정수는 프로그래밍을 하면서 가장 많이 사용하게 될 타입이다.
C++에는 signed와 unsigned가 있다.
그리고 char, short, int, __int64(long long) 자료형이 있고 해당 자료형은 byte의 크기마다 다르다.
#include <iostream>
using namespace std;
// 주석을 다는 방법 2가지
// 1. // 슬래시 2개
// 2. /**/ 여러 줄은 이렇게
// 변수 선언 방법
// [타입] [이름] ;
// [타입] [이름] = [초기값];
// 0이 아닌 초기화 값이 있으면 .data 영역
int hp = 100;
// 초기 값이 0이거나, 초기 값이 없는 변수라면 .bss 영역
char a; // 1 byte (-128 ~ 127)
short b; // 2 byte (-32768 ~ 32767)
int c; // 4 byte
__int64 d; // 8 byte (long long)
unsigned char ua; // 1 byte (0 ~ 255)
unsigned short ub; // 2 byte (0 ~ 65536)
unsigned int uc; // 4 byte
unsigned __int64 ud; // 8 byte (long long)
// 참고) 이론적으로 양수만 존재할 수 있는 데이터 unsigned
// 무조건 unsigned를 사용할지 의견이 갈림
// - 레벨이 음수라는 것은 말이 안된다 --> 차라리 그 자리에서 프로그램을 크래시 내서 버그를 빨리 찾는게 낫다 라는 주의도 있음
// 귀찮은데 그냥 대충 4바이트로 가면 안될까?
// -> 콘솔/모바일 게임 -> 메모리가 늘 부족함
// -> 온라인 게임 : 4바이트 * 1만명.. 데이터양이 극단적으로 커짐
int main()
{
// 정수 오버플로우
b = 32767;
b = b+1;
cout << b << endl; //-32768
// 정수 언더플로우
ub = 0;
ub = ub -1;
cout << ub << endl; // 65535
cout <<"체력이 " << hp <<" 남았습니다." << endl ;
}signed 는 자료형을 선언하면 default로 적용되어있는 자료형이다. 이는 값의 범위를 음수~양수 까지로 표현해준다.
unsigned는 위와 같이 자료형 앞에 따로 선언해줘야한다. signed와의 차이는 오로지 양수만 사용한다는 것이다.
정수를 사용하게 되면 오버플로우, 언더플로우에 주의하자.
오버플로우는 자료형에서 사용할 수 있는 범위보다 큰 값을 사용하게 되면 다시 처음 값으로 돌아가는 것이고, 언더플로우는 반대로 자료형에서 사용할 수 있는 범위보다 작은 값을 사용하게 되면 최대 값으로 돌아가게 되는 것이다.
이는 우리가 앞서 배운 bit동작 원리와 같다. 위 코드를 예시 계산기에서 보면 아래와 같이 나온다. 오버플로우와 언더플로우의 동작 예시이다.

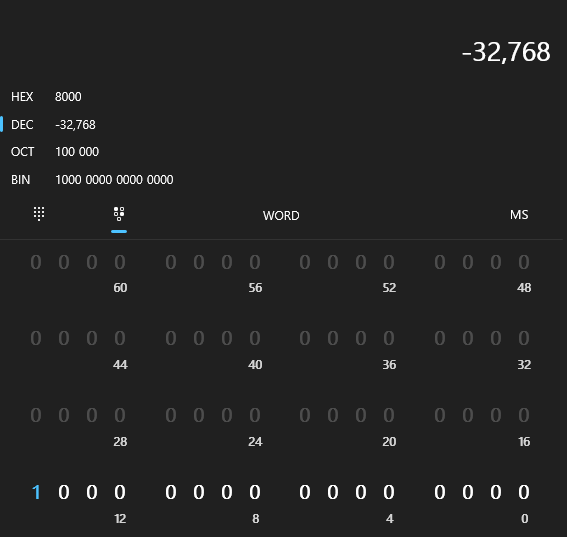
오버플로우와 언더플로우를 피하기 위해서 너무 큰 자료형을 사용하는 것도 주의해야한다. 우리에겐 메모리가 넉넉하지 않다.
오늘은 여기까지
이제 정말 C++을 시작했다. 앞서 환경설정 내용은 스킵하였다. 내가 사용하고 있는 IDE는 VScode이고 강의에서 나오는건 Visual Studio 이다. 추후 프로젝트를 따라할때 Visual Studio를 사용해서 해보겠다. - 사실 C++을 시작했다기엔 아직 강의가 좀 많이 남은거 같다. 기초는 빨리 빨리 넘겨야겠다. -끝-
