 다루는 Service 계층에서 Repository를 호출하여 데이터 동기화를 처리하는 것은 자연스러운 설계입니다
따라서, 이 작업은 비즈니스 로직의 일환으로 볼 수 있습니다 -
책임 분리 원칙 준수
Service 계층은 비즈니스 로직을 구현하는 계층으로, 특정 주기에 실행되는 동기화 작업을 포함할 수 있습니다
Scheduler가 Repository에 직접 접근하지 않고, Service 계층에서 처리되도록 설계함으로써 책임의 분리와 코드의 가독성을 유지할 수 있습니다
결론적으로, @Scheduled 함수가 Service 계층에 위치하는 것은 협업, 설계 원칙과 비즈니스 로직의 역할을 고려했을 때 적합하다고 판단하였습니다
@Scheduled 로직을 테스트해 보자
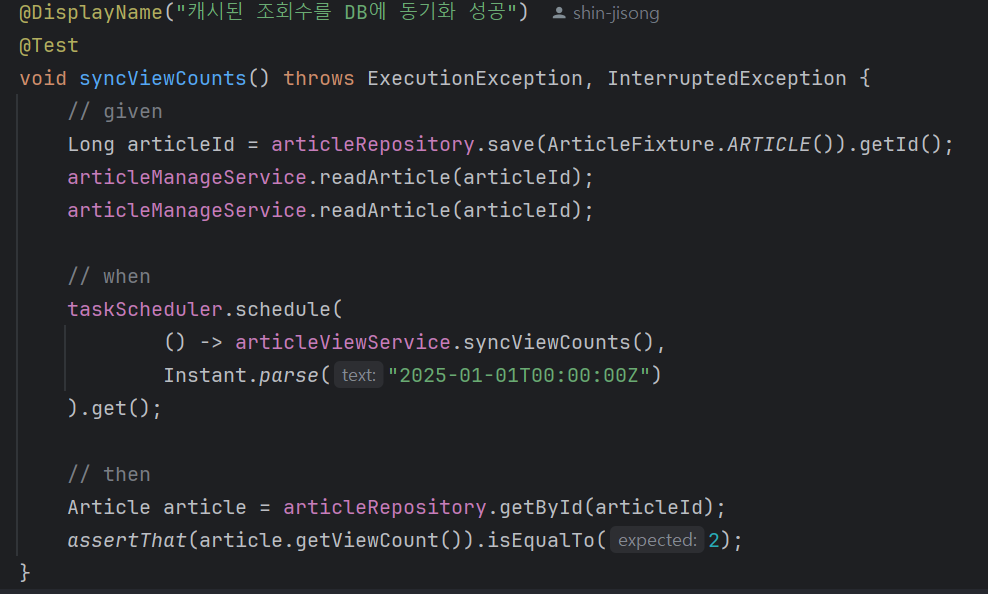
기존에는 단순히 함수 호출을 통해 테스트를 진행하며 @Scheduled를 적용하지 않았습니다
Spring이 구현한 영역이니 굳이 테스트를 안 해도 되는 부분이라 생각했기 때문이에요
하지만 스케줄링이 제대로 동작하는지까지 확인하고 싶어서 구글링을 통해 해결 방안을 찾았습니다
그 결과, taskScheduler를 활용하면 스케줄링 테스트가 가능하다는 것을 알게 되었고, 이를 활용하여 테스트를 완료했습니다
여전히 남은 고민
현재 상황에서는 아티클 리스트를 조회할 때는 Repository에서 데이터를 가져오고, 개별 아티클 조회 시에는 캐시를 활용하고 있습니다
문제는 조회수가 캐시에만 반영되며, 캐시 데이터가 매 정각마다 DB에 업데이트되기 때문에 리스트 조회 시점과 캐시 데이터 간의 조회수 불일치가 발생한다는 점입니다
이를 해결하기 위해 다음과 같은 방안을 고민해 보았습니다:
-
조회수만 별도로 조립
리스트를 조회할 때, 각 아티클의 조회수를 캐시에서 가져와 조립하는 방식입니다.
그러나 이 방식은 서버에서 처리해야 할 작업이 지나치게 많아지는 단점이 있습니다. -
리스트 조회 시 캐시를 갱신
리스트를 조회할 때마다 캐시 데이터를 DB와 동기화하여 최신 상태로 갱신하는 방식입니다.
그러나 이 방식은 캐시의 장점인 성능 향상을 활용할 수 없게 되어 캐시를 사용하는 의미가 사라집니다
이와 같은 상황에서는 캐시를 효율적으로 사용하는 것이 어려운 것일까? 캐시를 적용할 수는 없는 걸까? 하는 고민이 있어요
현재로서는 해결 방안이 명확하지 않아, 비슷한 경험이 있는 유경험자의 조언이 필요합니다 🥲
현재 아티클 리스트에는 조회수를 보여주지 않고 있지만 언젠가 보여줘야 하는 상황이 왔을 때에는 어떻게 하면 좋을지...
아 참 동시성도 언젠가는

아티클과 조회수를 떼어내면 어떨까요 ?????