해설진들은 선수들이 자기 바로 앞의 선수를 추월할 때 추월한 선수의 이름을 부른다. 선수들의 이름이 1등부터 현재 등수 순서대로 담긴 문자열 배열 players와 해설진이 부른 이름을 담은 문자열 배열 callings가 매개변수로 주어질 때, 경주 종료 후 선수들의 순위를 출력하자.
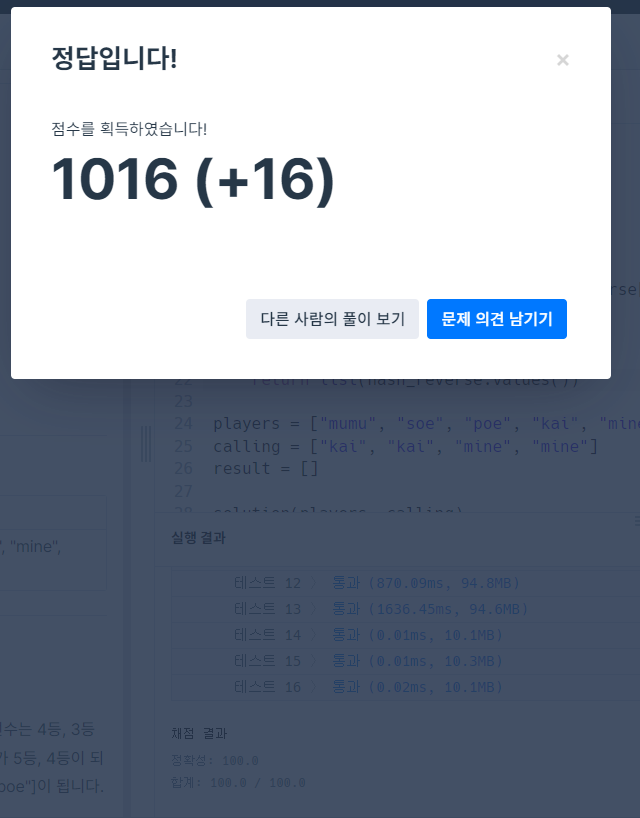
아이디어1 : 실패
부르는 순서가 담겨있는 배열을 하나씩 변수에 받으면서 플레이어스에 존재하는 사람의 이름을 찾고 순서를 Swap한다. 이를 순서가 담긴 배열의 길이만큼 반복한다.
- calling를 순서대로 부르면서 players에서 부른 선수를 찾는다.
- 그 순서와 그 앞에 선수의 위치를 Swap한다.
- 다음 반복문을 진행한다.
def solution(players, callings):
length = len(players)
for idx in range(len(callings)):
call_Name = callings[idx]
for i in range(length):
if(players[i] == call_Name):
saveIdx = i
break
temp = players[i]
players[i] = players[i-1]
players[i-1] = temp
answer = players
return answer
아이디어2 : 성공
왜 아이디어1은 실패했는가? : 플레이어 50000 * 1000000 => 5000000000(50억)
문제를 해결하기 위해서는 걸리는 시간복잡도를 확연하게 줄일 필요가 있었다.
DP방법을 대입해보면 시간복잡도를 줄일 수 있으니 그 쪽으로도 생각해보았는데 DP로 푸는 문제 같지는 않았다. DP는 중복된 계산? 같은 부분이 있어서 그런 부분을 메모라이징하고 참조하는 방법이니까 이 문제에는 적합하지 않은 것 같았다.
고민을 하던 중 작년 겨울방학에 했던 자료구조 학습 때 풀었던 해쉬가 생각났다. 문제 자체가 (1등 : mumu, 2등:soe)같은 형태로 해쉬를 사용하기에도 매우 적합했다.
코드를 작성하다가 막힌 부분은 선수 이름을 가져와 해쉬맵에 Map[선수명]을 통해 +1을 해서 지명한 선수의 등수를 올려주는 것까진 좋은데 그 앞에 있던 선수를 -1을 하는 과정도 꼭 필요했다. 그런데 calling에 있는 정보는 선수명 뿐이니 -1할 선수의 이름을 찾을 방법이 필요했다.
이 때 가장 핵심은 해쉬맵을 2개 만드는 것이다. 처음에는 파이썬 해쉬맵에 혹시 value를 통해 key를 찾는 방법이 있나 싶어서 찾아보았다. 대부분 순회를 통한 방법이어서 시간복잡도적으로 뭔가 문제가 있을 것 같았다. 더 찾아보던 중에 딕셔너리의 value 값으로 key를 자주 찾는다면 차라리 딕셔너리를 2개 만들면 공간복잡도 상승에 문제만 생기고 시간적으로 이득을 볼 수 있다는 내용이었다.
이를 적용해 아래 코드를 작성했다. 뭔가 2개의 해쉬맵을 오고 가며 값을 저장하고 변경하니 조금 정신이 없어서 그림판을 통해 천천히 이해하며 작성했다.
def solution(players, callings):
hash = {} # 선수 : 순위
hash_reverse = {} # 순위 : 선수
#시간복잡도 : player숫자만큼
for i in range(len(players)):
hash[players[i]] = i
hash_reverse[i] = players[i]
for v in callings: # 선수 이름을 가져왔다.
#순서를 옮긴다. 지목 선수 +1 당한 선수 -1
hash[v] -= 1
# v이전에 선수가 누구?
front = hash_reverse[hash[v]]
hash[front] += 1
temp = hash_reverse[hash[v]]
hash_reverse[hash[v]] = hash_reverse[hash[v]+1]
hash_reverse[hash[v]+1] = temp
#print()
return list(hash_reverse.values())
players = ["mumu", "soe", "poe", "kai", "mine"] # 현재 등수순위
calling = ["kai", "kai", "mine", "mine"]
result = []
solution(players, calling)