Abstract
- 기존의 Sequence Transduction Model은 대부분 Encoder Decoder 구조를 포함한 복잡한 RNN이나 CNN으로 구성되어 있음
- 본 논문에서는 Reccurence와 convolution을 완전히 제거하고 attention mechanism으로만 구성된 Transformer라는 새로운 구조를 제시한다.
- 두 개의 machine translation task를 통하여 실험한 결과, Transformer는 기존의 모델에 비해 병렬화가 용이하고 훈련 시간 또한 단축되었으며 결과물 역시 우월하였다.
Introduction
- Recurrent Model은 input과 output의 symbol sequence의 symbol position에 따라 계산을 분해하여 진행하는 특성을 가지고 있음.
- 연산 시점에서 각 step에 따라 position을 정렬하고, 이전 time step의 hidden state 과 현재 time step의 input을 받아 hidden state 를 생성한다.
- Recurrent Model의 이러한 Sequential한 특성은 훈련 과정에서의 병렬화를 배제하는데, 이러한 메모리의 제한은 샘플간의 배치화를 방해하기 때문에 보다 긴 sequence length를 처리하는데 치명적인 문제를 야기한다.
- factorizaton trick, conditional computation과 같은 최근의 연구들을 통해 연산 효율성과 모델 퍼포먼스를 눈에 띄게 향상시켰지만 Sequential Computation이라는 근본적인 한계점은 여전히 남아있었다.
- Attention Mechanism은 input과 output sequence 사이의 거리에 상관없이 dependency modelling이 가능하게끔 함으로써 다양한 task들에서의 sequence model과 transduction model에 필수적인 요소로 자리잡게 되었다.
- 그러나 일부 케이스를 제외하고 attention mechanism은 대부분 recurrent network와 함께 사용된다.
- 본 논문에서는 input과 output 사이의 global dependency를 계산하기 위해 recurrence를 제거하고 전적으로 attention mechanism에만 의존하는 Transformer라는 구조를 제시한다.
Model Architecture
- 가장 경쟁력 있는 Neural sequence transduction model들은 encoder-decoder구조를 가지고 있다.
- encoder는 input sequence의 symbol representation인 을 다른 연속적인 representation인 로 매핑한다.
- 가 주어졌을때, decoder는 output sequence 를 한번에 하나씩 생성한다.
- 각 스텝마다 모델은 이전 스텝에서 생성된 심볼을 추가적인 input으로 활용하여 다음 스텝의 symbol을 생성한다는 점에서, auto-regresive하다고 볼 수 있다.
- Transformer는 encoder와 decoder 모두에 self-attention, pointwise fully connected layer가 적용된 구조로 되어 있다.
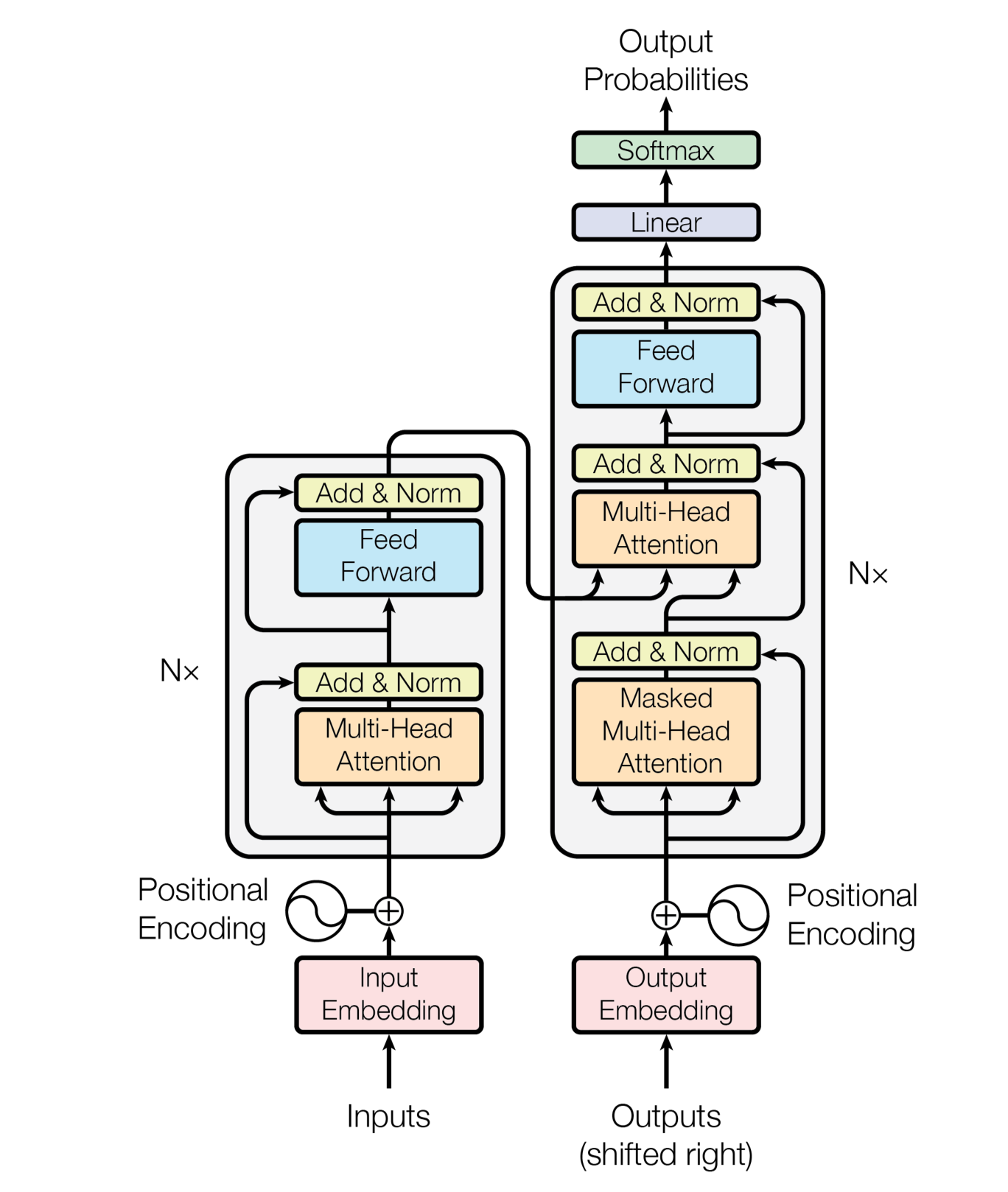
Encoder & Decoder stacks
-
Encoder는 의 동일한 layer로 구성되어 있고, 각 layer는 두 개의 sub-layer로 구성되어 있다.
- 첫 번째는 multi-head self-attention 메커니즘이고 두 번째는 position-wise fully connected feedforward-network이다.
- 또한, sub-layer들에 residual connection을 적용하였고, 그 뒤로 layer normalization이 이어지도록 했다.
- 즉, 각 sub-layer들의 output은 의 형태를 띄게 된다.
- 이러한 residual connection의 적용 과정에서 편의를 위해 embedding layer를 포함한 모델의 모든 sub-layer들은 의 output을 출력한다.
-
Decoder역시 Encoder와 마찬가지로 의 동일한 layer들을 stack한 형태로 구성되어 있다.
- Encoder의 두 개의 sub-layer에 더해 Decoder에는 encoder stack의 output에 대해 multi-head attention을 수행하는 세 번째 sub-layer를 추가한다.
- 또한 Decoder stack의 self-attention sub-layer부분이 연산 과정에서 앞쪽 position을 참조하지 못하도록 masking을 추가하였다.
Attention
- Attention함수는 query 벡터와 key-value 벡터 쌍을 output 벡터로 mapping 하는 것이라 볼 수 있다.
- output은 value들의 weighted sum으로 계산되며 weight은 query와 이에 대응되는 key의 compatibility function으로 계산된다.
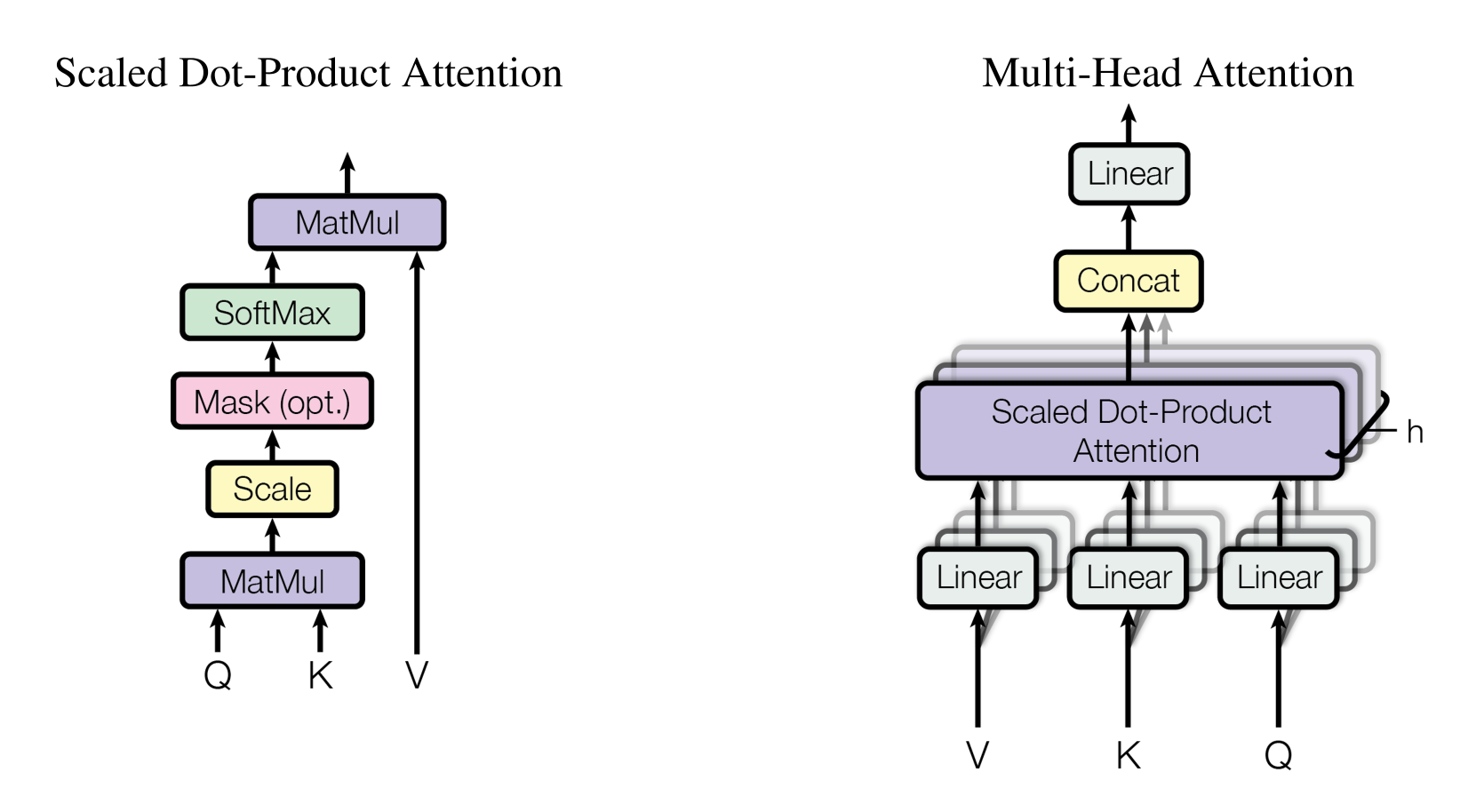
Scaled Dot-Product Attention
- Transformer에서는 Scaled Dot-product Attention이라는 attention 기법을 사용한다.
- 해당 attention의 input은 차원의 query와 key, 그리고 차원의 value로 구성되어 있다.
- dot product 연산은 query와 모든 key에 대해 수행하며 이를 로 나눠준다. 그리고 각 value에 대한 weight를 얻기 위해 softmax 함수를 적용한다.
- 실제 연산 과정에서는, query의 집합을 행렬 로 묶어서 한번에 계산한다.
- 기존의 Dot-Product Attention은 key벡터의 차원 가 클 경우 additive attention에 비해 성능이 떨어지는 단점이 있다.
- 이러한 문제점이 발생하는 이유는 가 클 경우, dot product를 수행하였을때 그 결과값 역시 커지게 되고 이에 따라 softmax를 수행하였을 때 gradient 값이 극도로 작아지게 때문이다. 이러한 현상을 방지하기 위해서 dot product를 로 scaling한다.
- softmax의 binary 버전인 sigmoid 함수를 고려해보면, input의 크기가 커질수록 1로 saturate되는 것을 확인할 수 있다. 따라서 softmax역시 이와 마찬가지로 값이 커질수록 gradient 값이 0에 가까워지는 것임.
- query와 key의 각 원소가 mean 0, var 1인 independent random variable이라고 가정하면, 그들의 dot product인 는 mean 0, var 가 되는 것을 확인할 수 있다. 이러한 이유로 가 커질수록 dot product 값 역시 커지게 된다.
값의 변동성이 커진다는 표현이 더 적절해 보인다.
Multi-Head Attention
- 차원의 key, value와 query에 대한 single-attention을 수행하는 대신, 각기 다른 학습가능한 h개의 linear projection을 수행하여 차원으로 변환한 후 attention을 병렬적으로 수행하여 차원의 output을 뽑아내는 방식을 사용한다.
- 이렇게 뽑혀져 나온 결과는 concatenate된 후 다시 projection을 시켜주게 된다.
- 이렇게 Multi-Head Attention을 이용하게 되면 각기 다른 position의 representation subspace으로부터 정보를 jointly하게 접근할 수 있게 된다. Single-Head일 경우 averaging 때문에 이러한 접근이 제한된다.
where )- projection은 학습 가능한 행렬 그리고 을 통하여 수행된다.
- 해당 논문에서는 의 병렬적인 attention layer(head)를 적용하였다.
- 이들 head에는 를 적용하였으며, 이러한 차원 축소 덕분에 computational cost는 fully dimensionality의 single-head attention과 비슷하다.
Application of Attention in Transformer
- decoder의 "encoder-decoder attention"layer에서의 query는 이전 decoder layer로부터 계산되며, key와 value는 encoder의 출력에 해당한다.
이러한 점으로 인해, decoder의 모든 포지션에 있는 값들이 input sequence의 모든 값들을 참조할 수 있게 된다. 이는 sequence-to-sequence 모델들의 encoder-decoder attention mechanism을 모방했다고 할 수 있다.- encoder는 self-attention layer를 포함하며, 모든 key, value, 그리고 query는 이전 encoder layer의 output이라는 동일한 input sequence로부터 추출한다. encoder의 각 position들은 이전 encoder layer의 모든 position을 참조할 수 있다.
- decoder의 self attention layer 역시 비슷하게, decoder의 각각의 position들이 해당 position까지의 모든 position을 참조할 수 있도록 한다. 이 때, decoder에서의 leftward information flow를 막음으로써, auto-regressive한 성질을 보존하도록 해야 한다(미래 시점에 해당하는 position을 참조하지 못하도록 해야 함). 이러한 문제는 scaled dot-product attention부분에서 illegal connection에 해당하는 softmax input들을 로 masking out하도록 구현함으로써 해결한다.
Position-wise Feed-Forward Networks
- attention sub-layer뿐만이 아닌, encoder와 decoder의 각 layer들에는 fully connected feed-forward network가 들어있으며, 이는 각 position에 독립적으로 동등하게 적용된다.
- 해당 feed-forward network는 ReLU를 사이에 둔 두 개의 linear transformation layer로 구성되어있다.
- linear transformation은 각기 다른 position들에 대해서는 동일하게 적용되지만, layer마다 다른 파라미터를 사용한다.
- 이러한 transformation은 kenel size 1인 두 개의 convolution이 있는 것으로도 해석할 수 있다.
- input과 output의 차원은 이고 은닉층의 dimension은 이다.
Embedding and Softmax
- 다른 Sequence Transduction 모델들과 비슷하게 Transformer 역시 학습된 임베딩을 통하여 input token과 output token을 차원의 벡터로 변환한다.
- 또한, decoder output을 예측된 next-token probability로 변환하기 위해 학습이 가능한 linear transformation과 softmax 함수를 사용하였다.
- Transformer에서는, 두 개의 embedding layer와 softmax 이전의 linear transformation간의 weight를 공유한다. Embedding layer에서는 해당 weight들에 을 곱한다.
Positional Encoding
- Transformer에는 recurrence도 convolution도 들어있지 않다. 때문에, 모델에서 순서 정보를 활용하기 위해서는 sequence에 들어 있는 token들의 절대적 혹은 상대적인 위치정보를 주입해야 한다.
- 이를 위하여 encoder와 decoder stack의 최하단 input embedding에 Positional Encoding이라는 것을 더해준다.

Why Self-Attention
- 본 챕터에서는 Self-Attention layer와 recurrent, convolution layer를 세 가지 측면에서 비교한다.
- 한 가지는 layer당 total computational complexity이며 다른 하나는 병렬화될 수 있는 연산의 양(필요로 하는 Sequential한 Operation 최소 횟수)이다.
- 마지막 세번째는 네트워크의 long-range dependency들 간의 길이이다.
- Recurrent layer가 의 sequential한 operation을 필요로 하는 것에 비해 Self-Attention layer는 상수 시간 안에 이를 해결한다.
- computational complexity 측면에서 Self-Attention은 sequence length 이 representation dimensionality인 보다 작은 경우 Recurrent layer보다 빠르다.
- 목표로 하는 position의 주변 개의 input sequence만을 고려하는 경우에 self attention은 maximum path length를 로 개선할 수 있다.
