ex. java.util.StringTokenizer
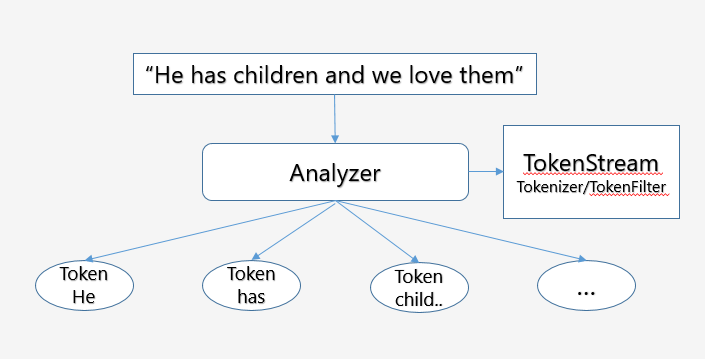
형태소 분석기(Analyzer)
필드에 지정된 텍스트를 색인 내부에서 사용하는 가장 기본적인 단위인 term으로 분리하는 작업
- 색인/검색에 사용
- 색인 과정에서의 분석 : 검색에 용이한 유의미한 Term으로 가공하여 색인에 저장
- 검색 과정에서의 분석 : 사용자 질의가 색인된 term에 최대한 일치하도록 형태소 분석 진행
TokenStream
분석하는 객체로 Analyzer의 구현체라 생각함, Tokenizer/TokenFilter로 구성
Tokenizer
텍스트를 Token으로 분리. 정해진 separator(ex : 공백, !@#등의 특수문자)를 기준으로 Token을 분리
- 주요 토크나이저
- StandardTokenizer : 문법 기반 토크나이저로, 유니코드 텍스트 분할 알고리즘에 명시된 규칙을 따름
- WhitespaceTokenizer : 공백 문자 로 텍스트 분할
- SpacialCharacter : !@# 문자 단위로 토큰 분리(CharTokenizer)
- NGramTokenizer : N-Gram 모델을 사용해 분할
- LowerCaseTokenizer : 대문자를 소문자로 변환
- 그 외 각 언어별 토크나이저 플러그인 제공(노리,아리랑 등)
TokenFilter
Tokenizer로 분리된 Token들을 필터링 또는 가공하여 Term 생성(ex : stopword - a,the 제거)
- 주요 토큰필터
- StopFilter : 토큰스트림에서 불용어 제거
- Stemming : 단어들의 기본 형태인 어간 추출(ex : cakes -> cake)
Token
단어와 메타정보를 담고 있음(전체 텍스트에서 시작/끝 지점, 토큰의 종류, 위치 증가 값…)

Search & Backend Engineer