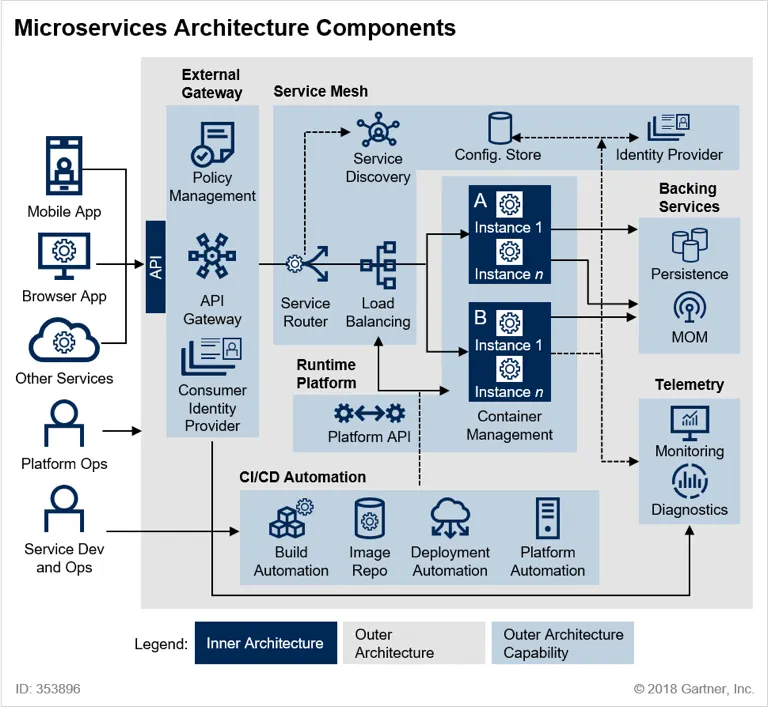
MSA 운영 요소
MSA는 서비스가 분산되기 때문에
상태를 보기 위한 모니터링,
원인을 찾기 위한 로그 수집,
데이터를 모으는 파이프라인,
이를 자동으로 운영하기 위한 컨테이너가 필수적으로 함께 사용
운영 구조
모놀로식
- 서버가 적고 구조가 단순하며 문제가 생기면 바로 눈에 보임
MSA
- 서버 수가 늘어나고 서비스 간 통신이 발생하며 장애 원인이 한눈에 보이지 않음
- 이 순간부터 운영 요소가 없으면
- MSA는 관리 불가능한 구조가 된다.
모니터링
모놀로식
- 서버 CPU 사용량만 체크
MSA
- 서비스별 CPU 체크
- 서비스별 메모리 체크
- 서비스별 응답 시간 체크
- 서비스별 에러 비율 체크
MSA에서는 서비스 상태를 수치로 계속 관찰하는 모니터링 시스템이 필수
⇒ MSA에서 모니터링은 장애 발생 후 확인이 아닌 장애 발생 전 감지를 위한 장치
대표적인 기술
- Prometheus : 각 서비스의 상태 데이터를 수집
- Grafana : 수집된 데이터를 그래프로 시각화
로그 수집
모놀로식
- 로그 파일 하나만 열어 확인
MSA
- Gateway로그 + 주문 서비스 로그 + 결제 서비스 로그 + 재고 서비스 로그 확인
- 각각 다른 서버에 로그가 흩어짐
MSA에서 로그를 각 서버에 남기는 파일이 아닌 중앙으로 모아서 분석하는 데이터
⇒ MSA에서 로그 수집은 장애 대응 속도를 결정하는 핵심
대표적인 기술
- ELK Stack
- Elasticsearch: 로그 저장
- Logstash: 로그 수집·가공
- Kibana: 로그 검색·시각화
데이터 파이프라인
모놀로식
- 하나의 DB에 모든 데이터가 저장됨
- 서비스 로그, 사용자 행동, 비즈니스 데이터가 한 곳에 모여 있음
- 단순한 쿼리로 통계 및 분석 가능
MSA
- 서비스별로 DB가 분리됨
- 회원 DB
- 주문 DB
- 결제 DB
- 로그 데이터, 이벤트 데이터도 서비스별로 분산됨
- 하나의 서비스 데이터만으로는 전체 흐름 파악이 어려움
MSA에서는 데이터가 여러 서비스와 서버에 흩어지기 때문에 데이터를 한 곳으로 모아 흐름을 만들지 않으면 운영 상태와 비즈니스 상황을 파악하기 어려움
⇒ 데이터 파이프라인은 분산된 데이터를 수집·전달·가공하여 분석 가능한 형태로 만드는 통로
데이터 파이프라인이 처리하는 데이터 예시
- 서비스 로그 데이터
- 서비스 이벤트 (주문 생성, 결제 실패 등)
- 트래픽 및 성능 지표
- 사용자 행동 데이터
대표적인 기술
- Kafka : 서비스에서 발생한 이벤트 및 데이터 스트림 수집
- Flume / Logstash : 로그 데이터 수집
- Hadoop / S3 : 대용량 데이터 저장
- Spark : 데이터 가공 및 분석
컨테이너
모놀로식
- 서버에 직접 애플리케이션 설치
- 실행 환경이 서버마다 다를 수 있음
- 배포 시 서버별 수작업 발생
- 확장 시 서버 추가 및 설정 필요
MSA
- 서비스 하나당 하나 이상의 컨테이너로 실행
- 실행 환경이 컨테이너로 표준화됨
- 서비스별 독립 배포 가능
- 트래픽에 따라 서비스 단위로 확장 가능
MSA는 서비스 수가 많고 배포와 확장이 빈번하기 때문에
수동 서버 관리 방식으로는 운영이 불가능함
⇒ 컨테이너는 MSA 환경에서
서비스 실행·배포·확장을 자동화하기 위한 필수 기술
컨테이너가 해결하는 문제
- 실행 환경 불일치 문제 해결
- 빠른 배포 및 롤백
- 서비스 단위 확장 및 축소
- 장애 발생 시 자동 재시작
대표적인 기술
- Docker : 애플리케이션 실행 환경을 컨테이너로 패키징
- Kubernetes : 컨테이너 오케스트레이션
- 자동 배포
- 자동 스케일링
- 장애 복구
- 서비스 디스커버리

Bello! NewOld velog~