▣ 089 계층형 질의문으로 서열을 주고 데이터 출력하기 1
"데이터에서 서열을 발견해서 출력하는 쿼리문"
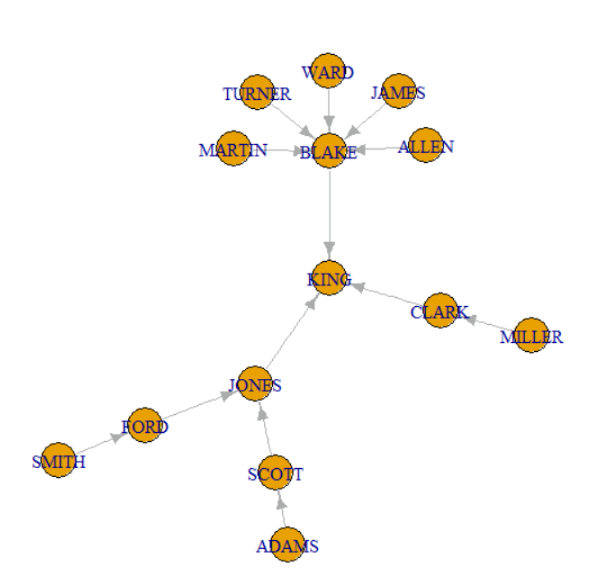
예제1. 사원 테이블의 서열을 계층형 질의문으로 출력하시오 !
select level, empno, ename, mgr
from emp
start with mgr is null
connect by prior empno = mgr;
예제2. employees 테이블에서 level, employee_id, first_name, manager_id를 출력하시오 ! 서열 1위를 manager_id 가 null 인 사원으로 하시오 !
select level, employee_id, first_name, manager_id
from employees
start with manager_id is null
connect by prior employee_id = manager_id ;
예제3. 아래의 rpad 함수를 이용한 SQL을 수행하시오 !
select rpad( ename, 10, '*')
from emp;
select rpad(' ', level * 3 ) || ename as employee, level, ename,sal, job
from emp
start with ename ='KING'
connect by prior empno = mgr;
문제501. employees 테이블에서 first_name, level, salary, job_id 를
출력하는데 앞에 first_name 앞에 level 의 2배로 공백을 넣어서
출력하시오 !
select rpad(' ', level * 2 ) || first_name as employee, level, salary, job_id
from employees
start with manager_id is null
connect by prior employee_id = manager_id;
※ start with 와 connect by 절을 사용해야 level 컬럼을 볼 수 있습니다.
문제502. 월급이 2400 이상인 사원들의 이름과 월급을 출력하는데
계층형 질의문을 이용해서 이름앞에 level 의 2배로 공백을 줘서 출력하시오( emp 테이블로 작성하세요 )
select rpad( ' ', level * 2 ) || ename as employee, sal
from emp
where sal >= 2400
start with ename='KING'
connect by prior empno = mgr ;
문제503. 위의 SQL의 실행순서를 확인하기 위해서 실행 계획을 확인하시오 !
explain plan for
5. select rpad( ' ', level * 2 ) || ename as employee, sal
1. from emp
4. where sal >= 2400
2. start with ename='KING'
3. connect by prior empno = mgr ;
select * from table(dbms_xplan.display);
설명: 실행순서가 from 절 실행하고 나서 계층형 질의문인 start with 와 connect by 를 수행하고 나서 where 절을 수행했습니다. (순서)
▣ 090 계층형 질의문으로 서열을 주고 데이터 출력하기 2
" 계층형 질의문 결과에서 검색조건을 주는 방법을 배웁니다. "
예제1. 앞의 예제에서 출력하는 사원 테이블 전체의 서열을 출력하시오 !
select rpad( ' ', level * 2 ) || ename as employee, level, sal
from emp
start with ename='KING'
connect by prior empno = mgr ;
문제504. 위의 결과에서 이름이 BLAKE 은 사원은 제외하고 출력하시오 !
select rpad( ' ', level * 2 ) || ename as employee, level, sal
from emp
where ename != 'BLAKE'
start with ename='KING'
connect by prior empno = mgr ;
문제505. 이번에는 BLAKE 뿐만 아니라 BLAKE 의 팀원들도 전부 안나오게 하시오!
select rpad( ' ', level * 2 ) || ename as employee, level, sal
from emp
start with ename='KING'
connect by prior empno = mgr and ename != 'BLAKE' ;
※ ename 이 BLAKE 인 사원의 팀원들까지 다 안나오게 하려면
connect by 절에 조건을 기술해야합니다.
문제506. employees 테이블에서 위와 똑같은 결과를 출력하는데
first_name 이 Adam 과 Adam 의 팀원들을 전부 출력안되게하시오 !
select rpad(' ', level * 3 ) || first_name as employee, level, salary, job_id
from employees
start with manager_id is null
connect by prior employee_id = manager_id and first_name !='Adam';
▣ 091 계층형 질의문으로 서열을 주고 데이터 출력하기 3
" 계층형 질의문에서 서열의 틀을 깨트리지 않으면서 데이터를 정렬하려면
order by 할때 특별한 키워드를 하나 기술해야합니다. "
예제1. 다음과 같이 사원 테이블의 전체의 서열을 출력하시오 !
select rpad( ' ', level * 2 ) || ename as employee, level, sal
from emp
start with ename='KING'
connect by prior empno = mgr;
예제2. 위의 결과를 다시 출력하는데 월급이 높은 사원부터 출력하시오 !
select rpad( ' ', level * 2 ) || ename as employee, level, sal
from emp
start with ename='KING'
connect by prior empno = mgr
order by sal desc;
설명: order by sal desc 를 사용하면서 누가 누구의 팀원인지 또는 누가 누구의 팀장인지에 대한 서열 순서가 없어졌습니다.
예제3. 누가 누구의 팀원인지에 대한 서열 구조는 그대로 유지하면서
월급이 높은 사원부터 출력되게하시오 !
select rpad( ' ', level * 2 ) || ename as employee, level, sal
from emp
start with ename='KING'
connect by prior empno = mgr
order siblings by sal desc;
문제507. 위의 결과를 employees 테이블로 출력하시오 !
select rpad( ' ', level * 2 ) || first_name as employee, level, salary
from employees
start with manager_id is null
connect by prior employee_id = manager_id
order siblings by salary desc;
▣ 092 계층형 질의문으로 서열을 주고 데이터 출력하기 4
" 계층형 질의문에 짝꿍 함수가 sys_connect_by_path 가 있습니다.
이 함수는 가로로 데이터를 출력하는 함수 입니다. "
예제1. 다음과 같이 sys_connect_by_path 함수를 이용한 SQL을 작성하시오 !
select ename, sys_connect_by_path( ename, '/' )
from emp
start with ename='KING'
connect by prior empno = mgr;
팀내에서 서열상의 위치가 어떻게 되는지 보고 싶을 때 사용.
KING /KING
JONES /KING/JONES
SCOTT /KING/JONES/SCOTT
ADAMS /KING/JONES/SCOTT/ADAMS
FORD /KING/JONES/FORD
: :
문제508. 위의 결과에서 ADAMS 만 출력하시오!
select ename, sys_connect_by_path( ename, '/' )
from emp
where ename ='ADAMS'
start with ename='KING'
connect by prior empno = mgr;
ADAMS /KING/JONES/SCOTT/ADAMS
문제509. (오라클 교제 연습문제) 위의 결과를 아래와 같이 출력하시오 !
( 앞에 / 를 빼고 출력하시오 ! )
ADAMS KING/JONES/SCOTT/ADAMS
답:
select ename, substr( sys_connect_by_path( ename, '/' ), 2, 10000 )
from emp
where ename ='ADAMS'
start with ename='KING'
connect by prior empno = mgr;
설명: 시험에서는 sys_connect_by_path 를 고르는 문제가 주로 나오니까
암기하고 있으면 됩니다.
※ 계층형 질의문으로 반드시 암기해야할 2가지 키워드 ?
- order siblings by
- sys_connect_by_path
SQLD 기출문제에서 한번 언급된 계층형 질의문에 대한 함수(기출문제33회 출제)
connect_by_isleaf 함수 ? 말단 사원인지 아닌지를 출력하는 함수
select rpad(' ', level*2) || ename, sal, connect_by_isleaf as isleaf
from emp
start with ename='KING'
connect by prior empno = mgr;
설명: 말단 사원이면 1로 출력되고 아니면 0으로 출력됩니다.
[7월 10일 점심시간 문제] merge 문
우리반 테이블에 다음과 같이 t_price 컬럼을 추가합니다.
alter table emp17
add t_price number(10);
그리고 merge 문을 이용하여 t_price 에 해당 학생의 통신사의 통신비로 값을 갱신합니다.
통신사와 통신비가 있는 telecom_table 테이블을 이용하세요.
merge into emp17 e
using telecom_table2 t
on (e.telecom = t.telecom)
when matched then
update set e.t_price = t.t_price;
▣ 093 일반 테이블 생성하기(CREATE TABLE)
- 테이블의 종류 2가지 ?
-
영구히 data 를 저장하는 테이블
-
임시로 data 를 저장하는 테이블
문법: create table 테이블명
( 컬럼명 데이터 유형,
컬럼명 데이터 유형 );
-
※ 테이블명과 컬럼명을 지을때 주의할 사항
- 테이블명과 컬럼명은 반드시 문자로 시작해야 합니다.
- 테이블명의 길이는 30자를 넘을 수 없습니다.
- 테이블명 이름에 특수문자는 $, _, # 만 포함할 수 있습니다.
create table emp907
( empno number(10), --> 숫자를 10자리를 허용하겠다
ename varchar2(20), --> 영문자 20자를 허용하겠다. 한글은 10자를 허용
sal number(10) );
※ 각 나라의 언어에 맞춰서 지원하는 문자형 데이터 유형 : nvarchar2(길이)
nchar(길이)
※ 데이터 유형의 종류 3가지 ?
- 문자형 : char, varchar2, long, clob, blob
- 숫자형 : number
- 날짜형 : date
※ char와 varchar2 의 차이 ? 처음 테이블 설계할 때 데이터의 변경이 많이 발생할 것 같은 컬럼은 char 로 생성해야합니다.
char(10) varchar2(10)
|m|i|r|a|c|l| | | | | |m|i|r|a|c|l| | | | |
고정형 4자리가 남음 가변형 4자리가 남음
공백으로 채워진다!
공간낭비가 생길수 밖에 없다. |m|i|r|a|c|l|
공백이 회수된다!
장점 : 공간이 절약된다!
if) 'e'를 업데이트 시킨다! 다른 곳으로 이사를 간다!
업데이트가 가능하다 -> 원래 있던 위치를 남겨놓고 이사간다.
|m|i|r|a|c|l|e|
-> 반드시 알아야하는 유명한 용어
row migration 현상이 일어난다.
이 현상이 많이 발생하면 성능이 느려진다.
확인 하는 것이 필요하다!
그래서 처음에 테이블을 설계할 때 CHAR 인지 VARCHAR2를 선택할지
DATA MODELER가 설계를 제대로 해야한다!
**기준 -> 업데이트가 많이 발생할 것 같은 데이터는 CHAR로 잡고,
그렇지 않는다면 VARCHAR2로 잡는다!**
왜냐하면 ROW MIGRATION 현상이 생기면 성능저하가 발생하기 때문이다!
회사의 대부분은 VARCHAR2로 하는 곳이많다!
※ ROW MIGRATION 현상이 일어남에도 불구하고
CHAR로 잘 생성 안하고 VARCHAR2로 생성하는 이유 ?
char(10) varchar2(10)
|1|0| | | | | | | | | |1|0| | | | | | | | |
-> 8자리가 남는다. ↓
| 1 | 0 | 남은 자리 회수
char(10) varchar2(2)
차이를 명확하게 이해해야한다!행 데이타영역에 사용자가 입력한 데이타들이 모두 입력되어 저장공간이 없는 경우
기존 데이타의 변경작업이 일어나면 변경에 의해 저장할 수 있는 공간이 없게 된다.
이런 경우 오라클 서버는 변경할 수 없었던 행들을 모두 새로운 블록으로 이동시킨 후 변경작업 수행
==> 행이주(Row-Migration)
- 주로 VARCHAR2 타입을 가진 컬럼에서 발생.
- Row_Migration이 발생한 테이블의 해당 행을 검색하면 오라클서버는 처음에 데이타가 저장되어
있는 블록을 먼저 검색하고 해당 행이 다른 블록으로 이주되어 있으면 이주된 블록을 다시 읽어 데이타를 검색
- 하나의 행을 검색하기 위해 여러개의 블록을 읽어야 데이타를 가져올 수 있기 때문에 검색속도 저하.
( SELECT문 처리시 데이타 검색속도 저하)※ row migration 현상이 일어남에도 불구하고 char 로 잘 생성 안하고
varchar2 로 생성하는 이유 ?
- 테스트 스크립트 create table emp600
( ename varchar2(10),
sal number(10),
deptno varchar2(10) ); create table dept600
( deptno char(10),
loc varchar2(10) ); insert into emp600 (ename, sal, deptno)
select ename, sal, to_char(deptno)
from emp; insert into dept600(deptno, loc )
select to_char(deptno), loc
from dept; commit;
문제510. dept600 테이블에서 deptno 가 10번인 deptno 와 loc 를 출력하시오!
select deptno, loc
from dept600
where deptno ='10';
char(10) = char(2)
내부적으로 공백을 채워서--> char(10) = char(10)
그래서 결과가 잘 출력이 되어졌습니다.문제511. emp600 테이블에서 deptno 가 10번인 사원들의 ename, sal 을 출력하시오
select ename, sal
from emp600
where deptno = '10';
varchar2(2) = varchar2(2) 결과가 잘 나왔습니다.문제512. dept600 테이블과 emp600 테이블을 서로 조인해서 ename, sal,
loc 를 출력하시오 !
select e.ename, e.sal, d.loc
from emp600 e, dept600 d
where e.deptno = d.deptno;
varchar2(2) != char(10)
※ emp600 에서 deptno 번호 10번은 잘 조회되고 dept600 에서 deptno번호 10번 잘 조회가 되지만, 조인을 했을때는 결과가 안나옵니다.
왜 안나오냐면 varchar2(2) 가 char(10) 을 맞춰주기 위해서 공백 8 를 채우지않습니다. 그래서 그냥 대부분 varchar2로 다 테이블 설계를 합니다.
위와 같은 현상이 일어나지 않게 하려고 일부러 char 를 잘 안쓰고 varchar2로 설계합니다.
※ 그러면 row migration 현상은 ?
데이터가 조인되어서 안보이는 문제가 더 심각하지 이런 아주 작은 성능상의 이슈보다는 데이터를 출력하는게 더 중요한것 입니다.
※ 문자형 데이터 타입 (p 245 책 참고)
| 유형 | 설명 | 특징 |
|---|---|---|
| CHAR | 고정 길이 문자 데이터 유형이며 최대 길이는 2000입니다. | CHAR(), Row Migration |
| VARCHAR2 | 가변 길이 문자 데이터 유형이며 최대 길이는 4000입니다. | VARCHAR2() → 상대적으로 자주 쓴다. Row Migration |
| LONG | 가변 길이 문자 데이터 유형이며 최대 2GB의 문자데이터를 허용합니다. | ()를 쓰지 않는다, Data Migration |
| CLOB | 문자 데이터 유형이며 최대 4GB의 문자 데이터를 허용합니다. | ()를 쓰지 않는다→ 상대적으로 자주쓴다. Data Migration |
| BLOB | 바이너리 데이터 유형이며 최대 4GB의 바이너리 데이터를 허용합니다. | ()를 쓰지 않는다, Data Migration, 이미지 |
| NUMBER | 숫자 데이터 유형이며 십진 숫자의 자리수는 최대 38자리까지 허용 가능하며 소숫점 이하 자리는 -84 ~ 127까지 허용합니다. | DATE(), 가변형 |
| DATE | 날짜 데이터 유형이며 기원전 4712년 01월 01일부터 기월후 9999년 12월31일까지의 날짜를 허용합니다. | ()를 쓰지 않는다. |
문제513. 스티브 잡스 연설문을 db 에 저장하기 위해서 아래와 같이 테이블을
생성하시오 !
create table stev_jobs
( s_text long );
문제514. stev_jobs 테이블에 스티브 잡스 연설문을 입력하시오 !
create table stev_jobs
( s_text varchar2(4000) );
※ 큰 텍스트 데이터를 입력할 때는 long, clob, varchar2(4000) 중에 하나를 사용
해서 오류가 없는 것으로 선택하면 됩니다.
문제515. 우리반 데이터를 입력하기 위한 테이블을 emp17_my 로 생성하시오 !
테이블 정의서: 어떻게 테이블을 만들어 달라는 형식
create table emp17_my
(
EMPNO number(10),
ENAME varchar2(10),
GENDER varchar2(5),
BIRTH date,
AGE number(10),
TELECOM varchar2(10),
EMAIL varchar2(100),
MAJOR varchar2(50),
ADDRESS varchar2(200) );
문제516. 위에 emp17_my 테이블에 emp17 테이블의 데이터를 입력하시오 !
insert into emp17_my(empno,ename,gender,birth,age,telecom, email, major,address)
select empno,ename,gender,birth,age,telecom, email, major,address
from emp17;
commit;
문제517. dept 테이블의 data 를 입력하기 위한 dept_my 테이블을 생성하고
dept 테이블의 모든 데이터를 dept_my 테이블에 입력하시오 !
describe dept ;
DEPTNO NUMBER(10)
DNAME VARCHAR2(14)
LOC VARCHAR2(13)
create table dept_my
( deptno number(10),
dname varchar2(14),
loc varchar2(13 ) );
insert into dept_my
select * from dept;
commit;
문제518. 아래의 데이터를 dept_my 데이터에 입력하시오 !
부서번호 : 50
부서명 : hr
부서위치 : Chaubunagungamaug
insert into dept_my
values( 50, 'hr', 'Chaubunagungamaug') ;
ORA-12899: "C##SCOTT"."DEPT_MY"."LOC" 열에 대한 값이 너무 큼(실제: 17, 최대값: 13)
문제519. (dba 에게 들어오는 요청) dept_my 테이블에 loc 컬럼의 길이를
varchar2(50) 으로 늘리시오 !
alter table dept_my
modify loc varchar2(50) ;
desc dept_my ;
<--- memory에 있는 내용이 사라지면서 성능이 느려진다. 따라서 밤이나 주말에 수행해야한다! 급해도 안된다! 안된다! 낮에는 안된다! crontab에 걸어놓아야한다!
※ 주의사항 ! 위의 alter 문을 이용한 변경작업은 dba 가 낮에 업무시간에
한참 바쁠때 수행하면 안되고 db 가 한가한 밤이나 주말에 수행해야합니다.
문제520. emp 테이블에 ename 에 문자의 길이를 varchar2(60) 으로 변경하시오
alter table emp
modify ename varchar2(60) ;
※ 위와 같은 변경사항에 대한 이력은 별도의 테이블로 만들어서 관리하면
나중에 db 쪽 감사가 있거나 또는 이력을 확인하고 싶을때 쉽게 확인해볼수
있습니다. si 프로젝트시 주로 감사를 받는데 테이블 정의서(엑셀파일) 와
실제 db와 일치하는지 확인을 합니다.
일치하는지 확인 ---> PL/SQL , 파이썬
엑셀에 테이블 정의서 --------------------- 물리적 db 설계※ dba 가 반드시 알아야할 컬럼 변경 명령어 4가지
-
컬럼 추가 : 예: emp 테이블에 email 라는 컬럼을 추가
alter table emp add email varchar2(30); -
컬럼 삭제: 예: emp 테이블에 sal 을 컬럼 삭제
alter table emp drop column sal ;
※ 컬럼삭제는 한번 삭제되면 flashback 도 안되고 rollback 도 안됩니다.
주의해야합니다. !
-
컬럼 변경 :
예: emp 테이블의 job 의 컬럼의 길이를 varchar2(50) 으로 늘리시오 alter table emp modify job varchar2(50); 늘리는것은 잘되는데 **줄이는것은 데이터가 자리를 확보하고 있으면 줄일 수 없습니다.** -
컬럼 감추기 → 성능상의 이유 때문에
문제521. emp 테이블에 address 라는 컬럼을 varchar2(30) 으로 추가하시오!
alter table emp
add address varchar2(30);
문제522. emp 테이블에 address 컬럼을 삭제하시오 !
alter table emp
drop column address ;
문제523. emp 테이블에 sal 컬럼을 삭제하시오 !
alter table emp
drop column sal;
rollback;
alter table emp enable row movement;
flashback table emp to timestamp
( systimestamp - interval '5' minutes) ;
RA-01466: 테이블 정의가 변경되었습니다 데이터를 읽을 수 없습니다
01466. 00000 - "unable to read data - table definition has changed"
Cause: Query parsed after tbl (or index) change, and executed
w/old snapshot
Action: commit (or rollback) transaction, and re-execute
rollback, flashback 둘다 안된다!!
해결방법 : 백업 솔루션에서 받은 백업본으로 복구를 하면 됩니다.
백업 솔루션을 안쓰는 회사는 수업 때 배운 "백업과 복구" 방법으로 복구하면 됩니다.
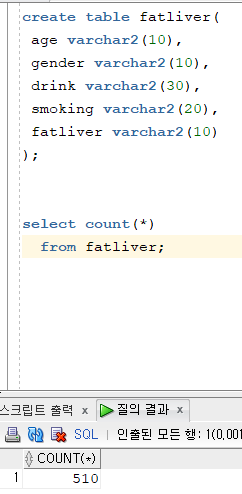
**※ 컬럼 drop 은 정말 조심히 신중히 수행해야 합니다 !**문제524. ( 오늘의 마지막 문제) 데이터 게시판의 388 번의 지방간 데이터를
이 데이터를 저장할 테이블을 생성하고 데이터를 입력하시오 !
dba 에 들어오는 요청중 하나 입니다. (테이블명: fatliver )
컬럼명은 알아서 정하시면 됩니다.
데이터 입력은 sqldevloper 로 입력하세요.
결과를 카운트해서 캡쳐해서 답글로 작성하시면 됩니다.