
공공 데이터들이 데이터베이스 서버에 저장되어 있고, dba 들은
데이터를 저장, 관리, 백업, 튜닝 하는 일을 합니다.
출생아수와 학교에 입학한 학생의 수가 서로 일치하지 않는다.
산부인과에서 태어난 출생아수와 나라에 신고한 출생아수가 서로 일치하지 않는다.
SQL 공공 데이터
A 공공 기관 B 공공기관
DB서버 -------------- DB 서버
DB링크
테이블 테이블
▣ 043 데이터 분석 함수로 등급 출력하기(NTILE)
어제 배운 rank 와 dense_rank 는 데이터의 순위를 구하는 함수이고
ntile 은 데이터의 등급을 부여하는 데이터 분석 함수 입니다.
예: 이름과 월급과 월급에 대한 등급을 부여하시오 !
( 월급에 대한 등급이 4등급으로 나눠서 등급을 부여하시오 )
0~25%
25~50%
50~75%
75~100%
select ename, sal, ntile(4) over ( order by sal desc ) as 등급
from emp;
문제218. 이름, 입사일, 등급을 출력하는데 등급이 먼저 입사한 사원순으로
5등급으로 나눠서 출력하시오 !
select ename, hiredate, ntile(5) over ( order by hiredate asc ) as 등급
from emp;문제219. 위의 결과에서 등급이 2등급만 출력하시오 !
( 어제 배운 from 절의 서브쿼리를 이용해야 합니다 )
select ename, hiredate, 등급
from (
select ename, hiredate,
ntile(5) over ( order by hiredate asc ) as 등급
from emp)
where 등급 = 2 ;▣ 044 데이터 분석 함수로 순위의 비율 출력하기(CUME_DIST)
특정 데이터의 성적이 상위 몇 퍼센트인지를 보고 싶을 때 사용하는 함수
예: 이름, 월급, 월급에 대한 순위, 순위에 대한 비율을 출력하시오 !
select ename, sal, rank() over ( order by sal desc ) as 순위,
rank() over ( order by sal desc ) / 14 as 비율
from emp;
위와 같이 SQL을 작성하려면 14를 미리 알고 있어야 합니다.
회사의 데이터베이스는 지금 이 시간에도 데이터가 계속 insert 되므로
위와같이 14라고 숫자를 쓸 수 없습니다.
그렇다고 다음과 같이 count(*) 을 쓰니까 에러가 발생합니다.
select ename, sal, dense_rank() over ( order by sal desc ) as 순위,
dense_rank() over ( order by sal desc ) / count(*) as 비율
from emp;
그래서 필요한 데이터 분석함수가 cume_dist 입니다.
select ename, sal, rank() over ( order by sal desc ) as 순위,
cume_dist() over ( order by sal desc ) as 순위비율
from emp;
문제220. 위의 결과를 다시 출력하는데 순위비율을 출력할 때 소수점 두번째 자리까지 출력되게 반올림해서 출력하시오 !
select ename, sal, dense_rank() over ( order by sal desc ) as 순위,
round( cume_dist() over ( order by sal desc), 2 ) as 순위비율
from emp;
문제221. (복습문제) 직업, 직업별 최대월급을 출력하는데 직업별 최대월급이
높은것부터 출력하시오 !
select job, max(sal)
from emp
group by job
order by 2 desc;
▣ 045 데이터 분석 함수로 데이터를 가로로 출력하기(LISTAGG)
예제. 부서번호, 부서번호별로 해당하는 사원들의 이름을 가로로 출력하시오!
select deptno, listagg( ename, ',' ) within group ( order by ename asc )
from emp
group by deptno ;
※ listagg 함수는 다른 분석함수와는 다르게 group by 절이 필요 합니다.

문제222. 직업, 직업별로 속한 사원들의 이름을 가로로 출력하시오 !
( 이름은 abcd 순서데로 출력하시오 )
select job, listagg( ename, ',' ) within group ( order by ename asc ) as name
from emp
group by job;
문제223. 입사한 년도(4자리), 입사한 년도별로 속한 사원들의 이름을 가로로 출력하시오 ! ( 입사한 년도별로 월급이 높은 사원순으로 출력 )
select to_char( hiredate, 'RRRR'),
listagg( ename, ',' ) within group ( order by sal desc ) as name
from emp
group by to_char(hiredate, 'RRRR') ;
DB 엔지니어 ----> DBA -----> SQL튜너
-----> 프리랜서(DBA, 튜너)문제224. 통신사 컬럼의 데이터를 일괄적으로 제대로 UPDATE 를 수행하겠습니다.
update emp17
set telecom = 'sk'
where lower( substr( telecom, 1, 2 ) ) ='sk';
commit;
update emp17
set telecom ='lg'
where lower( substr(telecom, 1, 2) ) = 'lg';
commit;
update emp17
set telecom ='kt'
where lower( substr( telecom, 1, 2 ) ) ='kt';
commit;
select telecom from emp17;
문제225. 통신사, 통신사별로 속한 학생들의 이름을 가로로 출력하는데
이름이 나이가 높은 순서데로 정렬되어서 출력되게하시오 !
통신사 이름
kt
lg
sk
select telecom, listagg( ename, ',' ) within group ( order by age desc) as name
from emp17
group by telecom;
문제226. (미리 내는 점심시간 문제) 서울시청에서 근무하는 공무원분이 구현해달라고 했던 SQL ? 다음과 같이 이름 옆에 나이가 출력되게
하세요! ( 힌트: 연결 연산자 || 를 활용하세요 )
통신사 이름
kt 안초룡(40) ,김준혁(38) ,서원길,윤성해,이효진
lg 이해인,양희림,이상화,김기찬,김지혜
sk 김동휘,김정명,김하람,김희선,송현민,최서우,정범우,윤영민,이승휘
select telecom, listagg( ename || '(' || age || ')', ',' )
within group ( order by age desc) as name
from emp17
group by telecom;▣ 046 데이터 분석 함수로 바로 전 행과 다음 행 출력하기(LAG, LEAD)
예제: 사원번호, 사원이름, 바로 전행의 사원번호, 바로 다음행의 사원번호를
출력하시오 !
select empno, ename,
lag( empno, 1 ) over ( order by empno asc ) as 이전행,
lead( empno, 1 ) over ( order by empno asc ) as 다음행
from emp;
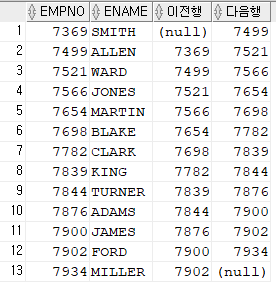
문제227. 사원이름, 이전행의 사원이름, 다음행의 사원이름을 출력하시오 !
select ename,
lag( ename, 1 ) over ( order by empno asc ) as 이전행,
lead( ename, 1 ) over ( order by empno asc ) as 다음행
from emp;
문제228. (회사의 인사팀의 SQL) 이름, 입사일, 바로 전에 입사한 사원의 입사일,
바로 다음에 입사한 사원의 입사일을 출력하시오 !
( 입사한 사원순으로 정렬되게 결과를 출력하시면 됩니다.)
select ename, hiredate, lag( hiredate, 1 ) over ( order by hiredate asc ),
lead( hiredate, 1 ) over ( order by hiredate asc )
from emp;
문제229. 사원 테이블에서 이름, 입사일, 바로 전에 입사한 사원과의 간격일을
출력하시오!
select ename, hiredate,
hiredate - lag( hiredate, 1 ) over ( order by hiredate asc ) as days
from emp;
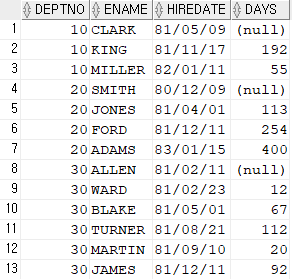
문제230. 부서번호, 이름, 입사일, 바로전에 입사한 사원과의 간격일을 출력하는데
간격일이 부서번호로 각각 출력되게 하시오 !
select deptno, ename, hiredate,
hiredate - lag( hiredate, 1 ) over ( partition by deptno
order by hiredate asc ) as days
from emp;
문제231. ( 복습문제 ) 부서번호, 부서번호별 토탈월급을 출력하는데
부서번호별 토탈월급을 출력할때 천단위 표시를 하시오 !
( 예: 5,000 )
select deptno, to_char( sum(sal), '999,999' )
from emp
group by deptno;
▣ 047 ROW 를 COLUMN 으로 출력하기 1(SUM+DECODE)
1. 행(row) ----> 컬럼(column) : sum + decode 또는 pivot 문
2. 컬럼(column) ---> 행(row) : unpivot 문예제. 부서번호, 부서번호별 토탈월급을 출력하시오 !
select deptno, sum(sal)
from emp
group by deptno;
예제. 위에서 출력되는 행의 데이터가 컬럼이 되어서 다음과 같이 출력되게하시오
10 20 30 <----- 컬럼명
8750 10875 9400 <---- 데이터문제232. 부서번호, decode 를 이용해서 부서번호가 10번이면 월급이 나오게 하고 아니면 0 이 나오게 하시오 !
select sum( decode( deptno, 10, sal, 0 ) ) as "10"
from emp;
문제233. 위의 출력되는 결과 옆에 20번의 토탈월급과 30번의 토탈월급도
같이 출력하시오!
select sum( decode( deptno, 10, sal, 0 ) ) as "10" ,
sum( decode( deptno, 20, sal, 0 ) ) as "20" ,
sum( decode( deptno, 30, sal, 0 ) ) as "30"
from emp;
※ 컬럼별칭을 숫자로 출력하려면 양쪽에 더블 쿼테이션 마크를 사용해야합니다.
문제234. (세로 출력) 우리반 테이블에서 통신사, 통신사별 평균나이를 출력하시오
select telecom, avg(age)
from emp17
group by telecom;
문제235. (가로 출력) 우리반 테이블에서 통신사, 통신사별 평균나이를 가로로 출력하시오 !
kt lg sk
----------- ------------ ------------
33.2 29.2 29.4
select avg( decode(telecom, 'kt', age, null) ) as "kt",
avg( decode(telecom, 'lg', age, null) ) as "lg",
avg( decode(telecom, 'sk', age, null) ) as "sk"
from emp17;
select sum(decode(telecom, 'kt', round(avg(age), 1), null)) as "kt",
sum(decode(telecom, 'lg', round(avg(age), 1), null)) as "lg",
sum(decode(telecom, 'sk', round(avg(age), 1), null)) as "sk"
from emp17
group by telecom;
--> 그냥 안좋은 답이다!!!!!!!!!!!!!!!!!!!!!!!select decode( telecom, 'kt', age, null ) as "kt",
decode( telecom, 'lg', age, null ) as "lg",
decode( telecom, 'sk', age, null ) as "sk"
from emp17;
- sum 을 사용한 첫번째 SQL select sum( decode( telecom, 'kt', age, null ) ) as "kt",
sum( decode( telecom, 'lg', age, null ) ) as "lg",
sum( decode( telecom, 'sk', age, null ) ) as "sk"
from emp17; select sum( decode( telecom, 'kt', age ) ) as "kt",
sum( decode( telecom, 'lg', age ) ) as "lg",
sum( decode( telecom, 'sk', age ) ) as "sk"
from emp17;
- sum 을 사용한 두번째 SQL select sum( decode( telecom, 'kt', age, 0 ) ) as "kt",
sum( decode( telecom, 'lg', age, 0 ) ) as "lg",
sum( decode( telecom, 'sk', age, 0 ) ) as "sk"
from emp17;
문제236. (세로출력) 직업, 직업별 토탈월급을 출력하시오 !
select job, sum(sal)
from emp
group by job;
문제237. (가로출력) 직업, 직업별 토탈월급을 출력하시오 !
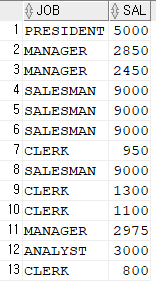
ANALYST CLERK MANAGER PRESIDENT SALESMAN
--------- ------ -------- -------- --------
6000 4150 8275 5000 5600
select deptno, sum( decode( job,'ANALYST', sal, null ) ) as ANALYST,
sum( decode( job, 'CLERK', sal, null ) ) as CLERK,
sum( decode( job, 'MANAGER', sal, null) ) as MANAGER,
sum( decode( job, 'PRESIDENT', sal, null ) ) as PRESIDENT,
sum( decode( job, 'SALESMAN', sal, null) ) as SALESMAN
from emp
group by deptno;
--> deptno를 없애면 된다!※ 고수가 있는 회사는 위의 SQL을 PL/SQL 로 구현 합니다.
create or replace procedure
get_data(p_x out sys_refcursor)
as
l_query varchar2(400) :='select deptno ';
begin
for x in (select distinct job from emp order by 1)
loop
l_query := l_query ||replace(', sum(decode(job,''$X'',sal)) as $X '
,'$X',x.job );
end loop;
l_query := l_query ||' from emp group by deptno ';
open p_x for l_query;
end;
/
variable x refcursor;
exec get_data(:x);
print x;
※ Oracle 고수들이 있는 회사는 위와같이 procedure 를 이용해서 출력합니다.문제238. (세로출력) 입사한 년도(4자리), 입사한 년도별 토탈월급을 출력하시오!
select to_char( hiredate, 'RRRR') , sum(sal)
from emp
group by to_char( hiredate, 'RRRR') ;
문제239. (가로출력) 입사한 년도(4자리), 입사한 년도별 토탈월급을 출력하시오 !
1980 1981 1982 1983
-------- --------- --------- --------
800 22825 4300 1100
select sum( decode( to_char( hiredate, 'RRRR') , '1980', sal, null ) ) as "1980",
sum( decode( to_char( hiredate, 'RRRR') , '1981', sal, null ) ) as "1981",
sum( decode( to_char( hiredate, 'RRRR') , '1982', sal, null ) ) as "1982",
sum( decode( to_char( hiredate, 'RRRR') , '1983', sal, null ) ) as "1983"
from emp;문제240. 위의 결과에서 직업도 앞에 추가하고 직업별로 group by 하시오!
select job,
sum( decode( to_char( hiredate, 'RRRR') , '1980', sal, null ) ) as "1980",
sum( decode( to_char( hiredate, 'RRRR') , '1981', sal, null ) ) as "1981",
sum( decode( to_char( hiredate, 'RRRR') , '1982', sal, null ) ) as "1982",
sum( decode( to_char( hiredate, 'RRRR') , '1983', sal, null ) ) as "1983"
from emp
group by job;
문제241.(세로출력) 우리반 테이블에서 통신사, 통신사별 인원수를 출력하시오!
select telecom, count(*)
from emp17
group by telecom;
문제242. (가로출력) 우리반 테이블에서 통신사, 통신사별 인원수를 출력하시오!
kt lg sk
--------- ---------- ----------
5 5 9
select sum( decode( telecom , 'kt', 1, null ) ) as "kt",
sum( decode( telecom , 'lg', 1, null ) ) as "lg",
sum( decode( telecom, 'sk', 1, null ) ) as "sk"
from emp17;
또는
select count( decode( telecom , 'kt', empno, null ) ) as "kt",
count( decode( telecom , 'lg', empno, null ) ) as "lg",
count( decode( telecom, 'sk', empno, null ) ) as "sk"
from emp17;문제243. 위의 SQL을 가지고 다음과 같이 결과를 출력하시오 !
select substr(address, 1, 3) as 주소,
count( decode( telecom , 'kt', empno, null ) ) as "kt",
count( decode( telecom , 'lg', empno, null ) ) as "lg",
count( decode( telecom, 'sk', empno, null ) ) as "sk"
from emp17
group by substr( address, 1, 3 );
위와 같이 SQL을 작성하면 너무 하드코딩하게 되므로 좀더 심플하게 작성하게 하는 데이터 분석 함수를 제공합니다.
▣ 048 ROW 를 COLUMN 으로 출력하기 2(PIVOT)
→ ORA-56902: 피벗 작업 내에서는 합계 함수가 필요합니다.
- row -------------> column : pivot 문
- column ----------> row : unpivot 문
예제. 부서번호, 부서번호별 토탈월급을 가로로 출력하는데 pivot 문을 이용하세요.
select *
from ( select deptno, sal from emp )
pivot ( sum(sal) for deptno in ( 10, 20, 30 ) );
문제244. 직업, 직업별 토탈월급을 가로로 출력하는데 pivot 문을 써서 구현하시오
select *
from ( select job , sal from emp )
pivot ( sum(sal) for job in ( 'ANALYST' as "ANALYST",
'CLERK' as "CLERK",
'MANAGER' as "MANAGER",
'SALESMAN' as "SALESMAN",
'PRESIDENT' as "PRESIDENT" ) );

문제245. 아래의 괄호 안에 넣은 SQL을 작성하시오!
select *
from ( select job , sal from emp )
pivot ( sum(sal) for job in ( ) );
위의 SQL에 괄호안에 넣을 하드코딩할 리터럴 문자들을 아래의 SQL로 생성하면
쉽게 Pivot 문을 작성할 수 있습니다.
select '''' || job2 || '''' || ' as ' || '"' || job2 || '"' || ','
from ( select distinct job as job2
from emp
);문제246. (복습문제) 직업, 직업별 인원수를 출력하는데 직업별 인원수가 3명이상인것만 출력하시오 ! (세로 출력)
select job, count(*) as 인원수
from emp
group by job
having 인원수 >= 3;
※ having 절에 컬럼별칭을 쓸 수 없습니다.
▣ 049 COLUMN 을 ROW 로 출력하기(UNPIVOT)
- unpivot 문 준비 데이터 create table order2
( ename varchar2(10),
bicycle number(10),
camera number(10),
notebook number(10) );
문법: select *insert into order2 values( 'SMITH', 2, 3, 1 ); insert into order2 values( 'ALLEN', 1, 2, 3 ); insert into order2 values( 'KING', 3, 2, 2 ); commit ;
from order2
unpivot ( 갯수2 for 아이템 in ( bicycle, camera, notebook) );
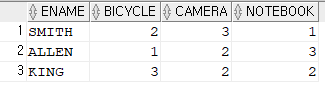
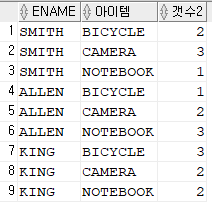
※ 갯수 와 아이템 한글글씨는 마음대로 작성해도 됩니다.
in 다음에 괄호안에 컬럼명 쓸 때 양쪽에 싱글 쿼테이션 마크를 쓰지 않습니다.
문제247. 위의 문법의 SQL의 결과를 담는 item2 라는 테이블을 생성하시오
create table item2
as
select *
from order2
unpivot ( 갯수2 for 아이템 in ( bicycle, camera, notebook) );
select * from item2;
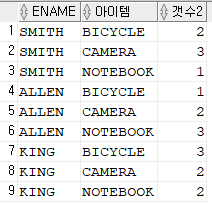
문제248. item2 에서 아이템, 아이템별 갯수2의 토탈값을 출력하시오 !
select 아이템, sum(갯수2)
from item2
group by 아이템;
※ unpivot 문이 필요한 이유가 데이터 분석을 위해서 데이터를 구하다 보면 raw 데이터를 구하기는 어렵고 이미 raw 데이터를 가지고 분석한 결과 테이블을 구할 수 있는 경우가 많습니다.
공공 데이터 포털에 올려진 데이터를 보면 주로 이미 pivoting 된 결과 데이터를 구할 수 있는 경우가 많습니다. 그런데 내가 원하는 데이터는 pivoting 전 데이터인 raw(날) 데이터를 원합니다.
select * from crime_time ; 에서 살인이 가장 많이 일어나는 시간대를 출력하시오
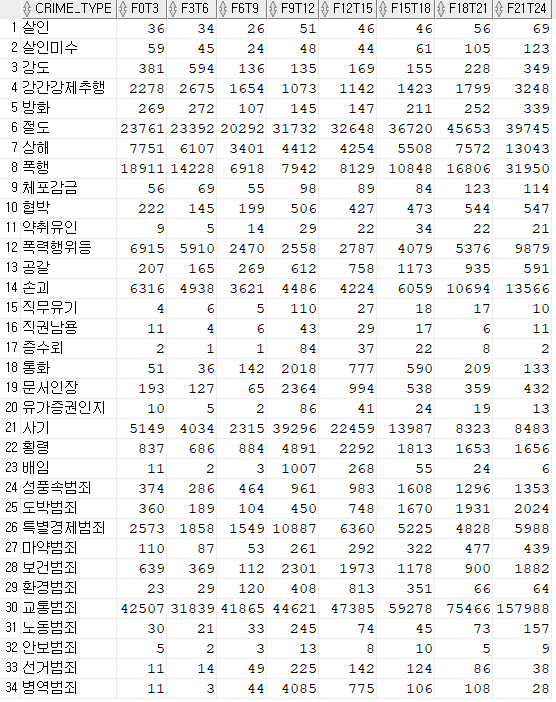
F21T24 <--- 이 결과가 출력되게 SQL을 작성하려면 unpivot 문을 써야 합니다.
문제249. 살인이 가장 많이 발생하는 시간대를 출력하시오 !
select *
from crime_time
unpivot ( 건수 for 시간 in ( F0T3
,F3T6
,F6T9
,F9T12
,F12T15
,F15T18
,F18T21
,F21T24 ) );
select *
from crime_time
unpivot( 건수 for 시간대 in (F0T3
,F3T6
,F6T9
,F9T12
,F12T15
,F15T18
,F18T21
,F21T24))
where crime_type = '살인'
order by 2 desc fetch first 1 row only;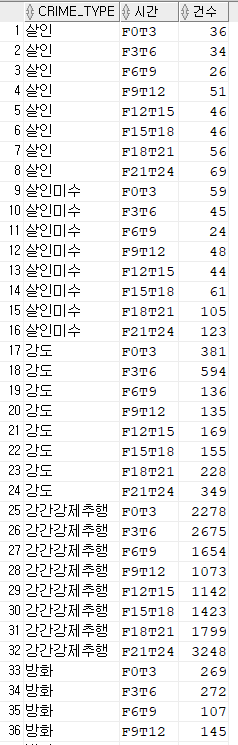

문제250. ( 오늘의 마지막 문제) 살인이 가장 많이 일어나는 시간대, 건수, 순위를 출력하시오
문제249번의 결과를 create table as 쿼리문;
을 써서 테이블로 생성하고 SQL을 작성하면 쉽게 구현할 수 있습니다.
create table unpivot_crime_time as
select crime_type, 시간, 건수
from crime_time
unpivot ( 건수 for 시간 in (F0T3, F3T6, F6T9, F9T12, F12T15, F15T18, F18T21, F21T24) );
select 시간 as 시간대, 건수, dense_rank() over (order by 건수 desc) as 순위
from unpivot_crime_time
where crime_type = '살인'
order by 건수 desc fetch first 1 row only;
select crime_type, 시간대, 건수, dense_rank() over (order by 건수 desc) as 순위
from (select *
from crime_time
unpivot( 건수 for 시간대 in (F0T3
,F3T6
,F6T9
,F9T12
,F12T15
,F15T18
,F18T21
,F21T24))
where crime_type = '살인')
order by 3 desc fetch first 1 row only;
