오늘 할 내용은 문자와 문자열이다.
문자
Bool type은 정수지만, 참/거짓을 나타내기 위해 사용했다
Char type도 마찬가지, 정수지만 '문자' 의미를 나타내기 위해 사용한다.
char : 알파벳/숫자 문자를 나타냄
wchar_t : 유니코드 문자를 나타냄
유니코드 사용이 필요한 이유는 국제적으로 사용하는 언어들이 모두 다르기 때문이다. 특정 영어나 한글로 모든 것을 표현할 수 없기 때문에 모든 문자에 대해 유일 코드를 부여하여 사용한 것이 유니코드이다.
참고) 유니코드에서 가장 많은 번호를 차지 하는게 한국어/중국어
유니코드는 표기 방식이 여러가지가 있는데 대표적으로 UTF8과 UTF16이다.
UTF8
- 알파벳, 숫자 1바이트 (ASCII 동일한 번호)
- 유럽 지역의 문자는 2바이크
- 한글. 한자 등 3바이트
UTF16
- 알파벳, 숫자, 한글, 한자 등 거의 대부분 문자 2바이트
- 매우 예외적인 고대 문자만 4바이트 (사실상 무시)
// '문자'의 의미로 작은 따옴표 '' 사용
char ch = 'a'; // char ch = 97;
char ch2 = '1';
char ch3 = 'a' + 1;위 char ch = 97 부분은 ASCII 코드(아스키코드)를 의미한다. a가 부여받은 넘버는 97번이라는 의미이다.
wchar_t는 유니코드를 사용하기 위한 자료형이다.
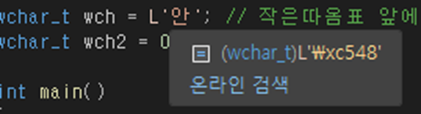
wchar_t wch = L'안'; // 작은따옴표 앞에 'L' 을 넣어서 캐스팅해줘야함.
wchar_t wch2 = 0xc548; // L'안'0xc548이 동일한 값을 출력하는 이유는 아래와 같다.
문자열
문자열은 문자를 배열로 나열한 것이다.
char str[] = {'h', 'e', 'l', 'l', 'o'}; // data 영역이라서 문제가 없는 것
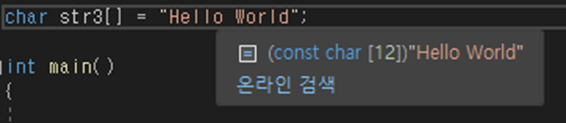
char str3[] = "Hello World";
wchar_t str4[] = L"Hello World";
int main()
{
wcout.imbue(locale("ko_KR.UTF-8")); //wcout.imbue(locale("kor")); 강의에서 나오는 kor은 에러를 발생시킴 - 표준 locale을 사용하자
cout << str << endl;
char str2[] = { 'h', 'e', 'l', 'l', 'o','\0'}; // stack 영역이기 때문에 뒤에 Null이 없으면 끝난 것을 인지하지 못하고 쓰레기 값을 노출하게됨 그래서 Null 이 필요함
char str5[] = "Hello World";
cout << str2 << endl;
cout << str3 << endl;
wcout << str4 << endl;
cout << str5 << endl;
}문자열을 선언하는 방법은 위와 같다.
1. Data영역에 배열을 선언 후 배열에 한 글자씩 넣어주기 (str)
2. Data영역에 배열을 선언 후 큰 따옴표로 묶어서 선언하기 (str3)
3. Stack영역에 배열을 선언 후 배열에 한 글자씩 넣어주기 (str2)
4. Stack영역에 배열을 선언 후 큰 따옴표로 묶어서 선언하기 (str5)
모두 정상동작 한다.
주의할 점이 있다.
data영역에서 문자열을 선언할 경우\0을 따로 해줄 필요가 없다. 자동적으로 선언되어있기 때문이다.
위 글자수를 세어보면(띄어쓰기 포함) 총 11개이다. 하지만 배열은 12개가 선언되어있는 것을 볼 수 있다. 이는 마지막에null이 자동 선언되어 있기 때문이다.
하지만,stack영역에서는 문자열을 선언할때\0(null)을 해주거나(3번) 큰 따옴표로 묶어서 선언(4번)해줘야한다.stack은null을 자동선언해주지 않기 때문에 끝을 모르고 쓰레기 값을 가져와 노출하게 되기 때문이다.
따라서null을 꼭 신경써주자!

wchar_t도 동일하다. (str4)
아래는 수업 full내용이다.
#include <iostream>
#include <locale>
using namespace std;
// 오늘의 주제 : 문자와 문자열
// bool은 그냥 정수지만, 참/거짓을 나타내기 위해 사용함
// char도 마찬가지, 그냥 정수지만 '문자' 의미를 나타내기 위해 사용
// char : 알파벳 / 숫자 문자를 나타냄
// wchar_T : 유니코드 문자를 나타냄
// ASCII (American Standard Code for Information Interchange)
// '문자'의 의미로 작은 따옴표 '' 사용
char ch = 'a'; // char ch = 97;
char ch2 = '1';
char ch3 = 'a' + 1;
// 국제화 시대에는 영어만으로 서비스 할 수 없음
// 전 세계 모든 문자에 대해 유일 코드를 부여한 것이 유니코드 (unicode)
// 참고) 유니코드에서 가장 많은 번호를 차지 하는게 한국어/중국어
// 유니코드는 표기 방식이 여러가지가 있는데 대표적으로 UTF8 UTF16
// UTF8
// -알파벳, 숫자 1바이트 (ASCII 동일한 번호)
// - 유럽 지역의 문자는 2바이크
// - 한글. 한자 등 3바이트
// UTF16
// - 알파벳, 숫자, 한글, 한자 등 거의 대부분 문자 2바이트
// - 매우 예외적인 고대 문자만 4바이트 (사실상 무시)
wchar_t wch = L'안'; // 작은따옴표 앞에 'L' 을 넣어서 캐스팅해줘야함.
wchar_t wch2 = 0xc548; // L'안'
// Escape Sequence
// 표기하기 애매한 애들을 표현
// \0 = 아스키코드 0 = Null
// \t = 아스키코드 9 = Tab
// \n = 아스키코드 10 = LineFeed (한줄 아래로)
// \r = 아스키코드 13 = Carriage Regturn (커서 <<)
// 문자열
// 문자들이 열을 지어서 모여있는 것 (문자 배열?)
// 정수 (1~8바이트) 고정 길이로
// 맨 끝에는 \0(null) 이 들어가있어야한다.
char str[] = {'h', 'e', 'l', 'l', 'o'}; // data 영역이라서 문제가 없는 것
char str3[] = "Hello World";
wchar_t str4[] = L"Hello World";
int main()
{
cout << ch << endl;
cout << ch2 << endl;
cout << ch3 << endl; // b
cout << wch << endl; // 50504 출력 -- wch를 cout에서 인식하지 못해서 생기는 문제
wcout.imbue(locale("ko_KR.UTF-8")); //wcout.imbue(locale("kor")); 강의에서 나오는 kor은 에러를 발생시킴 - 표준 locale을 사용하자
wcout << wch2 << endl;
wcout << wch << endl;
cout << str << endl;
char str2[] = { 'h', 'e', 'l', 'l', 'o','\0'}; // stack 영역이기 때문에 뒤에 Null이 없으면 끝난 것을 인지하지 못하고 쓰레기 값을 노출하게됨 그래서 Null 이 필요함
char str5[] = "Hello World";
cout << str2 << endl;
cout << str3 << endl;
wcout << str4 << endl;
cout << str5 << endl;
}
// locale::global(locale(""));
// wcout << "Current locale: " << locale().name().c_str() << endl;