
목적
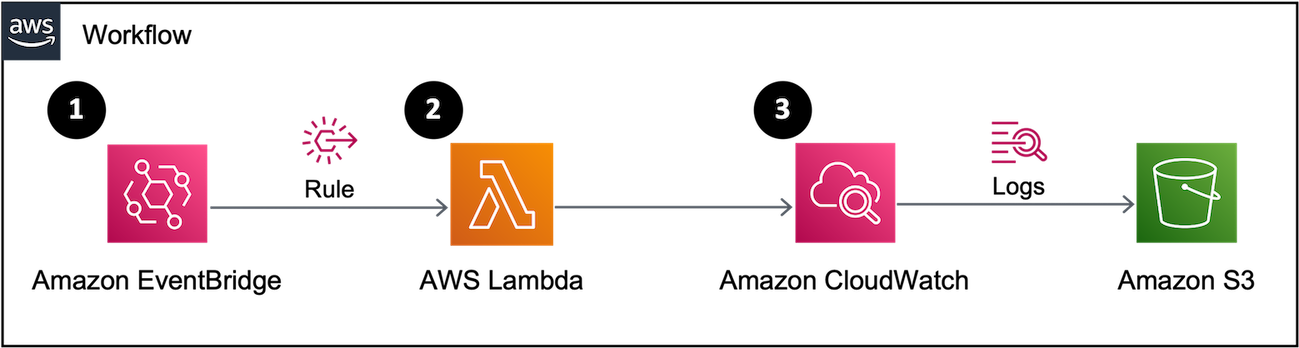
서버의 로그를 CloudWatch와 연동하여 쌓고있다. 하지만 CloudWatch 내 저장 로그가 많을수록 비용이 커지기 때문에, 일정 기간이 지난 로그를 S3로 이관하고 이관한 로그는 CloudWatch에서 삭제한다.
과정
- EventBridge에 정의한 Rule에 의해 주기적으로 Lambda를 호출
- Lambda에서 작성한 함수 로직대로 삭제 대상 주기의 CloudWatch 로그를 S3로 옮기고, 해당 주기 이후의 로그만 CloudWatch에 남기기
1. S3
-
퍼블릭 액세스 차단
- 모든 퍼블릭 액세스 차단 설정
-
버킷 정책
- CloudWatch가 객체를 버킷에 PUT(WRITE 액세스) 하도록 허용
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "logs.YOUR-REGION.amazonaws.com"
},
"Action": "s3:GetBucketAcl",
"Resource": "arn:aws:s3:::BUCKET_NAME_HERE"
},
{
"Effect": "Allow",
"Principal": {
"Service": "logs.YOUR-REGION.amazonaws.com"
},
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::BUCKET_NAME_HERE/*",
"Condition": {
"StringEquals": {
"s3:x-amz-acl": "bucket-owner-full-control"
}
}
}
]
}2. Lambda
IAM Role
-
Lambda에 이벤트를 기록하고 생성한 S3 버킷에 쓸 수 있는 권한이 필요합니다.
-
아래의 권한을 가진 Role 생성하여 부여
-
AmazonS3FullAccess
-
CloudWatchFullAccess
-
CloudWatchEventFullAccess
-
함수 생성
-
Lambda >> Functions >> Create Function
-
Author from scratch 선택하고, 런타임으로 Python을 선택
-
Execution role 에서 Use an existing role 선택하고 위에서 만든 IAM Role을 선택
함수 코드 작성
Python용 AWS SDK인 boto3를 사용하여 코드를 작성했다.
과정은 아래와 같고, 코드 곳곳에 주석으로 설명을 추가해 주었다.
'os.environ' 으로 사용한 환경 변수 값 설정은 구성 >> 환경 변수에서 설정하면 된다
- 해당 CloudWatch 로그 그룹 내의 해당 기간 범위 내의 로그 이벤트들을 지정된 S3 Bucket으로 이관한다.
- S3로 이관하는 함수의 완료 여부를 일정 주기로 체크한다
(S3로 이관하는 함수가 비동기(async) 호출이므로, 아래 코드에서 이관한 로그를 로그 스트림 통째로 삭제하기 때문에 이관 완료전에 로그 스트림을 삭제되는 경우가 발생)- 로그 스트림 별로 모든 로그 이벤트를 확인하여 이관하는 범위보다 이후의 로그 데이터들은 따로 변수에 보관한다.
(로그 이벤트들을 가져오고 저장할 때, 1MB 용량 제한이 있으므로 지정한 Batch 크기만큼씩 가져오고 저장)- 로그 스트림 통째로 삭제하고, 이전과 같은 이름으로 다시 빈 로그 스트림을 생성(로그 이벤트별로 삭제하는 기능은 지원되지 않음)
- 로그 스트림 별로 3번에서 보존해야할 로그 이벤트들이 있다면, 새로 생성된 빈 로그 스트림에 넣어준다
import boto3
import os
import datetime
import time
DESTINATION_BUCKET = os.environ['DESTINATION_BUCKET']
GROUP_NAME = os.environ['GROUP_NAME']
PREFIX = os.environ['PREFIX']
BATCH_SIZE = int(os.environ['BATCH_SIZE'])
DAYS = int(os.environ['DAYS'])
EXPORT_CHECK_CYCLE_TIME = int(os.environ['EXPORT_CHECK_CYCLE_TIME'])
currentTime = datetime.datetime.now()
start_date = currentTime - datetime.timedelta(days=(DAYS * 2))
end_date = currentTime - datetime.timedelta(days=DAYS)
FROM_DATE = int(start_date.timestamp() * 1000)
TO_DATE = int(end_date.timestamp() * 1000)
#S3 Log Bucket Directory
BUCKET_PREFIX = os.path.join(PREFIX, end_date.strftime('%Y{0}%m{0}%d').format(os.path.sep))
#1. Export CloudWatch logs in logGroup within a specified time range to S3
#2. Wait for the export operation to finish(because create_export_task is an asynchronous call)
#3. Check CloudWatch LogStream whether log events that need to be preserved exists or not
#4. If there are logs to be preserved, store logs in variables
#5. delete & remake LogStream with the same name as previously used and put the archived logs in LogStream
def lambda_handler(event, context):
client = boto3.client('logs')
#Export CloudWatch Log To S3
response = client.create_export_task(
logGroupName=GROUP_NAME,
fromTime=FROM_DATE,
to=TO_DATE,
destination=DESTINATION_BUCKET,
destinationPrefix=BUCKET_PREFIX
)
#Check create_export_task is finished
taskId = response['taskId']
status = 'RUNNING'
while status in ['RUNNING','PENDING']:
time.sleep(EXPORT_CHECK_CYCLE_TIME)
response_desc = client.describe_export_tasks(
taskId=taskId
)
status = response_desc['exportTasks'][0]['status']['code']
#If create_export_task is finished
if status == 'COMPLETED':
#Get all LogStreams in LogGroup
log_streams = client.describe_log_streams(logGroupName=GROUP_NAME)['logStreams']
for stream in log_streams:
stream_name = stream['logStreamName']
#If you have reached the end of the stream, it returns the same token you passed in
prev_token = 'prev_token'
next_token = None
kwargs = dict(
logGroupName=GROUP_NAME,
logStreamName=stream_name,
startTime=TO_DATE,
limit=BATCH_SIZE,
startFromHead=False
)
retention_events = []
while next_token != prev_token:
#Get batch size LogEvents in LogStream at a time, in order of latest
if next_token is not None:
kwargs['nextToken'] = next_token
log_event_info = client.get_log_events(**kwargs)
events = log_event_info['events']
prev_token = next_token
next_token = log_event_info['nextForwardToken']
for event in events:
if event['timestamp'] <= TO_DATE:
break
#Remove keys not needed in put_log_events function
del event['ingestionTime']
retention_events.append(event)
#Delete & remake LogStream
client.delete_log_stream(logGroupName=GROUP_NAME, logStreamName=stream_name)
client.create_log_stream(logGroupName=GROUP_NAME, logStreamName=stream_name)
#If there are log events that need to be preserved in LogStream, Put batch size LogEvents in LogStream at a time
retention_events_size = len(retention_events)
for i in range(0, retention_events_size, BATCH_SIZE):
client.put_log_events(
logGroupName=GROUP_NAME,
logStreamName=stream_name,
logEvents=retention_events[i : (i + BATCH_SIZE)]
)
time.sleep(0.2)3. EventBridge
작성한 Lambda 함수가 자동으로 원하는 시점에 주기적으로 실행되도록 트리거에 사용할 이벤트를 생성한다.
-
규칙에서 규칙 생성 클릭
-
규칙 유형에서 일정 선택
-
특정 시간에 실행되는 세분화된 일정 선택
-
Cron 표현식으로 일정 주기 설정
-
대상 유형 - AWS 서비스, 대상 선택 - Lambda 함수, 함수 선택에서 만든 Lambda 함수 선택
참고 문서

끊임없이 성장하고 싶은 개발자