그린워싱 탐지를 위한 RAG 성능 튜닝기
AI가 마케팅 문구를 읽고 "이건 그린워싱이다"라고 말할 수 있을까?
나는 이 질문에 답하기 위해, 한국 환경법 기준에 따라 그린워싱을 판단하는 RAG 시스템을 만들었다.
처음엔 단순히 언어모델만 잘 고르면 해결될 줄 알았다.
그런데 시스템을 만들다 보니, 검색 구조 자체가 성능에 큰 영향을 준다는 사실을 깨달았다.
❗문제가 된 건 '검색'이었다
내 시스템은 다음과 같은 문서를 기반으로 판단을 내린다.
- 가이드라인 문서: 어떤 표현이 그린워싱인지 설명하는 기준
- 법률 문서: 그 기준을 뒷받침하는 법적 조항
- 기사 본문: 실제 기업의 마케팅 문구
처음에는 관련 문서를 한꺼번에 넣으면 더 정확하지 않을까 생각했다.
하지만 실제로는 모델이 너무 많은 정보를 주면 오히려 핵심을 놓치는 현상이 있었다.
🧠 왜 이런 문제가 생겼을까?
이때 접하게 된 개념이 바로 Lost in the Middle이었다.
2023년 발표된 연구에 따르면,
LLM은 긴 입력에서 앞부분과 뒷부분은 잘 반영하지만, 중간에 위치한 정보는 놓치는 경향이 있다.
즉, 아무리 중요한 문서라도 프롬프트 중간에 들어가 버리면
모델은 그걸 무시한 채 판단을 내릴 수 있다.
🔁 그래서 Reranker를 도입했다
Reranker는 검색된 문서들의 순서를 다시 정렬해주는 구성 요소다.
단순히 유사한 문서를 가져오는 것을 넘어, LLM이 먼저 읽어야 할 핵심 문서를 앞에 두도록 한다.
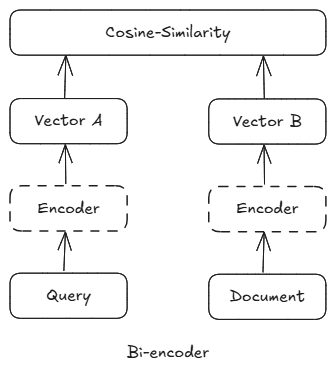
기본적으로는 두 가지 방식이 존재한다:
| 방식 | 설명 | 특징 |
|---|---|---|
| Bi-encoder | 질문과 문서를 각각 따로 임베딩 후, 코사인 유사도로 비교 | 빠르지만 문맥 정보 손실 가능 |
| Cross-encoder | 질문과 문서를 함께 입력해 정밀한 문맥적 관련성 평가 | 느리지만 정확함 |
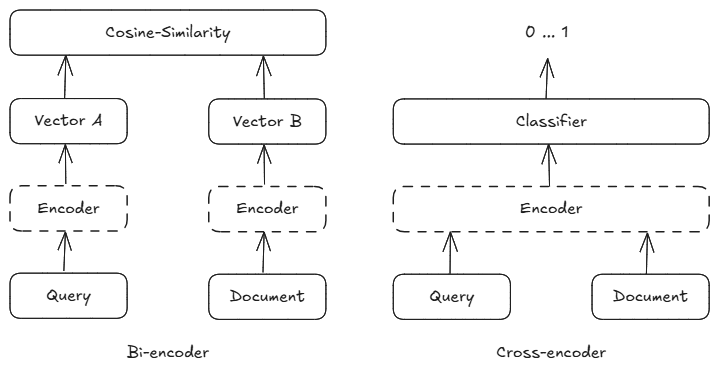
Reranker는 이 두 방식을 결합한다:
- Bi-encoder로 빠르게 후보 문서를 추출
- Cross-encoder로 각 문서의 질문과의 관련성을 정밀하게 평가
- 높은 관련도 순으로 문서를 재정렬 → LLM에 순차 입력
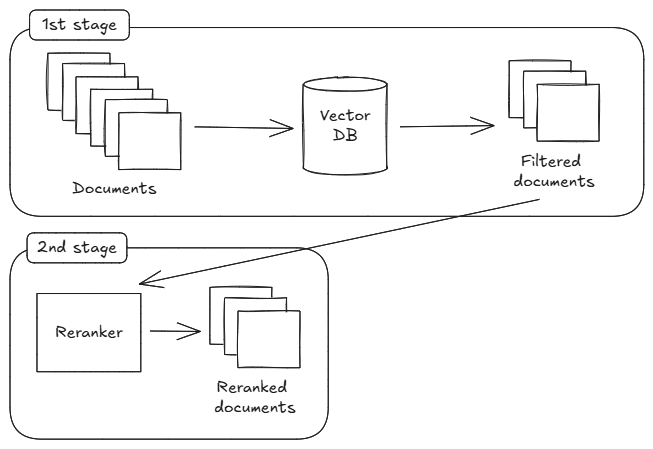
🧠 구조를 바꾸고 나서
검색 구조를 바꾼 결과,
전체적인 판단 흐름이 더 안정적으로 구성되었고,
이전보다 불필요한 ‘그린워싱 있음’ 판단이 줄어드는 경향이 보였다.
확실한 성능 향상이라고 단정짓기는 어렵지만, 구조적인 한계를 피하려는 시도였고, 그 목적에는 부합했다고 생각한다.
📌 정리하며
- 많은 문서를 넣는다고 답변이 좋아지는 건 아니다
- 오히려 중요한 문서가 묻히는 구조적 문제가 발생할 수 있다
- 나는 이 문제를 인지하고, Reranker를 통해 문서 순서의 우선순위를 조정했다
- Bi-encoder + Cross-encoder 조합 구조는 이 문제를 해결하는 데 도움이 되었다
