문제
arr = [a0,a1,...,an-1] 있을때
ai ~ ai+j 의 합을 구하거나
ai의 값을 변경해봐라
문제링크
문제만 보고 세그먼트 트리로 구현하면 될거같아서 시도해봤는데
시간 초과가 발생했다.
그래서 이참에 펜윅트리를 검색해봐서 정리해보자
펜윅트리
얍문님의 블로그를 바탕으로 재구성한 내용이다.
세그먼트 트리의 일종인데 구간합을 구현할때
세그먼트 트리보다 메모리와 시간복잡도를 절약할 수 있는 알고리즘이다.
세그먼트 트리와 비슷하게 update, query 부분이 존재한다.
다만 트리를 표현하는 방식에서 차이가 있다.
기존의 세그먼트 트리는 다음과 같지만
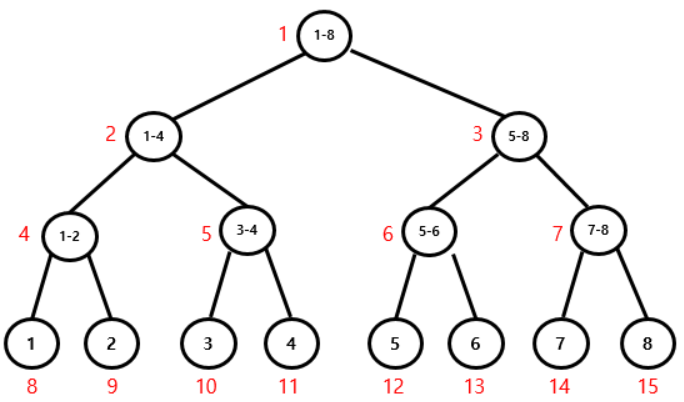 출처: https://yabmoons.tistory.com/438 [얍문's Coding World..:티스토리]
출처: https://yabmoons.tistory.com/438 [얍문's Coding World..:티스토리]
펜윅트리는 다음과 같다.
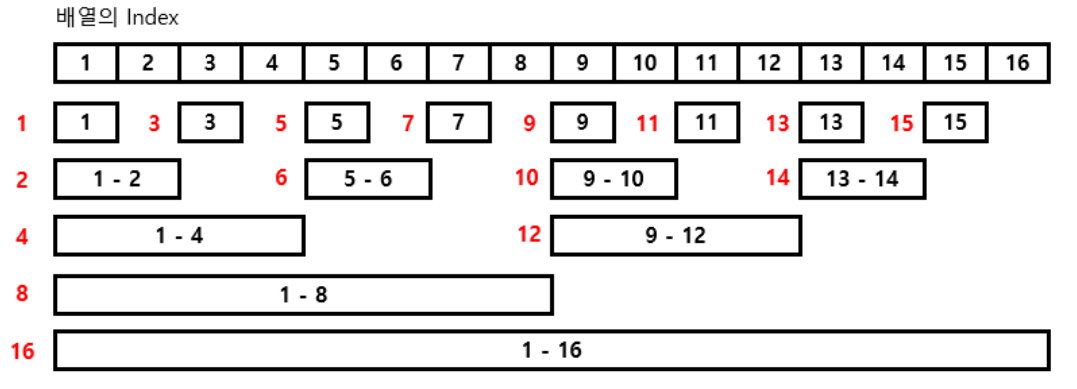 출처: https://yabmoons.tistory.com/438 [얍문's Coding World..:티스토리]
출처: https://yabmoons.tistory.com/438 [얍문's Coding World..:티스토리]
펜윅트리는 각 노드가 나타내는 의미는
2진수로 표현했을때
자리 수중 가장 작은 비트의 크기만큼
왼쪽으로 포함하는 구간
 출처: https://yabmoons.tistory.com/438 [얍문's Coding World..:티스토리]
출처: https://yabmoons.tistory.com/438 [얍문's Coding World..:티스토리]
예를 들어 6번 노드는 0110 이고
1번 비트가 가장 작은 비트니까
6으로부터 왼쪽으로 2^1개를 포함하는 data 5~6의 구간을 의미한다.
다시 위 그림에서 12는 1100 이니까
2번 비트 2^2=4 만큼 왼쪽으로 포함하는
9~12까지 구간을 의미한다.
그럼 이제 각 노드의 의미를 알았으니 update, query만 남았다.
update
update는 작은 인덱스부터 범위를 넓혀나간다.
예를 들어 9번 data를 update 해보자.
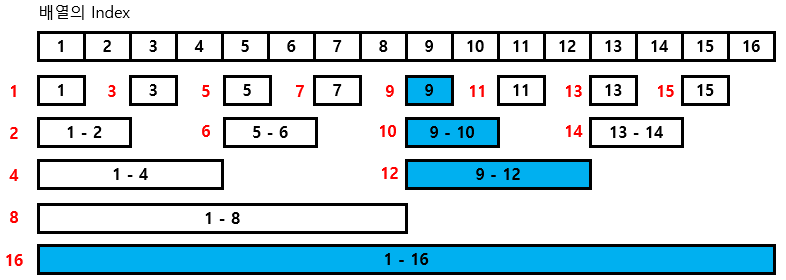 출처: https://yabmoons.tistory.com/438 [얍문's Coding World..:티스토리]
출처: https://yabmoons.tistory.com/438 [얍문's Coding World..:티스토리]
그럼 9번이 들어있는 9,10,12,16 도 update를 해줘야한다.
2진수로 표현하면 다음과 같은 순서다.
1001(9) -> 1010(10) -> 1100(12) -> 10000(16)
잘보면 제일작은 비트가 계속 더해지는것을 볼 수 있다.
1001 + 0001 = 1010
1010 + 0010 = 1100
1100 + 0100 = 10000
같은 형태다.
제일 작은 비트
펜윅트리는 제일 작은 비트를 반복해서 사용하는데
이를 구하는 방법은 for문으로 구하는 방법도 있지만
보수를 이용하는 방법이 있다.
보수는 각 비트를 모두 뒤집고 1을 더해준다.
예를 들어 9의 보수는 1001 => 0110 => 0111 이다.
이때 1001 & 0111 = 0001 이 나온다.
즉 idx & -idx = 제일 작은 비트가 된다.
그럼 다시 update로 돌아와서
9번이 들어있는 9,10,12,16를 update를 해줘야하는데
idx += (idx & -idx) 를 해주면 차례차례 증가가 가능하다.
그럼 최대 범위(n)까지 증가하며 새로운 값을 update 해주면 된다.
void update(int idx,int val){
while(idx<n+1){
graph[idx]+=val;
idx+=(idx & -idx);
}
}query
query는 update와는 반대로 큰 인덱스부터 범위를 좁혀간다.
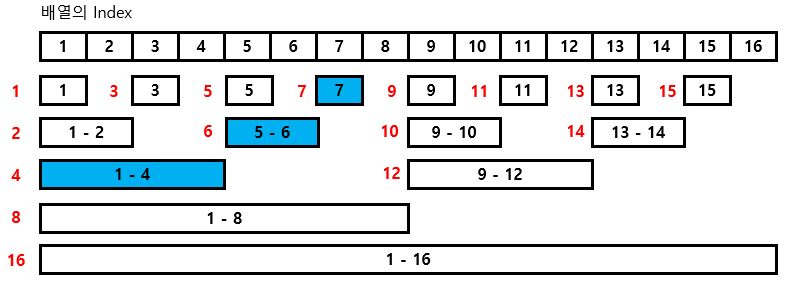 출처: https://yabmoons.tistory.com/438 [얍문's Coding World..:티스토리]
출처: https://yabmoons.tistory.com/438 [얍문's Coding World..:티스토리]
예를 들어 query(7)은 7이 포함된 7,6,4번의 합이다.
0111(7) + 0110(6) + 0100(4) 이다.
가장 작은 비트가 하나씩 빠지는 형태임을 알 수 있다.
0111 - 0001 = 0110
0110 - 0010 = 0100
0100 - 0100 = 0000 (제외)
그러면 updat 코드에서 순서만 바꿔주면서 더해주면 될것이다.
1번부터 시작하기 때문에 0번은 제외한다.
long query(int idx){
long ret=0;
while(idx>0){
ret+=graph[idx];
idx-=(idx & -idx);
}
return ret;
}구간합
앞서 말했듯이 펜윅 트리는 구간합을 위한 알고리즘이다.
그래서 query도 1번부터 i번까지의 합이다.
만약 i번~j번 합이 구하고 싶으면
query(j) - query(i-1)을 해주면 된다.
세그먼트 트리와의 차이
이 포스팅에서 가장 궁금했던 내용이다.
간단히 요약하면 다음과 같다.
펜윅 트리 : 구간합만 가능, 빠른 쿼리 가능
세그먼트 트리 : 구간합이 아니어도 가능, 상대적으로 느린 쿼리
펜윈 트리 query를 연산할때 1번 부터 계산했다.
그래서 i~j 값을 구하려면 query(j)-query(i-1)로 얻을 수 있었다.
이러한 특성때문에 구간에대한 연산(합,곱,등...)만 가능하고
개별 원소에대한 연산(max,min,등...)은 불가능하다.
i~j 사이 최대값을 구하라고했을때 query(j)-query(i-1) 같은 방식으로는 구하기가 어렵다.
그래서 빠른 구간 연산을 원할때 사용되는 알고리즘이다.
왜 빠를까
사실 시간복잡도를 찾아보면 update, query 모두 logN이다.
둘다 트리를 쭉 타고 내려가서 값들을 갖고 오기 때문이다.
하지만 트리 구조가 조금 다르다.
세그먼트 트리 : 계속해서 절반으로 쪼개짐
펜윅 트리 : k bit로 표현했을때 반드시 k 연산 안에 쿼리가능
query(1,10000) 을 계산한다고 하자.
세그먼트 트리는 크기가 2*PIV (PIV은 2^k > N)으로 된 트리에서 검색하는데
logN 깊이의 트리를 여러개의 가지로 찾아나선후 그들을 합한다.

위 그림은 query(4,8)의 형태인데 query(1,10000) 이라면 무수히 많은 중간 가지들이 생겨서 logN+k 형태가 된다.(k는 뻗어나간 세그먼트 수가될것이다.) 그래서 logN이지만 k에 따라 굉장히 커질수 있다.
반대로 펜윅 트리는 가장 작은 비트부터 1씩 빼면서 구간합을 구한다.
10000을 2진수로 표현하면 다음과 같다.

10000은 14bit로 표현 가능하고 1인 비트가 5개 이므로 펜윅 트리에서는 5번의 query만으로 구간합을 구할 수가 있다.
실제로 세그먼트와 펜윅트리로 query(1,10000)을 연산했을때 결과다.
// segment
update cnt:277232
query cnt:19999
// fenwick
update cnt:71728
query cnt:5
query 연산에서 압도적인 차이를 보여준다.
(update도 위와같은 비슷한 이유로 차이가 조금 있다.)
code
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.StringTokenizer;
class B_SOL {
int n,q;
long[] graph;
public void solve() throws IOException {
BufferedReader br=new BufferedReader(new InputStreamReader(System.in));
StringTokenizer stk;
stk=new StringTokenizer(br.readLine());
n=Integer.parseInt(stk.nextToken());
q=Integer.parseInt(stk.nextToken());
graph=new long[n+1];
stk=new StringTokenizer(br.readLine());
for(int i=1;i<=n;i++){
int v=Integer.parseInt(stk.nextToken());
update(i,v);
}
StringBuilder ans=new StringBuilder();
for(int i=0;i<q;i++){
stk=new StringTokenizer(br.readLine());
int k=Integer.parseInt(stk.nextToken());
int l=Integer.parseInt(stk.nextToken());
int r=Integer.parseInt(stk.nextToken());
l++; // 1번 인덱스부터 시작
if(k==0) update(l,r);
else ans.append(query(r)-query(l-1)).append("\n");
}
// print
System.out.print(ans);
}
void update(int idx,int val){
while(idx<n+1){
graph[idx]+=val;
idx+=(idx & -idx);
}
}
long query(int idx){
long ret=0;
while(idx>0){
ret+=graph[idx];
idx-=(idx & -idx);
}
return ret;
}
}
public class Main {
public static void main(String[] args) throws IOException {
B_SOL sol=new B_SOL();
sol.solve();
}
}
