JPA 기본
1.JPA[기본] 소개

Java Persistence APIJPA 실무에서 어려운 이유예제들은 보통 테이블이 한 두 개로 단순함실무는 수십 개 이상의 복잡한 객체와 테이블 사용객체와 테이블을 제대로 설계하고 매핑하는 방법기본 키와 외래 키 매핑 하는 법1:N, N:1, 1:1, N:M 매핑
2.JPA [기본] JPA 시작하기
JPA를 왜 사용해야 하는가? SQL 중심적인 개발에서 객체 중심으로 개발 생산성, 유지보수, 패러다임의 불일치 해결, 성능 > - EX 저장 jpa.persist(member) 조회 Member member = jpa.find(memberId) 수정 member.
3.JPA [기본] 내부동작방식
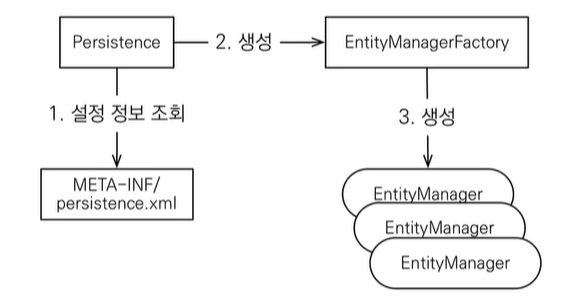
JPA 영속성 컨텍스트
4.JPA [기본] 플러시, 준영속상태
변경 감지 (더티체킹)수정된 Entity 쓰기지연 SQL 저장소에 등록쓰기 지연 SQL, 저장소의 쿼리를 데이터 베이스에 전송 (등록, 수정, 삭제 쿼리)트랜잭션이라는 작업 단위가 중요 -> 커밋 직전에만 동기화 하면된다.!! em.commit 전에 쿼리문을 미리 보고
5.JPA [기본] Entity 매핑
객체와 테이블 매핑@Entity, @Table필드와 컬럼 매핑@Column기본키 매핑@Id연관관계 매핑@ManyToOne, @JoinColumn@Entity가 붙은 클래스는 JPA가 관리, 엔티티라 한다.JPA를 사용해서 테이블과 매핑할 클래스는 @Entity 필수주의
6.JPA [기본] 필드와 컬럼 매핑, 데이터베이스 스키마 자동생성
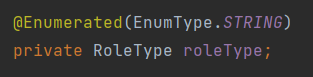
@Column컬럼 매핑@Temporal ( 자바 8로 넘어오면서 LocalDate가 등장후 사용 X)날짜 타입 매핑@Enumeratedenum 타입 매핑@LobBLOB, CLOB 매핑@Transient관리가 필요가 없는 데이터@Column(제일중요)@Column (nu
7.JPA [기본] 기본키 매핑
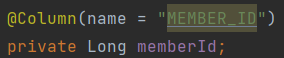
기본키 매핑 기본 키 매핑 어노테이션 > @Id @GeneratedValue 업로드중.. 기본 키 매핑 방법 > 직접 할당 : @Id만 사용 자동 생성 (@GeneratedValue) IDENTITY : 데이터베이스에 위임, MYSQL SEQUENCE : 데이
8.JPA [기본] 연관 관계1 (방향)
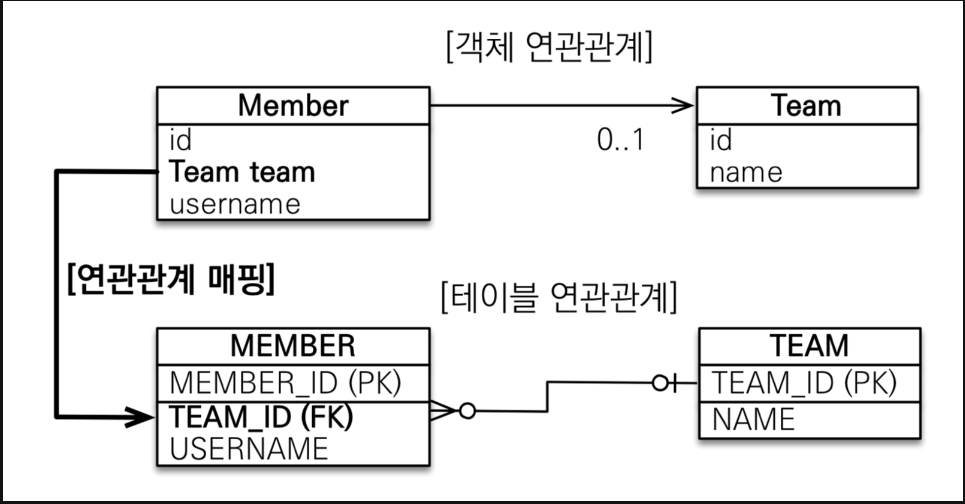
객체와 테이블 연관관계의 차이를 이해 > 객체를 테이블에 맞추어 데이터 중심으로 모델링하면, 협력 관계를 만들수없다. 테이블 "외래 키로 조인"을 사용해서 연관된 "테이블"을 찾는다. 객체 "참조"를 사용해서 연관된 "객체"를 찾는다. 테이블과 객체 사이에는 이
9.JPA [기본] 양방향 연관관계 - 주의점, 정리

양방향 연관관계 시 주의점 > 순수 객체 상태를 고려해서 항상 양쪽에 값을 설정해야 한다. 연관관계 편의 메서드를 생성하는 것이 좋다. 양방향 연관관계 정리 > 1. 단방향 매핑만으로 이미 연관관계 매핑은 완료된다. 2. 양방향 매핑은 반대 방향으로 객체 탐색 기능
10.JPA [기본] 다양한 연관관계 매핑
연관관계 매핑시 고려사항 3가지 다중성 단방향, 양방향 연관관계의 주인 (양방향 일때)
11.JPA [기본] 다양한 연관관계 매핑 - 다대일 (N:1)
다대일
12.JPA [기본] 다양한 연관관계 매핑 - 일대다 (1:N)
일대다
13.JPA [기본] 다양한 연관관계 매핑 - 일대일 (1:1)
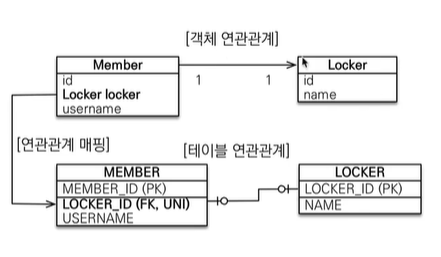
주 테이블이나 대상 테이블 중에 외래 키 선택가능주 테이블에 외래 키대상 테이블에 외래 키외래 키에 데이터베이스 유니크 (UNI) 제약조건 추가시나리오<회원 1명이 사물함 1개를 쓸수있는 상황> (1:1)UNI 제약조건을 MEMBER 테이블에 설정해도되고 OR L
14.JPA [기본] 다양한 연관관계 매핑 - 다대다 (N:N)
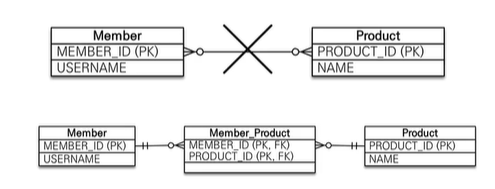
관계형 데이터베이스는 정규화된 테이블 2개로 다대다 관계를 표현할수 없다.연결 테이블을 추가해서 일대다, 다대일 관계로 풀어야한다.@ManyToMany 사용@JoinTable로 연결 테이블 지정다대다 매핑 : 단방향, 양방향 가능편리해 보이지만 실무에서 사용 X연결 테
15.JPA [기본] 고급 매핑 - 상속관계 매핑
상속관계 매핑 관계형 데이터베이스는 상속 관계 X 슈퍼타입 서브타입 관계라는 모델링 기법이 객체 상속과 유사 상속관계 매핑 : 객체의 상속과 구조와 DB의 슈퍼타입 서브타입 관계를 매핑 > 슈퍼타입 서브타입 논리 모델을 실제 물리 모델로 구현하는 방법 각각 테이
16.JPA [기본] 매핑 정보 상속
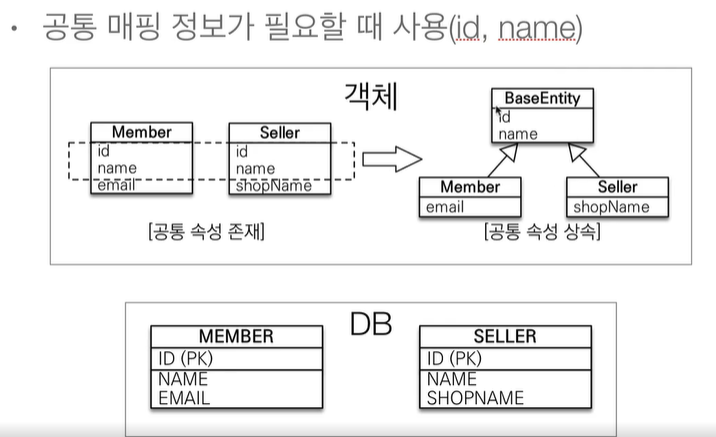
부모 클래스 여기서는 (BaseEntity) @MappedSuperclass 사용공통 매핑이 되는 Column이 있을경우 부모 클래스에서 속성만 상속받아 사용상속관계 매핑 X엔티티 X, 테이블과 매핑 X부모 클래스를 상속받는 "자식 클래스에 매핑 정보"만 제공조회, 검
17.JPA [기본] 프록시
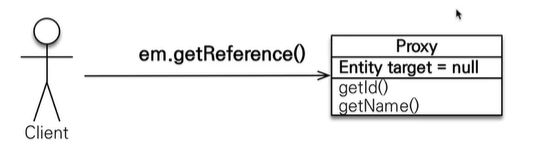
em.find() : 데이터베이스를 통해서 실제 엔티티 객체를 조회em.getReference() : 데이터베이스 조회를 미루는 가짜 (프록시, 껍데기) 엔티티 객체 조회실제 클래스를 상속받아서 만들어진다.실제 클래스와 겉 모양이 같다.사용하는 입장에서는 진짜 객체인지
18.JPA [기본] 즉시로딩과 지연로딩
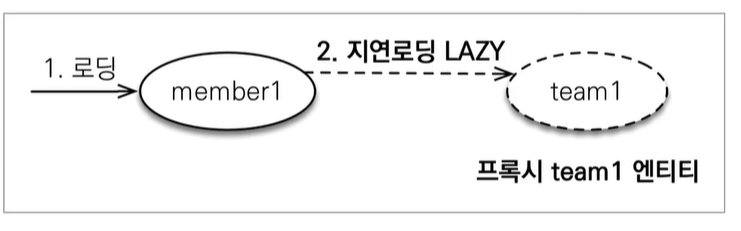
즉시로딩과 지연로딩
19.JPA [기본] 영속성 전이(CASCADE)와 고아 객체
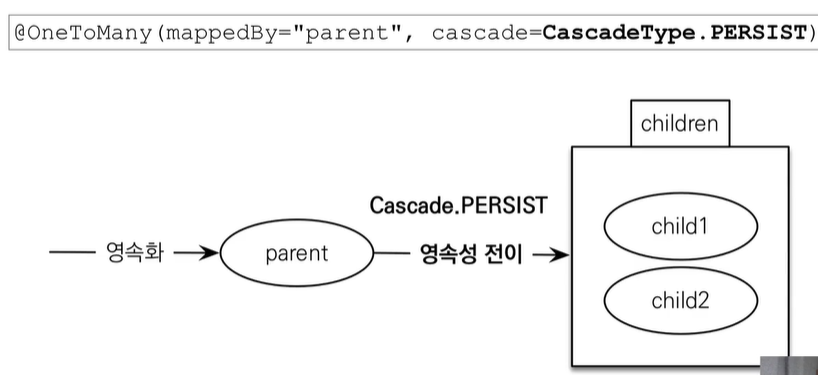
@OneToMany에 cascade 조건을 설정한다 (소유자(부모)가 하나일때 사용)특정 엔티티를 영속 상태로 만들 때 연관된 엔티티도 함께 영속 상태로 만들고 싶을때예 ) : 부모 엔티티를 저장할때 자식 엔티티도 함께 저장persist, commit을 부모 엔티티만
20.JPA [기본] 값 타입의 비교

값 타입 : 인스턴스가 달라도 그 안에 값이 같으면 같은 것으로 봐야된다.int 타입의 a == b는 true가 반환되는 반면, 객체 타입의 a == b는 false가 나온다.이유는 : 객체 타입임으로 주소값을 비교함으로 false가 나옴동일성 (identity) 비교
21.JPA [기본] JPA의 데이터 타입 분류
엔티티 타입 > @Entity로 정의하는 객체 데이터가 변해도 식별자로 지속해서 추적 가능 예 ) 회원 엔티티의 키나 나이 값을 변경하여도 식별자로 인식가능 값 타입 값 타입은 복잡한 객체 세상을 조금이라도 단순화 하려고 만든 개념이다 값 타입의 분류 > 1. 기본
22.JPA [기본] 객체지향 쿼리언어 1
JPQLJPA CriteriaQueryDSL네이티브 SQLJDBC API 직접 사용, MyBatis, SpringJdbcTemplate 함께 사용JPA를 사용하면 엔티티 객체를 중심으로 개발모든 DB 데이터를 객체로 변환해서 검색하는 것은 불가능하다 ➡ 결국 애플리케
23.JPA [기본] JPQL 기본문법, 쿼리 API
📌 JPAL 문법 > select_절, from_절, [where_절], [groupby_절], [having_절], [orderby_절] update문 :: update절 [where_절] delete문 :; delete절 [where 절] ✔ 예시 ) > 엔티
24.JPA [기본] 프로젝션, 페이징
📌 프로젝션 이란? SELECT 절에서 조회할 대상을 지정하는것. 조회할 대상 EX : 엔티티, 임베디드 타입, 스칼라타입 -> 엔티티 조회 -> 엔티티 조회 (m.team X 최대한 SQL 스럽게 (명시적 조인으로) 작성해야된다, 그렇지 않으면 Join이 발생함
25.JPA [기본] 조인, 서브 쿼리
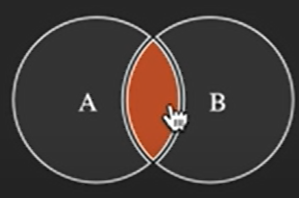
ex ) SELECT m FROM Member m \[INNER] JOIN m.team tNULL 행이 존재하지 않는다. (Member는 있고 team이 없으면 조회 X) INNER는 생략 가능하다 A, B 둘다 겹치는 정보를 조인 하는것이 INNER 조인이다.ex
26.JPA [기본] JPQL 타입 표현, 조건식 (CASE)
📌 JPQL 타입 표현 문자 : 'HELLO', 'She"s' 숫자 : 10L (Long), 10D (Double), 10F (Float) Boolean : TRUE, FALSE ENUM (조심해서 사용) EX) : where 엔티티 = jpa..타입명 (패키지명
27.JPA [기본] JPQL - 경로 표현식
📌 중급 문법 경로 표현식 . 점을 찍어 객체 그래프를 탐색하는것 상태 필드 단순히 값을 저장하기 위한 필드 !! 특징 : 경로 탐색의 끝, 탐색 X 연관 필드 (실무에서는 묵시적 조인 X, 명시적 조인을 사용해야된다) 연관관계를 위한 필드 > ✔ 단일 값
28.JPA [기본] 페치조인 중요!!
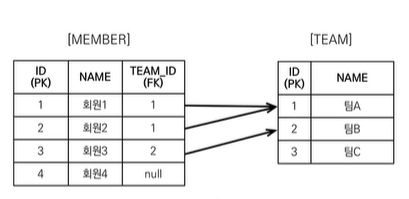
📌 페치조인 (Fetch Join) SQL의 조인 종류가 아니다. JPQL에서 "성능 최적화"를 위해 제공하는 기능 연관된 엔티티나 컬렉션을 SQL 한번에 함께 조회하는 기능이다 join fetch 명령어 사용 페치 조인
29.JPA [기본] 페치조인의 특징과 한계
📌 페치 조인의 특징과 한계 > 페치 조인 대상에는 별칭을 줄 수 없다. 하이버네이트에는 가능하지만, 가급적 사용 X > 둘 이상의 컬렉션은 페치 조인 할수 없다. 예시 ) "일대다" 의 "다" 이다. (컬렉션 + 컬렉션) > 컬렉션을 페치 조인하면 페이징
30.JPA [기본] 엔티티 직접 사용, Named 쿼리

📌 엔티티 직접 사용 JPQL에서 엔티티를 직접 사용하면 SQL에서 해당 엔티티의 기본 키 값을 사용한다. JPQL --> 엔티티의 아이디를 사용 --> 엔티티를 직접사용 SQL (JPQL 둘다 같은 SQL을 실행한다) (엔티티의 pk값을 기본값으로 한다)
31.JPA [기본] 벌크 연산

📌 벌크연산 SQL문에서 사용하는 update, delete문과 동일하다. 쿼리 한번으로 여러 테이블 로우 변경 (엔티티) > 사용 예시 의 결과는 영향받은 엔티티 수를 반환한다. 업로드중.. 벌크 연산 주의 벌크 연산은 영속성 컨텍스트를 무시하고 DB에 직접 쿼