
▩ VIEW 복습

■ view 를 사용하는 이유 ?
1. 보안상의 이유 (민감한 데이터를 노출하지 않으려고)
2. 복잡한 쿼리문을 단순하게 쿼리하기 위해서
3. 특정 DATA 를 갱신하지 못하게 할때■ view 의 옵션 2가지 ?
1. with read only : view 에 DML 작업이 아예 안되게 막는 옵션
2. with check option : 특정 조건의행의 데이터를 갱신하지 못하게 막는 옵션" VIEW 는 데이터를 저장하지 않고 그냥 테이블을 바라보는 쿼리문 "
▣ view 의 종류 2가지
단순 view 복합 view
테이블의 갯수 1개 2개 이상
group 함수 또는 포함안함 포함
group by 절
DML 여부 가능 불가능 할 수도 있다※(★) GROUP 함수와 GROUP BY 절을 써서 만든 복합뷰는 아예 DML 이 안됩니다.
※ 조인을 해서 만든 VIEW 는 1쪽 테이블(예:dept) 은 수정이 안되는데
M쪽 테이블(예: emp ) 는 수정이 됩니다. 대신 dept 테이블 deptno 에
primary key 제약이 걸려있어서 중복된 부서번호가 없다는것이 보장이 되어야 수정이 가능합니다. (★★★ SQLP 객관식, 성능고도화책)
문제552. (복습문제) 직업, 직업별 토탈월급을 출력하는 VIEW 를 생성하시오 ! ( 뷰이름: job_sumsal )
create or replace view job_sumsal
as
select job, sum(sal) as sumsal
from emp
group by job;
select * from job_sumsal;
문제553. 위의 뷰 job_sumsal 에 아래의 데이터를 입력하시오 !
job : engineer
sumsal : 5600
답: insert into job_sumsal(job, sumsal) values( 'engineer', 5600 );
insert into job_sumsal
select job, sum(sal)
from emp
group by job;
문제554. job_sumsal 뷰의 데이터에서 job 이 SALESMAN 인 데이터를 지우시오
delete from job_sumsal
where job='SALESMAN';
ORA-01732: 뷰에 대한 데이터 조작이 부적합합니다
※ group by 절을 포함하는 복합뷰는 insert 와 delete 가 안됩니다. update도 당연히 안된다!
문제555. 아래의 단순뷰를 생성하시오 !
create or replace view emp98
as
select *
from emp
where job !='ANALYST';
select * from emp98;
문제556. emp98 뷰에 이름이 KING 인 사원을 지우시오 !
delete from emp98
where ename='KING';
select * from emp;
※ 뷰의 데이터를 지우면 뷰와 관련 테이블의 데이터를 지우는 것입니다.
문제557. emp98 뷰에 아래의 데이터를 입력하시오 !
사원번호: 3845
사원이름: JANE
월급 : 4000
부서번호 : 20
insert into emp98( empno, ename, sal, deptno )
values( 3845, 'JANE', 4000, 20 );
select * from emp;
※ view 데이터를 입력하면 view 와 관련된 테이블에 데이터가 입력됩니다. 테이블에 대해서 select, update, delete 권한을 주었으면 테이블에 관련한 view 에 대해서는 select, update, delete 권한을 따로 주지 않아도 됩니다.
c##scott c##king
emp 테이블 update emp98
set sal =0
grant select on emp to c##king; where ename='ALLEN';
grant update on emp to c##king;
grant delete on emp to c##king;
grant select on emp98 to c##king;
문제558. 아래의 보기가 맞는지 틀린지 테스트 하시오 !
B. Tables in the defining query of a view must always exist in order to create the view
dept900 이 없는 테이블인데 아래의 SQL이 에러가 나는지 안나는지 확인하시오
답 : create force view dept_view2
as
select * from dept900;
경고: 컴파일 오류와 함께 뷰가 생성되었습니다.
force 라는 옵션을 위와 같이 사용하게 되면 테이블이 없어도 view 를 생성할 수 있습니다. 디폴트는 noforce 입니다.
■ 뷰(view) 제거
뷰를 삭제해도 관련된 테이블이 삭제되는것은 아닙니다.
문법 : drop view emp98;
select * from emp;
문제559. 내가 가지고 있는 db 의 권한이 무엇인지 확인하시오 !
select * from session_privs;
237개나 되는 권한을 가지고 있습니다. dba 권한을 받았기 때문에 이렇게 많습니다
문제560. session_privs 에서 DROP ANY VIEW 가 있는지 확인하시오 !
select *
from session_privs
where privilege ='DROP ANY VIEW';
문제561. 내가 생성한 VIEW 가 뭐가있는지 확인하시오 !
select *
from user_views;
설명: text 라는 컬럼이 있는데 text 라는 컬럼을 보면 view 에 관련한 쿼리문을 확인하실 수 있습니다.
문제562. 가지고 있는 view 중에 job_sumsal 뷰를 삭제하시오 !
drop view job_sumsal;
▣ 097. 절대로 중복되지 않는 번호 만들기(SEQUENCE)
시퀀스(sequence) 란 ? 일련 번호 생성기
(순서대로 번호를 생성하는 db object)
예: 쿠팡의 주문 테이블이 있다면 주문번호는 순서대로 부여됩니다.
은행의 번호표 기계를 연상하면 되는데 기계가 없이 사람이 일일히
번호를 적어서 나눠주면 분명히 실수할 가능성이 있습니다.
오라클의 시퀀스를 생성하면 번호가 순서대로 잘 생성이 됩니다.
주문 테이블
주문번호 주문 상품 배송지
1 마우스 서울시 ...
2 노트북 경기도 ...
3 키보드 서울시 ...■ 응용 프로그램 코드를 대체한다는 것이란 ?
좋은 개발환경의 insert문:
insert into 주문테이블(주문번호, 주문상품, 배송지)
values( 시퀀스이름.nextval, '노트북', '서울시' );
개선해야할 개발환경의 insert 문:
변수(빈컵)
↑
select max(주문번호) + 1 into :v_order
from 주문테이블;
insert into 주문테이블(주문번호, 주문상품, 배송지)
values( :v_order , '노트북', '서울시' );
설명: max(주문번호) + 1 로 번호를 생성하지 말고 시퀀스를 사용해서 번호를 생성하기를 권장합니다. 그래야 성능이 좋아집니다.
예제. 시퀀스 생성하기
-
시퀀스 생성
create sequence seq1
increment by 1 -- 증가치
start with 1 -- 시작숫자
maxvalue 100 -- 최대값
nocycle -- 순환여부
cache 20 ; -- 미리 메모리에 올려놓을 번호의 갯수 (성능을 위해서) -
주문 테이블을 생성합니다.
create table cuppang_order
( order_num number(10),
order_name varchar2(20),
address varchar2(30) ); -
cuppang_order 테이블에 데이터를 입력합니다.
insert into cuppang_order
values( seq1.nextval, '노트북', '서울시 송파구');insert into cuppang_order
values( seq1.nextval, '무선 마우스', '서울시 강남구');select * from cuppang_order;
100까지 생성되면 그 다음번호 생성할때 아래와 같이 오류가 납니다.
ORA-08004: 시퀀스 SEQ1.NEXTVAL exceeds MAXVALUE은 사례로 될 수 없습니다
이 오류가 나기전에 dba 는 지금 현재 몇번까지 번호가 생성되었는지 확인을하고 maxvalue 에 도달할 것 같으면 maxvalue 값을 늘려주셔야합니다.
문제563. seq1 의 현재 시퀀스 값을 확인하시오 !
select seq1.currval
from dual;
문제564. seq1 의 설정값이 어떻게 되어있는지 확인하시오 !
select *
from user_sequences;
SEQUENCE_NAME MIN_VALUE MAX_VALUE INCREMENT_BY CY OR CACHE_SIZE LAST_NUMBER SC EX SE KE
----------------- ---------- ---------- ------------ -- -- ---------- ----------- -- -- -- --
EMP_SEQ 1 9000 1 N N 20 8020 N N N N
MY_SEQ 1 100 1 N N 20 101 N N N N
ORD_SEQ 1 100000 1 Y N 5000 5001 N N N N
SEQ1 1 100 1 N N 20 41 N N N N
SEQ2 1 100000 1 Y N 20 21 N N N N
SEQ3 1 100 1 Y N 20 41 N N N N
SEQ5 1 10000 1 N N 20 21 N N N N문제565. seq1 의 maxvalue 값을 200으로 늘리시오 !
alter sequence seq1
maxvalue 200;
select *
from user_sequences;
※ dba 가 관리해야하는 일중에서 시퀀스 maxvalue 값에 도달해서 에러나지 않게끔 해야하는 일을 챙겨야합니다.
[7월 12일 점심시간 문제] 부서번호, 부서번호별 평균월급을 출력하는 view를 생성하세요. (view 이름은 dept_avg 로 생성하세요.)
create or replace view dept_avg
as
select deptno, avg(sal) as sumsal
from emp
group by deptno;문제566. seq2 시퀀스를 생성하는데 시작값은 1로 하고 최대값은 100000, cycle 로 하고 cache는 20으로 줘서 시퀀스를 생성하시오 !
증가치는 1로 하세요.
create sequence seq2
start with 1
increment by 1
maxvalue 100000
cycle
cache 20 ;
select * from user_sequences;
문제567. seq2 시퀀스의 시작값을 1이 아닌 5로 변경하시오 !
alter sequence seq2
start with 5;
※ 시퀀스의 시작값은 alter 명령어를 사용해서 수정할 수 없습니다.
start with 만 빼고 다 변경이 가능합니다.
문제568. seq1 시퀀스를 drop 하시오 !
drop sequence seq1;
select *
from cuppang_order;
ORDER_NUM ORDER_NAME
--------- -------------
1 노트북
2 무선 마우스※ 시퀀스를 drop 했어도 이미 생성한 번호들을 그대로 잘 테이블에 입력되어있습니다.
※ sequnece 관련해서 dba 가 반드시 알아야할 tip
시퀀스 파라미터 중에 cache 파라미터를 사용할 때 주의할 사항 !
create sequence seq3
start with 1
increment by 1
maxvalue 100
cache 20;
시퀀스 번호를 1번, 2번 생성한 후에 db 가 비정상 종료 되었다가 다시 startup 이 되면 시퀀스 번호는 3번이 아니라 21번이 됩니다.
왜냐하면 메모리에 올렸던 번호들이 다 사라져버렸기 때문입니다.
그래서 번호의 순서가 순차적으로 시퀀스를 통해서 테이블에 입력되어야 한다면 이 부분을 신경써야 합니다.
시퀀스 삭제하고 다시 시작숫자 맞춰서 생성해줘야 합니다. 그래도 성능을 위해서 절대 nocache 로 시퀀스를 만들지는 마세요
문제569. 시퀀스 ocp 시험문제 환경을 내 db 에 구성하시오 !
시퀀스 생성시 cycle 옵션을 줬으면 maxvalue 값 다 출력된 다음 다시 시작하는 숫자가 start with 값이 아니라 minvalue 값입니다. 그래서 cycle 을 썼으면 start with 와 minvalue 의 값을 동일하게 맞춰줘야 합니다.
create sequence ord_seq
increment by 1
start with 1
maxvalue 100000
minvalue 1
cycle
cache 5000;
create table ord_items(
ord_no number(4) default ord_seq.nextval not null,
item_no number(3),
qty number(3),
expiry_date date,
constraint it_pk primary key(ord_no, item_no) );
insert into ord_items( item_no, qty, expiry_date )
values( 201, 400, sysdate );
설명: primary key 제약이 걸려있으면 null 값을 입력할 수 없습니다.
default ord_seq.nextval 로 설정 되어있으므로 암시적으로 null 을
입력하면 디폴트 값이 입력되는데 디폴트를 시퀀스로 지정했기 때문에
시퀀스 값이 입력됩니다.
select * from ord_items;
▣ 098 데이터 검색 속도를 높이기(INDEX)
인덱스(index) ? 쿼리문의 검색속도를 높이는 db object
- 인덱스의 구조 ? 1. 컬럼값 + rowid ( 행의 주소 )
2. 컬럼값이 ascending 하게 정렬되어 있습니다.
-
인덱스를 ename 에 생성
create index emp_ename
on emp(ename); -
ename 의 인덱스만 보는 쿼리문
select ename, rowid
from emp
where ename > ' ' ; -
위의 SQL의 결과가 테이블에서 읽어온 데이터가 아니라
EMP_ENAME 인덱스에서 읽어온 데이터임을 확인하시오 !```sql explain plan for select ename, rowid from emp where ename > ' '; select * from table(dbms_xplan.display); ------------------------------------------------------------------------------ | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ------------------------------------------------------------------------------ | 0 | SELECT STATEMENT | | 14 | 266 | 1 (0)| 00:00:01 | |* 1 | INDEX RANGE SCAN| EMP_ENAME | 14 | 266 | 1 (0)| 00:00:01 | ------------------------------------------------------------------------------ ``` ```sql explain plan for select ename, rowid from emp where ename is not null; select * from table(dbms_xplan.display); ------------------------------------------------------------------------------ | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ------------------------------------------------------------------------------ | 0 | SELECT STATEMENT | | 14 | 266 | 1 (0)| 00:00:01 | |* 1 | INDEX FULL SCAN | EMP_ENAME | 14 | 266 | 1 (0)| 00:00:01 | ------------------------------------------------------------------------------ Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter("ENAME" IS NOT NULL) NOT이 들어 가서 그런지 INDEX RANGE SCAN이 아닌 INDEX FULL SCAN을 한다. ```
문제570. emp 테이블에 sal 에 인덱스를 생성하시오 ! 인덱스 이름은 emp_sal이라고 하시오 !
create index emp_sal
on emp(sal);
문제571. emp_sal 인덱스의 구조를 확인하시오 !
- 인덱스의 구조 : 1. 컬럼값 + rowid
2. 컬럼값이 ascending 하게 정렬되어 있습니다.explain plan for select sal, rowid from emp where sal >= 0 ; select * from table(dbms_xplan.display); ---------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ---------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 14 | 350 | 1 (0)| 00:00:01 | |* 1 | INDEX RANGE SCAN| EMP_SAL | 14 | 350 | 1 (0)| 00:00:01 | ----------------------------------------------------------------------------explain plan for select sal, rowid from emp where sal != 0 ; --> not 이 들어갔기 때문에 목차를 full scan 한다! select * from table(dbms_xplan.display);
문제572. emp 테이블에 hiredate 에 인덱스를 생성하시오 !
create index emp_hiredate
on emp(hiredate);
문제573. emp 테이블에 hiredate 의 인덱스의 구조를 확인하시오 !
- 인덱스의 구조 : 1. 컬럼값 + rowid
2. 컬럼값은 ascending 하게 정렬 되어 있습니다. select hiredate, rowid
from emp
where hiredate < to_date('9999/12/31', 'RRRR/MM/DD');
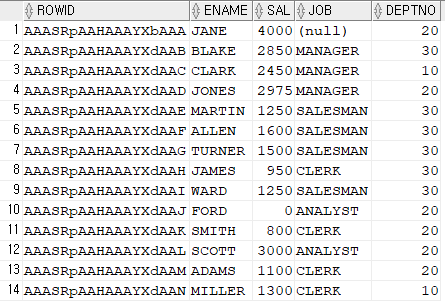
- rowid 는 로우의 주소인데 인덱스에도 있고 테이블에도 있습니다. select rowid, empno, ename, sal
from emp;
문제574. 이름이 SCOTT 인 사원의 이름과 월급을 출력하시오 !
select ename, sal
from emp
where ename='SCOTT';
↑
인덱스 생성된 컬럼
이제 부터 SCOTT 데이터를 찾는 방법이 2가지가 있습니다.
1. full table scan : scott 데이터를 찾기 위해서 테이블을 처음부터 끝까지 모두 스캔한것 !
2. index range scan : scott 데이터를 찾기 위해서 목차(index) 를 통해서
테이블을 엑세스 한것 !문제575. 여러분들의 옵티마이져는 아래의 SQL을 실행할 때 full table scan을
했는지 index range scan을 했는지 실행계획을 확인하세요 !
explain plan for
select ename, sal
from emp
where ename='SCOTT';
select * from table(dbms_xplan.display);
select ename, sal
from emp
where ename='SCOTT';
문제576. 아래의 SQL의 실행계획이 full table scan 이 되게 하시오 !
explain plan for
select /+ full(emp) / ename, sal
from emp
where ename='SCOTT';
select * from table(dbms_xplan.display);
문제577. 월급이 1250 인 사원의 이름과 월급을 출력하는 쿼리문을 작성하는데
full table scan 이 되게 하시오 !
select /+ full(emp) / ename, sal
from emp
where sal = 1250;
인덱스
• 스키마 객체입니다.
• Oracle 서버에서 **포인터를 사용하여 행 검색 속도를 높이는데 사용**할 수 있습니다.
• **신속한 경로 액세스 방식을 사용하여 데이터를 빠르게 찾아 디스크 I/O(입/출력)**를 줄일 수 있습니다.
• 인덱스의 대상인 테이블에 독립적입니다.
• Oracle 서버에서 자동으로 사용되고 유지 관리됩니다select ename, sal
from emp
where ename = 'SCOTT'
인덱스 (emp_ename) → 2개 블락을 메모리에 읽는다.
select ename, rowid
from emp
where ename > ' ';

테이블(emp) → 16~32개 블락씩 한번에 쫙쫙 올라간다.
select rowid, ename, sal, job, deptno
from emp;
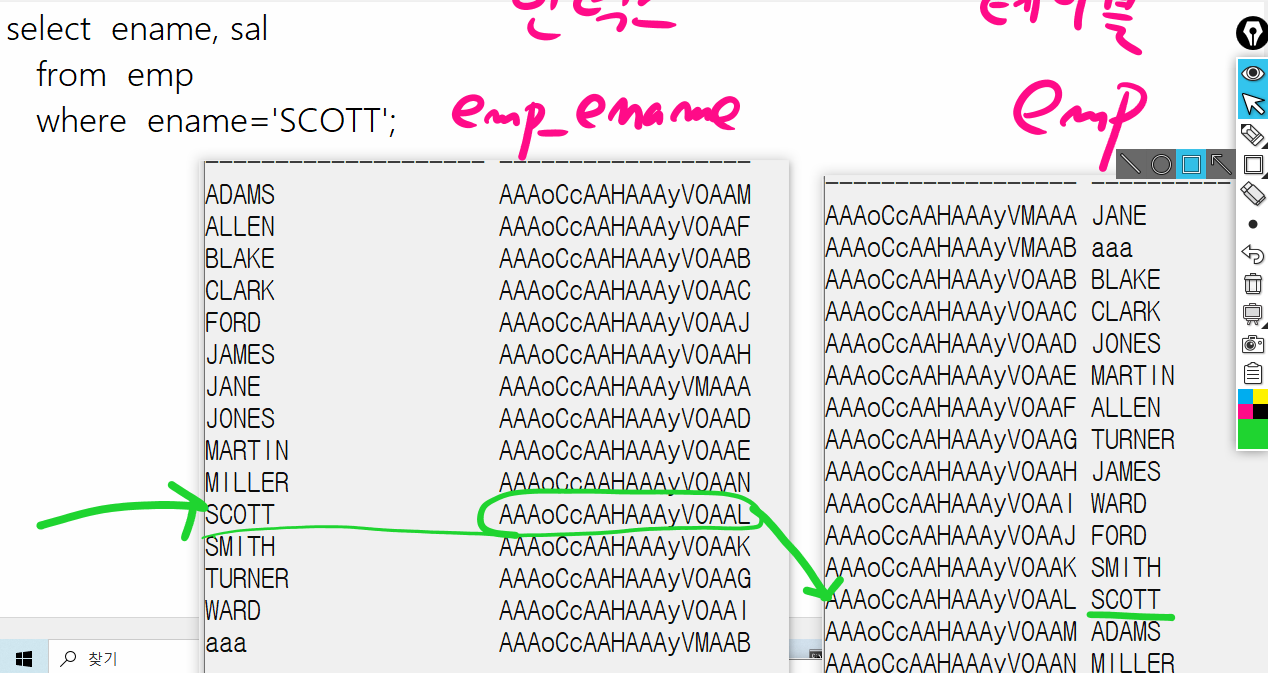
문제578. 위의 SQL이 emp_sal 인덱스를 통해서 테이블을 엑세스 할 수 있도록
힌트를 주시오 !
select /+ index(emp emp_sal) / ename, sal
from emp
where sal = 1250;
설명: /+ index(테이블명 인덱스 이름) /
explain plan for
select /+ index(emp emp_sal) / ename, sal
from emp
where sal = 1250;
select * from table(dbms_xplan.display);
※ SQL 튜닝방법
**1. where 절에 좌변을 가공하지 말아라 !**
튜닝전:
select ename, sal
from emp
where sal * 12 = 36000;
튜닝후:
select ename, sal
from emp
where sal = 36000 / 12 ;문제579. 사원 테이블에 job 에 인덱스를 생성하시오 !
( 인덱스 이름은 emp_job 으로 하세요 ! )
create index emp_job
on emp(job);
문제580. (오늘의 마지막 문제) 아래의 SQL 을 튜닝하시오 !
튜닝전 :
select ename, sal, job
from emp
where substr( job, 1, 5 ) = 'SALES';
튜닝후:
explain plan for
select ename, sal, job
from emp
where job like 'SALES%';
select * from table(dbms_xplan.display);
