🌳 Tree
🔎 이진탐색트리 (BST)
- 이진탐색 트리란?
이진트리에서 효율적인 탐색 작업을 위한 자료구조 입니다.
- 이진탐색트리는 다음과 같은 특징이 있습니다.
- 모든 노드의 데이터 값이 다릅니다.
- 자식이 있는 노드
- 왼쪽 자식노드는 부모 노드보다 작습니다.
- 오른쪽 자식노드는 부모 노드보다 큽니다.
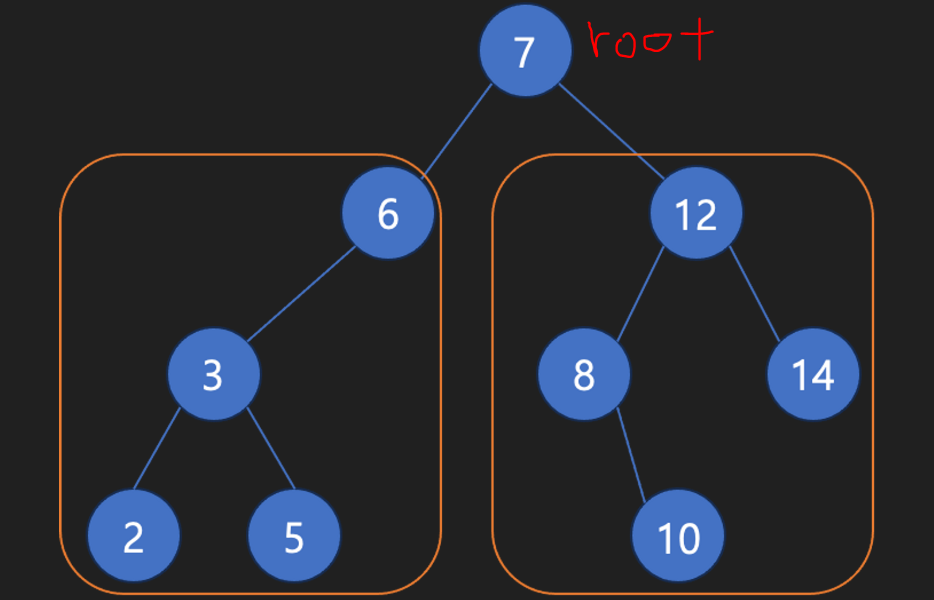
📍 이진탐색트리 탐색
데이터 값
2를 탐색 한다면, 루트노드 부터 시작하여 탐색할 데이터 (2)를 비교합니다.
탐색하는 데이터가 비교할 노드 보다 크다면 ?
➡ 오른쪽 서브트리로
탐색하는 데이터가 비교할 노드 보다 작다면 ?
➡ 왼쪽 서브트리로
✔ 2는 3번 탐색이 이루어 졌으며, 8을 탐색하고자 했으면 2번의 탐색이 이루어 질것입니다.
만약 탐색후 값을 찾지 못하면 그대로 종료 합니다.
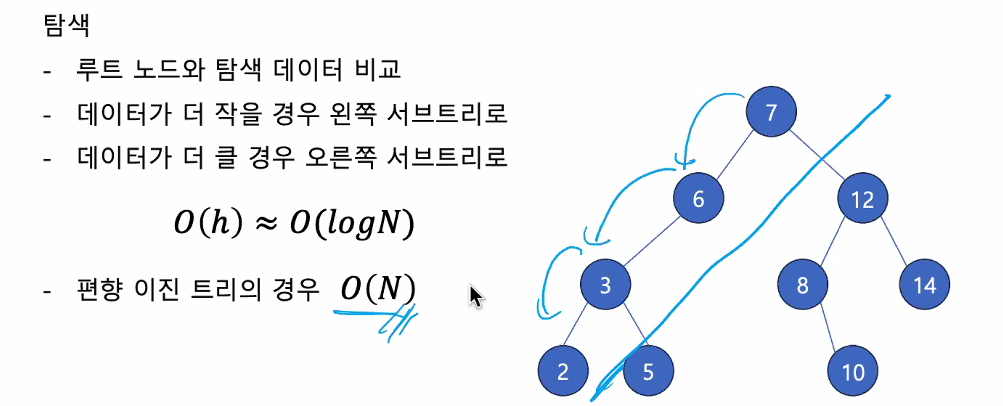
📍 이진탐색트리 삽입
- 데이터 값 6을 삽입 한다고 가정하겠습니다.
- 루트 노드부터 비교해가며 이진 탐색트리의 특징(규칙)을 지키며 노드를 삽입합니다.
삽입에서는 탐색과 비슷한 과정을 거치게 되며, 탐색에 성공하게 되면 데이터 삽입이 불가능 합니다. (중복된 데이터 값을 허용하지 않음)
- 탐색에 실패하는 경우에만 데이터를 추가하게됩니다.
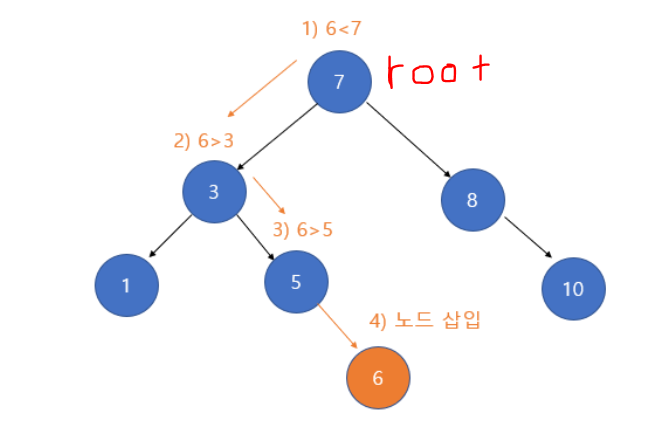
📍 이진탐색트리 삭제
- 삭제할 노드가 자식노드가 없는경우
- 삭제할 노드가 자식노드가 없는경우에는 탐색을 거친후 삭제할 노드를 삭제합니다. ( 링크 해제 )
- EX : 13, 10 같은 경우
- 삭제할 노드가 자식노드가 한개인 경우
- 삭제하려는 노드의 자식노드가 한개인 경우 탐색을 거친후 삭제할 노드를 삭제후 남겨진 자식노드를 윗 레벨로 한 단계 땡깁니다.
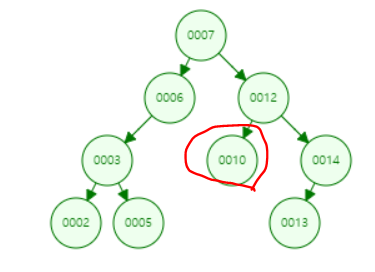
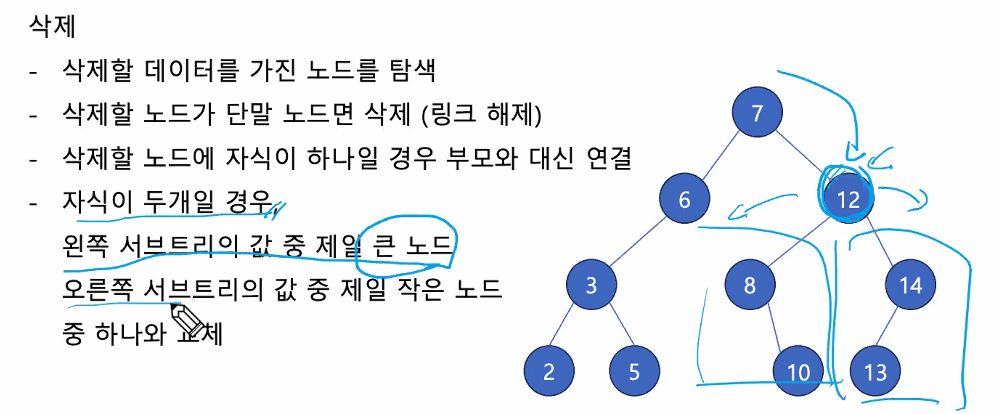
- 삭제할 노드가 자식노드가 두개인 경우
데이터 값
12는 자식노드가 2개인 경우 입니다.12를 삭제한다고 가정했을때, 이진탐색의 특징(규칙)에 맞춰 자식노드를 갈아 끼웁니다.
- 위 사진과 같은 경우에는
10노드가 들어와야 규칙에 맞습니다.
➡ (자리가 적절히 이동해야 한다고 합니다.)
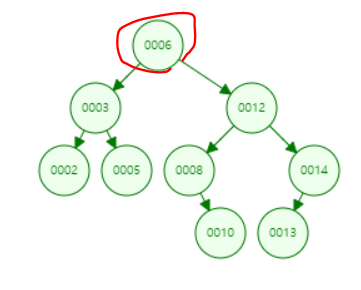
✔ 루트노드도 삭제가 가능 합니다.
- 루트 노드(7) 을 삭제하게된다면, 6 과 12가 교체 후보가 됩니다.
(삭제후 노드를 교체하면서 이진트리의 기준을 만족해야합니다.)
🌳🌳🌳 포화이진트리
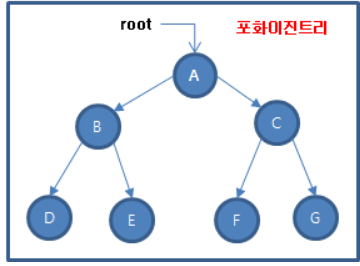
- 마지막 레벨까지 모든 노드가 있는 이진 트리 입니다.
🙆♂️ Spring
Setter 남발 금지
@Data어노테이션이@Getter+@Setter등 편리하게 해주지만,
엔티티 클래스에서 @Setter를 무분별하게 남용하게 되면 객체의 일관성이 떨어지게 됩니다.
( 어디에서 값을 변경했는지 찾을수가 없음 )
생성자 설정 (파라미터 값이 많을 경우)
public User(String name, String address, Integer age)
- 이펙티브 자바 서적에서는 파라미터가 많을경우 여러 메소드로 분리 하라는 방법이 있습니다.
- Spring 에서는
@Builder어노테이션을 사용해 빌더 패턴을 적용하여 해결하면 될 것 같습니다.
쿼리 컴포넌트

URL 구조에서
?뒤는 쿼리 컴포넌트를 의미합니다.
- 쿼리 컴포넌트는 서버에 동적으로 자원을 요구하거나, 자원의 표현 형식을 변환하는 정보를 포함하는데 활용하게 됩니다.
http:///example.com/path?query=keyword&limit=20
- 쿼리컴포넌트는
<Key, Value>쌍으로 인자를 전달하며&로 각 인자를 구분합니다.
@GetMapping("/path")
public Map<String, Object> queryParams(
@RequestParam("query") String query,
@RequestParam("limit") Integer limit
)@RequestParm어노테이션을 사용하여 위의 URL로 요청을 보내게 되면, query에는 keyword 문자열이 할당되고, limit에는 20이 할당 됩니다.
Pagination (페이징)
- 조회할 데이터 갯수가 많을때 갯수를 한정 시키는 기법이며,
조회할 데이터의 갯수가 줄어들기 때문에 성능 향상을 기대할수 있습니다.
Spring Data Jpa를 활용
- 쿼리 메소드를 작성하여
SQL문을 배정할수 있습니다.
EX : findTop20ByOrderByIdDesc();
➡ Spring Data Jpa를 사용하는 방법은 추천하지 않는 방법이라고 합니다.
(조회할때 기준이 되는 ID를 클라이언트가 제공하면서 기준을 만들어야 함)
Pageable 사용
- 많이 사용하는 방법이라고 합니다.
- Page와 Size를 설정하여 갯수를 제한하여 조회합니다.

