LEARNING CONTINUOUS REPRESENTATION OF AUDIO FOR ARBITRARY SCALE SUPER RESOLUTION
1. Introduction
Suggesting Local Implicit representation for Super resolution of Arbitrary scale(LISA), which can obtain a continuous representation of audio and enable super resolution for arbitrary scale factor. (Current approaches treat audio as discrete data)
LISA
Encoder
Corresponds each chunk of audio to a latent code parameterizing a local input signal around the chunk. -> Don't get it. Isn't local input the chunk?
Decoder
Takes 1. a continuous time coordinate and 2. the neighboring set of latent codes around the coordinate, and predicts the value of signal at the coordinate
Process
- Down sample to the input resolution.
- Generate super resolution tasks of random scale up to the original resolution.
- Use a stochastic measure of audio discrepancy between entire reconstructed and original signals in waveform and spectrogram
- Closer discrepancy gets higher random weight
Thus, local latent code of a chunk captures a characteristic of the global audio signal, while focuses on the local signal around the chunk. -> HOW?
Advantages
Having the local implicit representation in terms of the low latency and the arbitrary scale factor as input audio is often streaming in audio super resolution. -> What does 'streaming' mean in this context? Flows?
2. Method
Compositions
- : Audio
- 's in every sampling period , where is input resolution
- : local part of discrete samples around
- : encoder with parameter
- : decoder with parameter
- i.e. (2k+1) samples around time
- , where , i.e. is the closest index to
: continuous representation
LISA 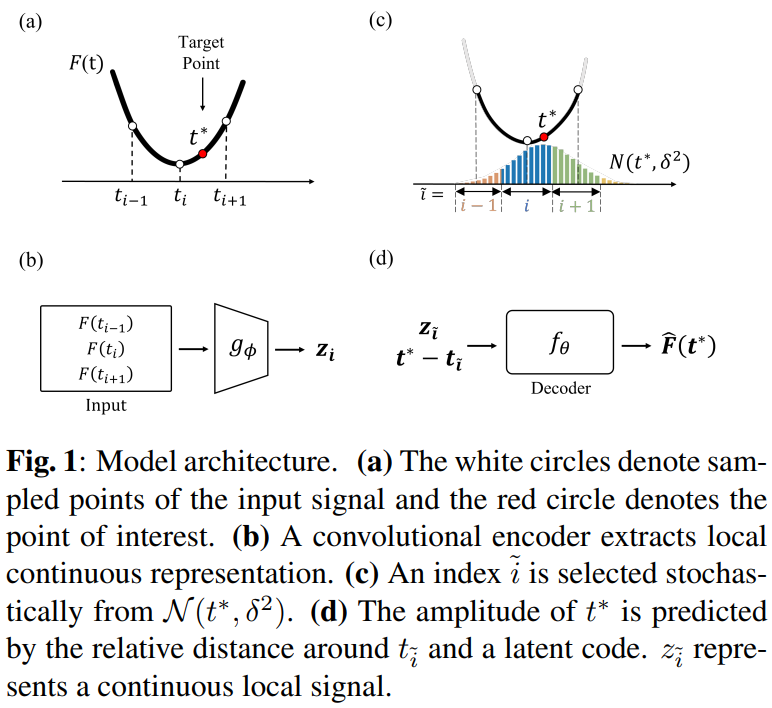
Note that,
Output prediction
By putting the sequence of time coordinates every to
-> Don't get it
2.1 Model Architecture
Encoder
- Convolutional network
- Induces temporal correlation, by summarizing a few consecutive data points.
