
문제348. (오늘의 마지막 문제) 다음과 같이 결과를 출력하세요 !
직업별 부서번호별 토탈월급들을 출력하는데 맨 옆과 맨 아래에 토탈값들을
출력하시오 !
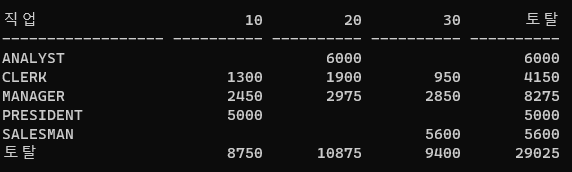
-- sum + decode
select nvl(job,'토탈') as 직업 , sum(decode(deptno,10,sal,null)) as "10",
sum(decode(deptno,20,sal,null)) as "20",
sum(decode(deptno,30,sal,null)) as "30",
sum(sal)as 토탈
from emp
group by rollup (job);
-- pivot
select nvl(job,'토탈')as 직업 ,sum("10") as "10", sum("20") as "20" ,
sum("30") as "30", sum(토탈) as 토탈
from(select job,deptno, sal, sum(sal) over (partition by job) as 토탈
from emp )
pivot (sum(sal) for deptno in(10,20,30))
group by rollup (job)
order by job asc;
두개 다 성능차이는 없다고 한다!※ pivot 문을 오라클이 sum + decode 를 사용한 SQL로 변환해서 수행합니다.
↓
Query transformation
SQL ---> parsing ---> Query transformation ----> 실행계획 생성 --> 실행
↓ ↓
기계어로 변환 오라클이 SQL을 재작성→ 예를 들어 철자가 빠지면 파싱 과정 에서 걸린다, full outer join 같은 경우는 left outer join 후 union all을 하겠지!
select e.ename, d.loc
from emp e full outer join dept d
on ( e.deptno = d.deptno );
문제349. (SQL튜닝방법) 아래의 SQL을 집합 연산자(union all 또는 union) 와
right outer join 과 left outer join 으로 수행하시오 !
insert into emp(empno, ename, sal )
values( 1234, 'JACK', 70 );
select e.ename, d.loc
from emp e full outer join dept d
on ( e.deptno = d.deptno );
답:
튜닝전:
select /+ gather_plan_statistics / ename, loc
from (
select e.rowid as rw, e.ename, d.loc
from emp e left outer join dept d
on ( e.deptno = d.deptno )
union
select e.rowid as rw, e.ename, d.loc
from emp e right outer join dept d
on ( e.deptno = d.deptno )
order by rw asc
);
SELECT * FROM TABLE(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
버퍼의 갯수 : 24개
튜닝후:
select /+ gather_plan_statistics / e.ename, d.loc
from emp e full outer join dept d
on ( e.deptno = d.deptno );
SELECT * FROM TABLE(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
버퍼의 갯수 : 12개
※ rowid 란 ? 테이블의 행의 논리적 주소 ( file# + block# + row# )
▣ 069 집합 연산자로 데이터의 교집합을 출력하기(INTERSECT)
- 집합 연산자 4가지
- union all
- union
- intersect : 두 집합 사이의 교집합을 출력합니다.
- minus
예제:
select deptno, sum(sal)
from emp
where deptno in ( 10, 20 )
group by deptno
intersect
select deptno, sum(sal)
from emp
where deptno in ( 20, 30 )
group by deptno ;
문제350. market_2017 과 market_2022 의 건수를 각각 count 하시오 !
select count() from market_2017;
select count() from market_2022;
문제351. market_2017 테이블에서 상호명이 카페베네를 포함하고 있는
상가업소번호, 상호명을 출력하시오 !
select 상가업소번호, 상호명
from market_2017
where 상호명 like '%카페베네%';
문제352. market_2022 테이블에서 상호명이 카페베네를 포함하고 있는
상가업소번호, 상호명을 출력하시오 !
select 상가업소번호, 상호명
from market_2022
where 상호명 like '%카페베네%';
문제353. 2022년도에 있는 상호명 카페베네가 2017년도에도 있었던
상가업소번호와 상호명을 출력하시오 ! ( 2017년도와 2022년도의 교집합)
select 상가업소번호, 상호명
from market_2017
where 상호명 like '%카페베네%'
intersect
select 상가업소번호, 상호명
from market_2022
where 상호명 like '%카페베네%';
▣ 070 집합 연산자로 데이터의 차이를 출력하기(MINUS)
오라클의 차집합을 구할 때는 내부적으로 아래와 같이 정렬하고 차집합을
구합니다. 내부적으로 정렬하는 집합 연산자는 union, intersect, minus 입니다.
A B
deptno - deptno =
10 10
20 20
30 30
40
운영 DB 테스트 DB
emp ========> emp
insert
- 운영테이블과 테스트 테이블의 차이를 본다던가, 교집합을 볼 때 집합연산자를 사용한다문제354. 2017년도에는 존재했는데 2022년도에 사라진 카페베네 매장은
총 몇개인가 ?
select count(*)
from (
select 상가업소번호, 상호명
from market_2017
where 상호명 like '%카페베네%'
minus
select 상가업소번호, 상호명
from market_2022
where 상호명 like '%카페베네%'
);
문제355. 이번에는 스타벅스도 사라진 매장이 몇개인지 확인하시오 !
select count(*)
from (
select 상가업소번호, 상호명
from market_2017
where 상호명 like '%스타벅스%'
minus
select 상가업소번호, 상호명
from market_2022
where 상호명 like '%스타벅스%'
);
문제356. 짝꿍의 데이터 베이스의 emp 테이블을 조회하기 위해서
짝꿍의 아이피 주소를 알아내시오 !
내 피씨의 ip 주소 확인하는 방법 : 도스창 열고 ipconfig 라고 하세요!
192.168.19.29
192.168.19.21 <--- 준혁이 아이피 주소
내 ipconfig : 192.168.19.15
짝꿍 ipconfig : 192.168.19.13
자신의 디비 접속되었는지 확인
sqlplus c##scott/tiger@192.168.19.15:1521/xe
@ 아이피주소 : 포트번호 / DB이름
문제357. 자기 자신의 아이피주소로 자기 자신의 db 에 접속이 되는지를
먼저 확인합니다.
도스창을 열고 아래와 같이 접속합니다.
sqlplus c##scott/tiger@192.168.19.29:1521/xe
문제358. 짝꿍 db 로 접속 되는지 확인하세요 !
sqlplus c##scott/tiger@192.168.19.21:1521/xe
문제359. 내 sqldeveloper 에서 아래와 같이 짝꿍 db 의 테이블들을
조회할 수 있는 db 링크를 생성합니다.
create public database link dblink21
connect to c##scott
identified by tiger
using '192.168.19.21:1521/xe' ;
select * from emp@dblink21;
문제360. 내 emp 테이블에 랜덤으로 데이터를 한건 입력하시오 !
insert into emp(empno, ename, sal, job, deptno )
values( 2345, 'jane', 5000, 'dba', 90 );
commit;
문제361. 짝꿍의 emp 테이블과 나의 emp 테이블의 데이터의 차이가 뭐가 있는지
조회하시오 !
select from emp@dblink21
minus
select from emp;
▣ 071 서브 쿼리 사용하기 1(단일행 서브쿼리)
예제. JONES 보다 더 많은 월급을 받는 사원들의 이름과 월급을 출력하시오!
select sal
from emp
where ename='JONES';
select ename, sal
from emp
where sal > 2975;
select ename, sal
from emp -----------------------> 메인쿼리, outer 쿼리
where sal > ( select sal
from emp ---------------------> 서브쿼리, inner 쿼리
where ename='JONES' );
문제362. SCOTT 과 같은 월급으를 받는 사원들의 이름과 월급을 출력하시오!
select ename, sal
from emp
where sal = ( select sal
from emp
where ename='SCOTT' );
문제363. 위의 결과를 다시 출력하는데 SCOTT 은 제외하고 출력하시오 !
select ename, sal
from emp
where sal = ( select sal
from emp
where ename='SCOTT' )
and ename != 'SCOTT';
문제364. ALLEN 보다 늦게 입사한 사원들의 이름과 입사일을 출력하시오!
select ename, hiredate
from emp
where hiredate > ( select hiredate
from emp
where ename='ALLEN' );
문제365. 서울시 물가 데이터 테이블을 구성하시오 !
문제367. price 테이블에서 a_price 의 최대값을 출력하시오
select max(a_price)
from price;
문제368. 서울시 물가 데이터중에 가장 가격(a_price) 이 비싼 생필품명(a_name)
과 그 가격(a_price) 를 출력하시오 !
select a_name, a_price
from price
where a_price = ( select max(a_price)
from price );
▣ [7월 4일 점심시간 문제]
아래의 SQL의 결과를 집합 연산자(union all 이나 union) 로 구현하시오.
튜닝 후 :
select nvl( to_char( empno), '전체집계:' ) as empno, ename, sum(sal) as sal
from emp
group by grouping sets( (empno, ename), () );
튜닝 전 :
select to_char(empno) as empno, ename, sum(sal)
from emp
group by empno, ename
union
select to_char('전체집계:') as empno, null, sum(sal)
from emp;문제369. 직업이 SALESMAN 인 사원들중에 최대월급을 받는 사원의
이름과 월급을 출력하시오 !
select ename, sal
from emp
where sal = ( select max(sal)
from emp
where job='SALESMAN' )
and job ='SALESMAN'; —> 아래와 같이 하나의 조건을 더 주어야 한다!! 확인사살!
문제370. 위의 결과를 서브쿼리 이용하지 말고 order by .. fetch row 를
이용해서 수행하시오 !
select ename, sal
from emp
where job='SALESMAN'
order by sal desc fetch first 1 rows only;
문제371. dba 는 SQL을 볼때 성능을 생각하면 봐야하므로 위의 2개의 SQL의
buffer 의 갯수를 확인하시오 !
select /+ gather_plan_statistics / ename, sal
from emp
where sal = ( select max(sal)
from emp
where job='SALESMAN' )
and job ='SALESMAN';
SELECT * FROM TABLE(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
버퍼의 갯수 : 12개
※ 설명: /+ gather_plan_statistics / 이 힌트는 현 SQL 에 대한 실행계획에 대한
통계정보를 볼때 사용하는 힌트 입니다.
select /+ gather_plan_statistics / ename, sal
from emp
where job='SALESMAN'
order by sal desc fetch first 1 rows only;
SELECT * FROM TABLE(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
버퍼의 갯수 : 6개
문제372. DALLAS 의 부서번호를 출력하시오 !
select deptno
from dept
where loc='DALLAS';
문제373. DALLAS 의 부서번호에서 근무하는 사원들의 이름과 월급을 출력하시오!
select ename, sal
from emp
where deptno = ( select deptno
from dept
where loc='DALLAS' );
문제374. 위의 결과를 서브쿼리 쓰지 말고 조인으로 수행하시오 !
select e.ename, e.sal
from emp e, dept d
where e.deptno = d.deptno and d.loc='DALLAS';
문제375.( 난이도 중) KING 에게 보고하는 사원들의 이름을 출력하시오 !
( KING 의 사원번호가 mgr 번호인 사원들을 출력 )
select ename
from emp
where mgr = ( select empno
from emp
where ename='KING' ) ;
▣ 072 서브 쿼리 사용하기 2(다중 행 서브쿼리)
예제. 사원번호가 7788, 7902, 7369 번인 사원의 사원번호, 사원이름을 출력하시오
select empno, ename
from emp
where empno in ( 7788, 7902, 7369 );
예제. 이름이 SCOTT 인 사원과 월급이 같은 사원들의 이름과 월급을 출력하시오!
select sal
from emp
where ename='SCOTT';
select ename, sal
from emp
where sal = ( select sal
from emp
where ename='SCOTT' );
예제. 직업이 SALESMAN 인 사원들과 월급이 같은 사원들의 이름과 월급을
출력하시오 !
select ename, sal
from emp
where sal in ( select sal
from emp
where job='SALESMAN' );
- 서브쿼리의 종류 2가지 ?
1. 단일행 서브쿼리 : 서브쿼리에서 메인쿼리로 하나의 값이 리턴되는 경우
단일행 서브쿼리 연산자: = , >, <, >=, <=, =, !=, <>, ^=
2. 다중행 서브쿼리 : 서브쿼리에서 메인쿼리로 여러개의 값이 리턴되는 경우
다중행 서브쿼리 연산자 : in, not in, >all, <all, >any, <any문제376. 우리반 테이블에서 통신사가 kt 인 학생들과 나이가 같은 학생들의
이름과 나이를 출력하시오 !
select ename, age
from emp17
where age in ( select age
from emp17
where telecom ='kt' );
문제377. 위의 결과를 다시 출력하는데 이번에는 통신사 kt 인 학생들과 나이가
같지 않은 학생들의 이름과 나이를 출력하시오 !
select ename, age
from emp17
where age not in ( select age
from emp17
where telecom ='kt' );
▣ 073 서브 쿼리 사용하기 3(NOT IN) ★★★★★★★
예제. 관리자인 사원들의 이름을 출력하시오 !
자기 밑에 직속부하가 한명이라도 있는 사원들
(JOB 이 MANAGER 가 아니라 사원번호가 자기 부하직원들의 mgr 번호인
사원들을 출력하는것 )
SELECT ename
from emp
where empno in ( select mgr
from emp );
→ mgr번호에 해당하는 empno를 출력하는 내용
예제. 관리자가 아닌 사원들의 이름을 출력하시오 !
( 자기 밑에 직속부하가 한명도 없는 일반 사원들 )
SELECT ename
from emp
where empno not in ( select mgr
from emp );
※ 왜 선택된 레코드가 없다고 나오냐면 바로 null 값 때문입니다.
mgr 중에는 null 값이 하나 있습니다.
SELECT ename
from emp
where empno in ( select mgr
from emp );
select ename
from emp
where empno = 7788 or empno = 7902 or empno = null ;
select ename
from emp
where empno not in ( select mgr
from emp );
select ename
from emp
where empno != 7788 and empno != 7902 and empno != null;
select ename
from emp
where empno not in ( select mgr
from emp
where mgr is not null );
또는
select ename
from emp
where empno not in ( select nvl( mgr, -1 )
from emp );
※ 다중행 서브쿼리문 작성시 not in 을 사용하면 서브쿼리에 null 처리를
잘 해줘서 null 값이 리턴되지 않게 해줘야 합니다.
- 오라클의 서브쿼리의 종류 3가지 ?
1. single row subquery : 서브쿼리에서 메인쿼리로 하나의 값이 리턴되는 경우
2. multiple row subquery : 서브쿼리에서 메인쿼리로 여러개의 값이 리턴되는경우
3. multiple column subquery : 서브쿼리에서 메인쿼리로 여러개의 컬럼값이
리턴되는 경우문제378. 직업이 SALESMAN 인 사원들과 월급이 같은 사원들의 이름과 월급과
커미션, 직업을 출력하시오 !
select ename, sal, comm, job
from emp
where sal in ( select sal
from emp
where job='SALESMAN' );
문제379. 직업이 SALESMAN 인 사원들과 월급이 같고 그리고 커미션도 같은
사원들의 이름, 월급, 커미션, 직업을 출력하시오 !
-
non pair wise 방식
select ename, sal, comm, job
from emp
where sal in ( select sal
from emp
where job='SALESMAN' )
and comm in ( select comm
from emp
where job='SALESMAN' ) ; -
pair wise 방식
select ename, sal, comm, job
from emp
where ( sal, comm ) in ( select sal, comm
from emp
where job='SALESMAN' );
설명: 출력되는 정렬만 다르지 데이터는 똑같이 출력되고 있습니다.
이 2개는 데이터를 검색하는 방법이 서로 다릅니다.
update emp
set sal = 1500
where ename='KING';
update emp
set comm= 1400
where ename='KING';
commit;
**※ pairwise 방식보다 non pairwise 방식이 데이터를 더 많이 검색합니다**.
non pair wise vs pair wise
sal comm sal comm
1250 1400 1250 1400
1250 500 1250 500
1600 300 1600 300
1500 0 1500 0
1250 300
1250 0
1600 1400
1600 500
1600 0
1500 1400
1500 500
1500 300※ 오라클만 pairwise 방식을 지원합니다
문제380. 최신 mySQL 버젼에서는 pair wise 방식이 지원되는지 확인해보시오
답: mySQL 은 둘다 지원됩니다.
문제381. 우리반에서 통신사가 kt 인 학생들과 나이가 같고 성별이 같은
학생들의 이름, 나이, 성별, 통신사를 출력하시오 !
( non pair wise 방식으로 수행해주세요 )
select ename, age, gender, telecom
from emp17
where age in ( select age
from emp17
where telecom = 'kt' )
and gender in ( select gender
from emp17
where telecom ='kt' );
(pair wise)
select ename, age, gender, telecom
from emp17
where ( age, gender ) in ( select age, gender
from emp17
where telecom ='kt' );
희림이와 기찬이가 pairwise 방식에서는 검색이 안되었습니다.
문제382. 우리반 테이블에서 통신사가 lg 인 학생들과 나이가 같은 학생들의
이름과 나이와 통신사를 출력하시오 !
select ename, age, telecom
from emp17
where age in ( select age
from emp17
where telecom ='lg' );
문제383. (집합 연산자) 아래의 SQL을 튜닝하시오 !
delete from emp where hiredate is null;
commit;
튜닝전 : select deptno, to_char( null ) as job, sum(sal)
from emp
group by deptno
union
select to_number( null ) as deptno, job, sum(sal)
from emp
group by job;튜닝후 : select deptno, job, sum(sal)
from emp
group by grouping sets ( (deptno), (job) )
order by deptno, job;
문제384. 아래의 SQL의 튜닝후 SQL을 작성하시오 !
튜닝전 :
select deptno, to_char( null ) as job, sum(sal)
from emp
group by deptno
union
select to_number( null ) as deptno, job, sum(sal)
from emp
group by job
union
select null, null, sum(sal)
from emp;
튜닝후 :
select deptno, job, sum(sal)
from emp
group by grouping sets ( (deptno), (job), () )
order by deptno, job;
문제385. (오늘의 마지막 문제) 아래의 SQL의 튜닝전 SQL을 작성하시오 !
튜닝전 : ?
튜닝후 : select gender, telecom, round(avg(age) )
from emp17
group by grouping sets( (gender), (telecom), () )
order by gender, telecom;
정답 : select gender, to_char(null) as telecom, round(avg(age))
from emp17
group by gender
union
select to_char(null) as gender, telecom, round(avg(age))
from emp17
group by telecom
union
select to_char(null) as gender, to_char(null) as telecom, round(avg(age))
from emp17;
유명한 SQL 튜닝 공식을 스스로 알아내보세요.
SQLP주관식) 이름, 월급, 직업이 SALESMAN인 사원들의 토탈월급,
직업이 SALESMAN인 사원들의 최대월급,
직업이 SALESMAN인 사원들의 최소월급
을 출력하시오 !
튜닝전: select ename, sal,
( select sum(sal) from emp where job='SALESMAN' ) 최대월급,
( select max(sal) from emp where job='SALESMAN' ) 최대월급,
( select min(sal) from emp where job='SALESMAN' ) 최소월급
from emp;
답 : select ename, sal , sum(decode(job, 'SALESMAN', sal, null)) over () as 토탈월급,
max(decode(job, 'SALESMAN', sal, null)) over () as 최대월급,
min(decode(job, 'SALESMAN', sal, null)) over () as 최소월급
from emp;
한가지 알아야할 점 over () 를 쓰게 되면 group by를 할 필요가 없어진다. 따라서 그룹함수를 단독으로 사용할 수 있게 된다!!!
2)
select ename,sal,substr(급여,1,instr(급여,',')-1)as 합계,
substr(급여,instr(급여,',')+1,instr(급여,',',2)-1)AS 최대급여,
substr(급여,instr(급여,',',2)+1,instr(급여,',',3)-1)AS 최소월급
from( select ename,sal,(select sum(sal)||','||max(sal)||','||min(sal) from emp where job='SALESMAN' )AS 급여
from EMP
);
3)
SELECT e.ename, e.sal, s.최대월급, s.최소월급, s.토탈월급
FROM emp e, (
SELECT max(sal) 최대월급, min(sal) 최소월급, sum(sal) 토탈월급
FROM emp
WHERE job = 'SALESMAN') s;