01-1 인공지능과 머신러닝, 딥러닝
인공지능이란?
사람처럼 학습하고 추론할 수 있는 지능을 가진 컴퓨터 시스템을 만드는 기술
인공지능 태동기 -> 인공지능 황금기 -> 첫 번째 AI 겨울 -> 두 번째 AI 겨울 -> 현재
인공일반지능 (Artificial General Intelligence) / 강인공지능 (Strong AI) : 영화 속의 인공지능
약인공지능 (Weak AI) : 현실에서 우리가 마주하고 있는 인공지능. 특정 분야에서 사람의 일을 도와주는 보조 역할
머신러닝이란?
규칙을 일일이 프로그래밍하지 않아도 자동으로 데이터에서 규칙을 학습하는 알고리즘을 연구하는 분야
인공지능의 하위 분야 중에서 지능을 구현하기 위한 소프트웨어를 담당하는 분야
오픈소스 통계 소프트웨어 R / 컴퓨터 과학 분야의 대표적인 머신러닝 라이브러리 사이킷런 (Scikit-learn) (Python 기반)
딥러닝이란?
머신러닝 알고리즘 중 인공 신경망 (Artificial neural network)를 기반으로 한 방법들을 통칭
LeNet-5, AlexNet
복잡한 알고리즘을 훈련할 수 있는 풍부한 데이터와 컴퓨터 성능의 향상, 그리고 혁신적인 알고리즘 개발
딥러닝 라이브러리 : 구글의 텐서플로 vs 페이스북(메타)의 파이토치. 두 라이브러리 모두 파이썬 API 제공
01-2 코랩과 주피터 노트북
구글 코랩
클라우드 기반의 주피터 노트북 (Python 지원) 개발환경. 온라인 에디터라고 생각하면 편하다. 코랩 파일은 노트북 혹은 코랩 노트북이라고 부른다.
01-3 마켓과 머신러닝
k-최근접 이웃 알고리즘을 사용하여 2개의 종류를 분류하는 머신러닝 모델 훈련하기
생선 분류 문제
도미 데이터 준비하기
머신러닝은 기준을 찾을 뿐만 아니라 이 기준을 이용해 생선이 도미인지 아닌지 판별도 가능하다. 머신러닝은 여러 개의 도미 생선을 보면 스스로 어떤 생선이 도미인지를 구분할 기준을 찾는다.
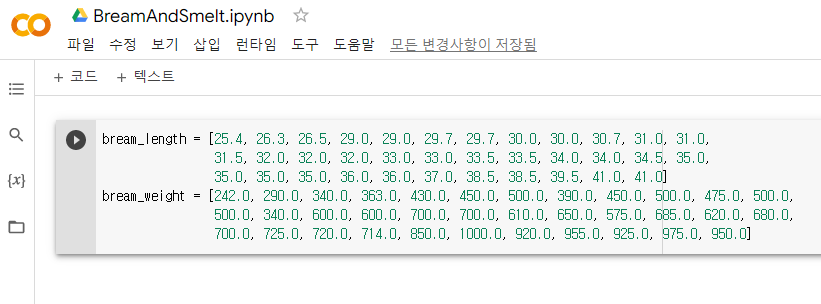
이렇게 일단 35마리의 도미를 준비한 후, 도미의 길이(cm)와 무게(g)을 Python list로 만든다고 하자.여기서 길이와 무게 등의 특징을 특성(feature)라고 한다.
이러한 특성들의 관계를 그래프에 점으로 표시한 것을 산점도 (scatter plot)이라고 한다.
Python에서 과학계산용 그래프를 그리는 대표적인 package를 맷플롯립(matplotlib)이라고 한다. 이 package를 import하고 산점도를 그리는 scatter() 함수를 사용해보자.

그러면 이런 2차원 그래프가 생성되는데 이렇게 일직선에 가까운 형태로 나타나는 경우를 선형적(linear)이라고 말한다.
빙어 데이터 준비하기
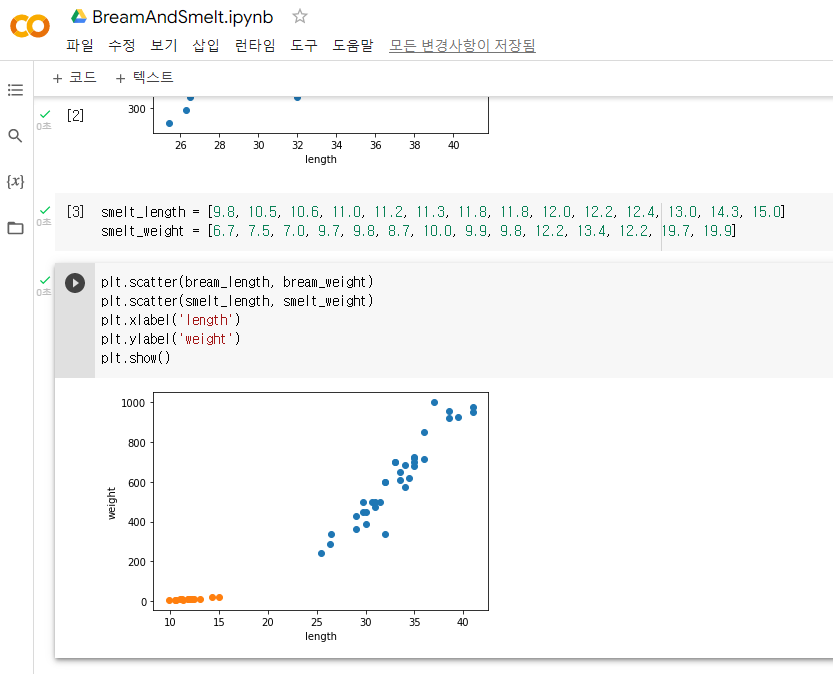
이렇게 빙어 데이터를 추가한 후 도미 데이터와 빙어 데이터를 한꺼번에 산점도를 나타내 보았다. 하지만 그래프에서 볼 수 있듯이, 빙어의 산점도는 선형적이지만 무게가 길이에 영향을 덜 받는다고 볼 수 있다.
첫 번째 머신러닝 프로그램
k-nearest neighbors 알고리즘 사용하여 도미와 빙어 데이터 구분해 보기
1. 준비한 도미와 빙어 데이터를 하나의 데이터로 합치기
length = bream_length + smelt_length
weight = bream_weight + smelt_weight이 때 데이터를 세로 방향으로 늘어뜨린 2차원 리스트를 만들기 위해 zip() 함수를 사용한다.

그러면, 이렇게 [l,w]가 하나의 원소로 구성된 2차원 리스트가 만들어진다.
2. 정답 데이터 만들기
fish_target = [1]*35 + [0]*14
print(fish_target)그 다음 사이킷런 패키지에서 k-최근접 알고리즘 구현한 클래스인 KNeighborsClassifier 임포트 + 이 클래스의 객체 만든 후 fish_data와 fish_target 사용하여 훈련시키기
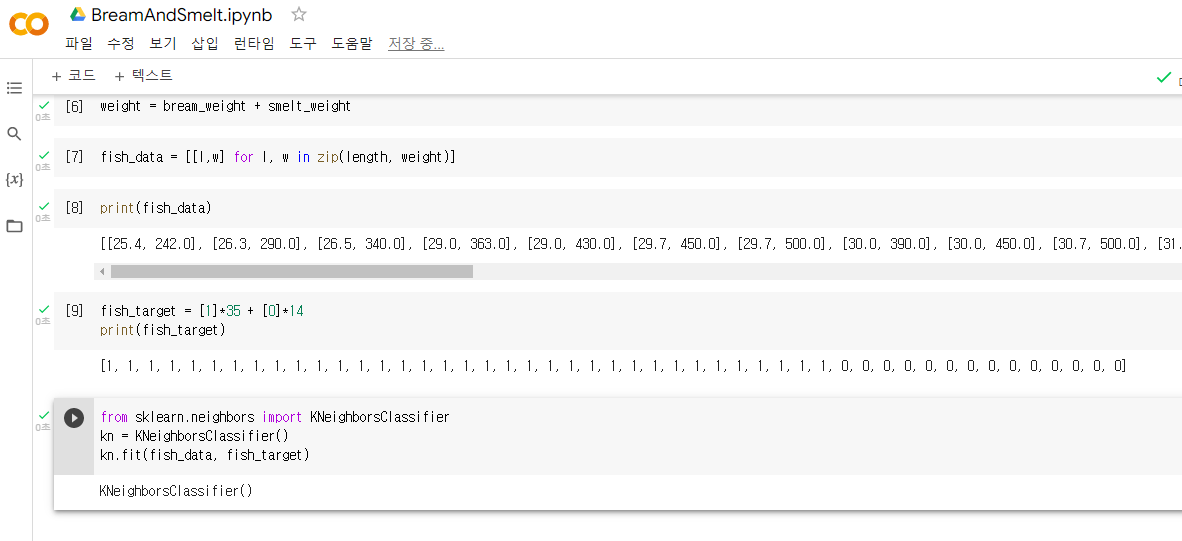
3. 훈련된 데이터 평가하기
출력값을 정확도라고 부르는데, 1.0이므로 모든 데이터에 대해 답을 맞췄다는 뜻이다.
k-최근접 이웃 알고리즘
새로운 데이터에 대해 예측할 때, 가장 가까운 직선거리에 있는 데이터들을 고려하여 결과값을 출력하는 알고리즘이다.
하지만 알고리즘의 이런 특징으로 인해 데이터가 아주 많은 경우 사용하기 어렵다. 데이터가 크기 때문에, 메모리가 많이 필요하고 직선거리를 계산하는 데 많은 시간이 필요하기 때문이다.
