Elasticsearch
- Reference
- What is Elasticsearch?
https://www.elastic.co/guide/en/elasticsearch/reference/current/elasticsearch-intro.html - [ Elasticsearch ] 엘라스틱 서치 가볍게 살펴보는 개념 :)
https://www.youtube.com/watch?v=MWItWo67F14 - [ELK 스택] 03. 엘라스틱서치 기본 개념 정리
https://www.youtube.com/watch?v=B1Aq2GQ4E78 - Elastic Stack 제품 및 기능 소개
https://www.youtube.com/watch?v=CU2hFK5ZMYA - [엘라스틱서치 알아보기 #2] DB만 있으면 되는데, 왜 굳이 검색엔진?
https://velog.io/@jakeseo_me/엘라스틱서치-알아보기-2-DB만-있으면-되는데-왜-굳이-검색엔진 - [DB기초] 트랜잭션이란 무엇인가?
https://coding-factory.tistory.com/226
- What is Elasticsearch?
왜 Elasticsearch는 검색이 빠를까?
-
기존 RDBMS와 데이터를 저장하는 방식이 다르다.
-
각 value(text)들이 포함된 document들을 나열한다.
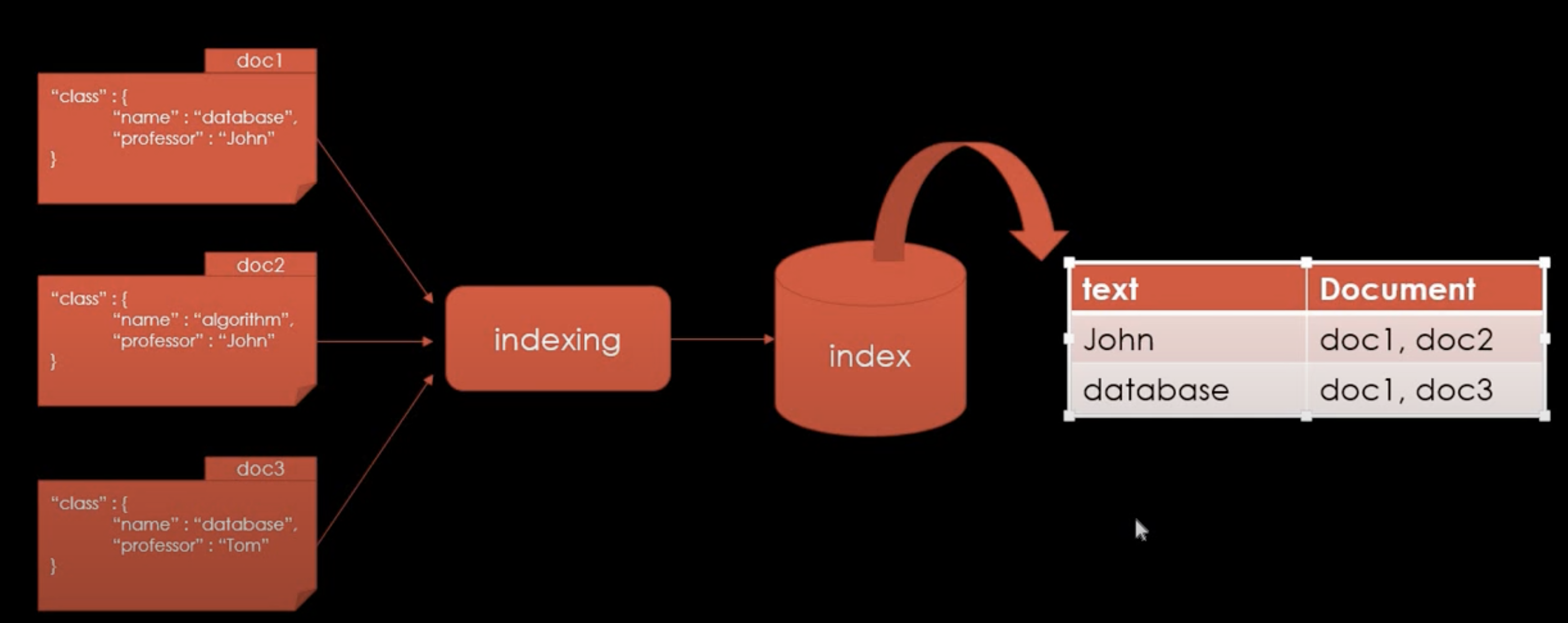
-
위 그림은 document들이 indexing되어 (text, documents)란 key, value 형태로 mapping 되는 과정을 설명한다.


-
RDB와의 다른 점들을 비교하면 위 표와 같고, 추가로 아래와 같이 대응된다.
- Shard — Partition
- Query DSL — SQL
그렇다면 Elasticsearch의 단점은?
- 진입 장벽이 있다.
- Document 간 조인을 수행할 수 없다. (두번 쿼리로 해결 가능)
- 트랜잭션 및 롤백이 제공되지 않는다.
- 실시간 처리가 불가능하다. (색인된 데이터가 1초 뒤에나 검색이 가능하다.)
- 진정한 의미의 업데이트를 지원하지 않는다. (물론 있지만, 삭제했다가 다시 만드는 형태)
일반적으로 사용하는 아키텍처
-
아래와 같이 특정 서버에서 생성되는 데이터를 RDBMS or Non-RDBMS에 저장을 하고, 검색 혹은 분석이 필요한 부분만을 데이터를 추출하여 Elasticsearch에 자동 저장시킨다.
-
이때 기존 DB에서 Elasticsearch로 자동 저장하는, 즉 ETL 기능을 하는 것이 바로 logstash이다.
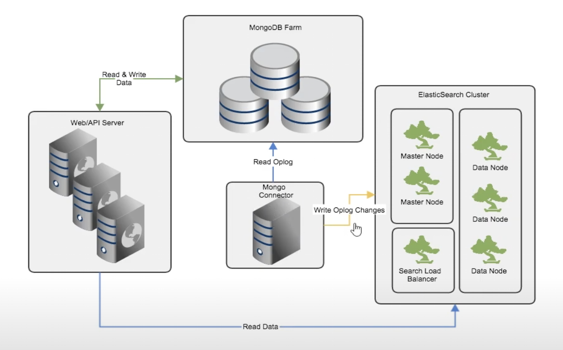
-
위 그림에서 Mongo Connector에 해당하는 부분이 바로 logstash이다.
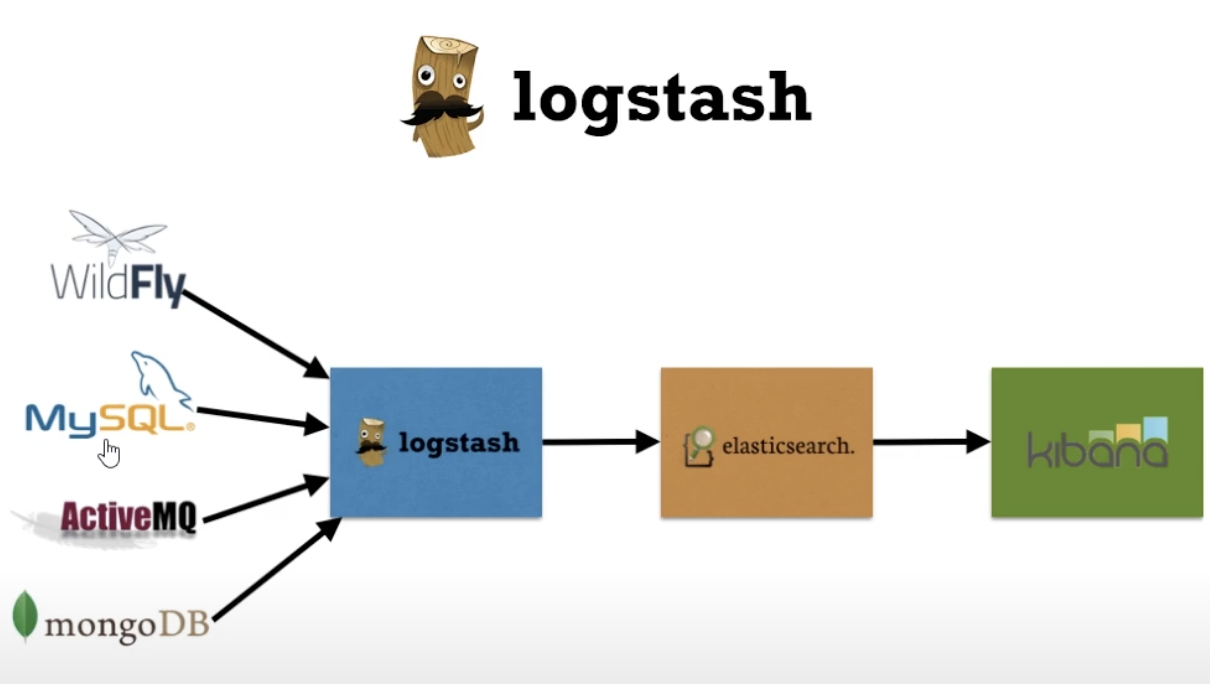
전체적인 Elastic Stack

- Elasticsearch - 데이터를 저장하고 쿼리를 하고 검색을 하고 분석을 하는 모든 처리 담당
- Kibana - 시각화 및 분석을 위한 클라이언트 도구
- Beats, Logstash - 데이터 수집 도구
- Logstach - 다양한 데이터시스템들로부터 데이터를 수집하고 다시 전송할 수 있는 ETL 도구. 모든 데이터 소스가 있는 장비에 설치하여야 한다.
- Beats - 위 모든 장비에 설치해야 하는 점을 극복한 제품. 로그 데이터 전달. 중앙화하기 위한 프로그램
고가용성, 분산 시스템
-
Elasticsearch 클러스터링 과정
-
Elasticsearch를 실행하면 실행된 단일 프로세스를 노드라고 한다.
-
샤드(Shard) 단위로 분리해서 저장한다.
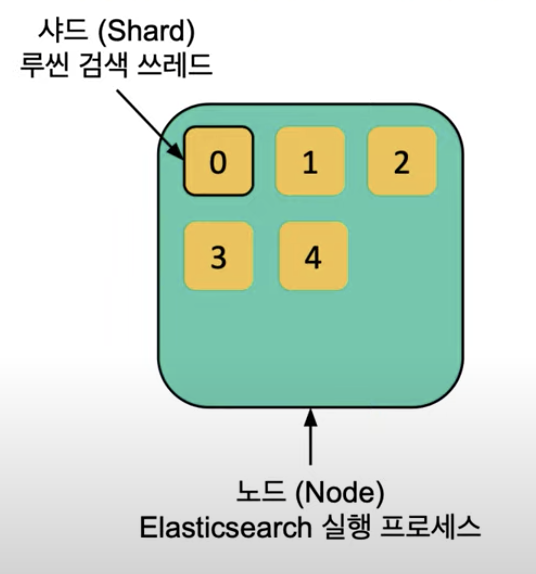
-
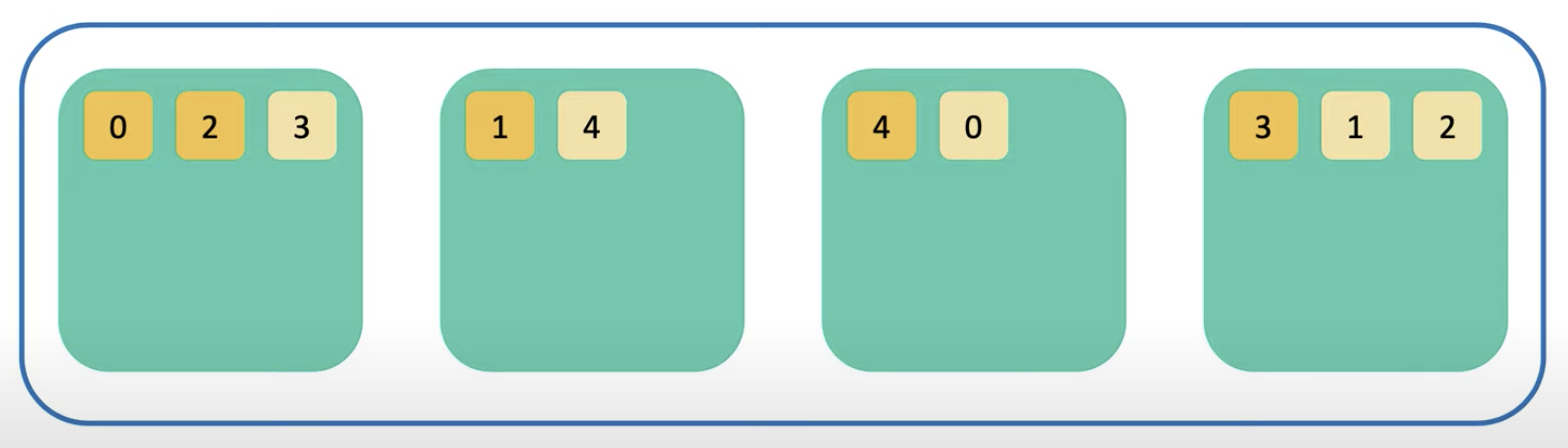
노드 내 데이터가 쌓이게 되면, 여러 개의 노드를 띄워서 하나의 클러스터로 묶을 수 있다. 즉, 가장 큰 시스템의 단위가 클러스터이다.
-
여러 개의 노드가 생기면서 relocation이 발생한다.
-
노드가 무결점과 가용성을 위해 샤드의 복제본을 만든다.
-
하나의 노드가 죽게 되었을 때, 복제본이 없는 샤드들은 또 다시 살아있는 노드로 복제된다.
-
-
검색 과정
- Query Phase
- 처음 쿼리 수행 명령을 받은 노드는 모든 샤드에게 쿼리를 전달한다. 1차적으로 모든 샤드 검색을 실행한다.
- 각 샤드들은 요청된 크기만큼의 검색 결과 큐를 노드로 리턴합니다. 리턴된 결과는 루씬 doc id와 랭킹 점수만 가지고 있습니다.
- Fetch Phase
- 노드는 리턴된 결과들의 랭킹 점수를 기반으로 정렬한 뒤 유효한 샤드들에게 최종 결과들을 다시 요청한다.
- 결과적으로 전체 문서 내용 등의 정보가 리턴되어 클라이언트로 전달된다.
- Query Phase
Full Text 검색이 가능하다
- RDBMS의 데이터 저장 형태

- inverted index라는 구조로 텍스트를 다 뜯어서 검색어 사전을 만든다. (Term이라고도 한다)
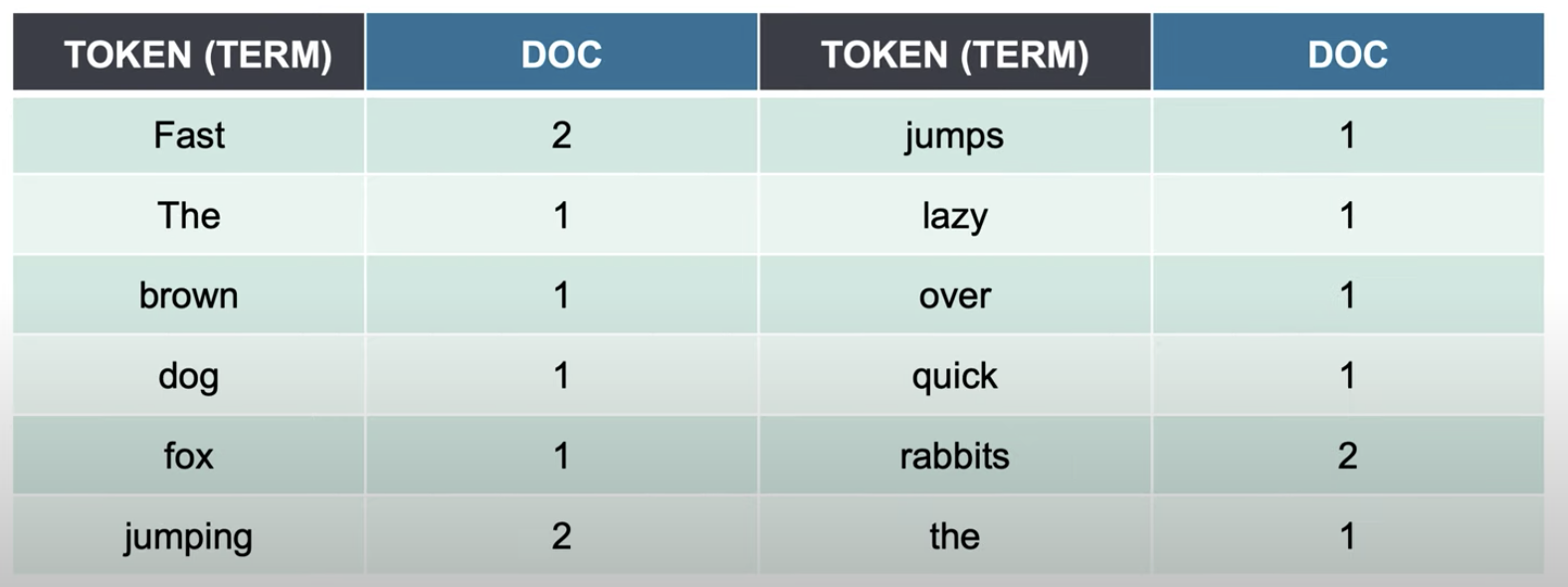
- 따라서 Text Analysis에서 특히 효과적이다. 한국어 형태소 분리도 가능하다고 한다.
- 실제로 저장되는 형태는 아래와 같다.
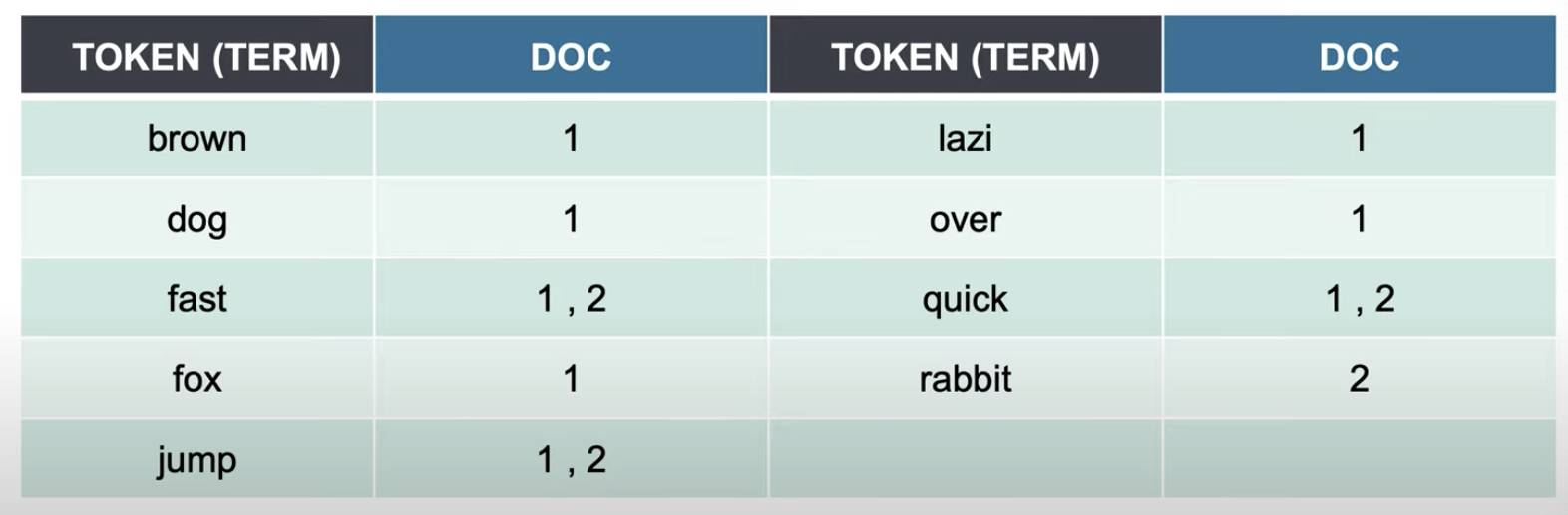
공식 Document 내 설명 (추가 보완적인)
- Index는 최적화된 문서 집합으로 생각할 수 있으며, 각 문서는 데이터를 포함하는 키-값 쌍인 필드 집합이다. 기본적으로 Elasticsearch는 모든 필드 내 모든 데이터를 indexing하고 각 indexing된 필드에는 최적화된 전용 데이터 구조가 있다. 예를 들어 텍스트 필드는 반전된 index로 저장되고 숫자 및 지역 필드는 BKD 트리에 저장된다.
- 또한 고유한 매핑을 따로 정의하여 수행할 수 있다. (자동 감지 불가능한 데이터 포맷 및 사용자 지정 날짜 형식 등)
- 진정한 강점은 엄청난 Apache Lucene 검색 엔진 라이브러리로 구축된 검색 기능에 쉽게 액세스할 수 있다는 것이다. (REST API를 통해)
- Structured Query 가능 (= SQL) 그리고 Full-text Query (= 전체 데이터 match) 등 검색도 분석도 뛰어나다. (실제로 사용해봐야 그 한계를 알 수 있겠다)
팀원이 알려준 추가 보완 사실
- v7.0 이후로 index 당 type이 하나만 제공되므로 서로 같은 취급을 해도 된다.
- 클러스터는 독립적인 시스템으로 서로 다른 클러스터에 접근 교환이 안된다.
- 노드는 하나의 단위 프로세스로 고유 id를 가지고 있고, 그 역할에 따라 4가지 종류로 나뉜다.
- Master Node
- 클러스터를 관리하는 노드로 인덱스를 생성/삭제하는 등 클러스터와 관련된 전반적인 작업을 담당하는 노드
- 가장 성능이 좋고 네트워크 속도가 빠르며 지연이 없는 노드를 선정해서 사용
- 다수의 노드를 설정할 수 있지만 하나의 노드만 선출되어 동작
- Data Node
- 실질적인 데이터를 저장하여 검색과 통계같은 데이터 관련 작업 수행
- 마스터와 분리해서 구성하는 것을 추천(리소스를 많이 소모하므로 모니터링이 필요하다)
- Coordinating
- 사용자의 요청을 받아서 클러스터 관련 요청을 마스터 노드에 전달 + 데이터 관련 요청은 데이터 노드에 전달
- 들어오는 요청을 Round Robin 방식으로 분산
- Ingest
- 문서 전처리 작업을 담당하며 인덱스 생성 전 문서의 데이터 포맷을 변경하기 위해 스크립트로 전처리 파이프라인 구성하고 실행 가능
개발자로 일하는 김찬영입니다.
덕분에 좋은 내용 잘 보고 갑니다.
정말 감사합니다.