카프카 (consumer)

카프카 컨슈머는 특정 토픽에서 파티션을 조회하는 역할을 한다.
서버, 그룹 아이디 지정 후 메시지를 읽어 와서 역직렬화 하기 위한 설정을 하고 그 설정을 이용해서 카프카 컨슈머 객체를 생성한다.
그리고 컨슈머에 subscribe메서드를 호출하고 이 메서드를 호출할 때 내가 구독할 토픽 목록을 전달한다.
특정 조건을 충족하는 동안 그 풀을 돌면서 컨슈머에 poll 메서드를 호출하고 이 poll 메서드는 일정 시간 동안 대기하다가 브로커로 부터 컨슈머 레코드 목록을 읽어온다.
그리고 이 컨슈머 레코드를 또 루프를 돌면서 필요한 처리를 한다.
다 사용한 다음에 close 메서드를 이용해 닫아 준다.
토픽 파티션은 그룹 단위 할당
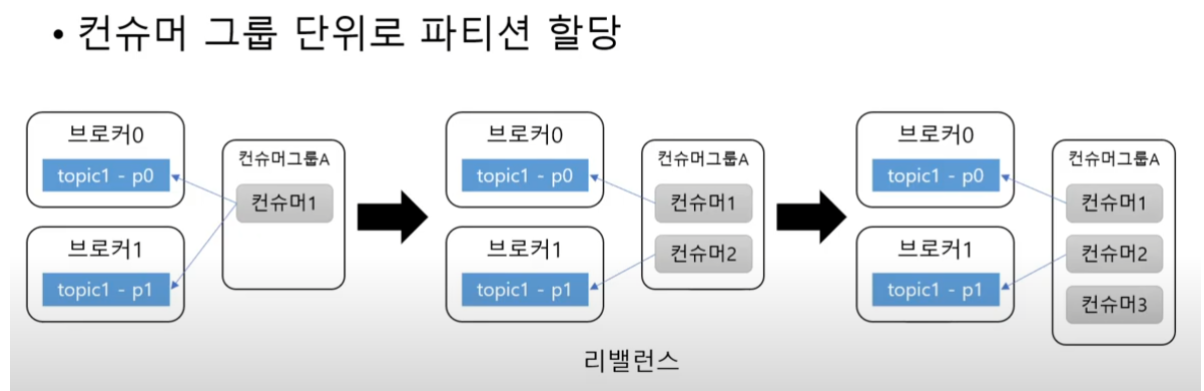
토픽 파티션은 그룹 단위로 할당이 된다.
이때 이 그룹은 위에 코드에서 그룹 아이디로 지정한 그 값이 바로 그룹이 된다.
파티션 개수와 컨슈머 개수는 밀접하게 관련이 되어있고 파티션 개수보다 컨슈머 그룹이 많아지게 되면 컨슈머는 놀게 된다.
예)
파티션이 2개 있는 토픽이 있다고 가정을 해보자
파티션이 2개이고 컨슈머는 1 개이다, 이럴 때는 컨슈머 1개가 2개의 파티션 으로부터 데이터를 읽어오게 된다.
그런데 이 상황에서 컨슈머를 1개 더 추가하게 되면 위에 그림처럼 각 컨슈머가 파티션에 연결이 된다.
그런데 파티션 보다 더 많은 컨슈머가 생기게 되면 이후로 생긴 컨슈머는 놀게 된다.
주의할 점은 컨슈머 개수가 파티션 개수보다 커지면 안되는 것이다.
만약 처리량이 떨어져서 컨슈머를 늘려야 한다면 파티션 개수도 함께 늘려야 한다.
커밋과 오프셋
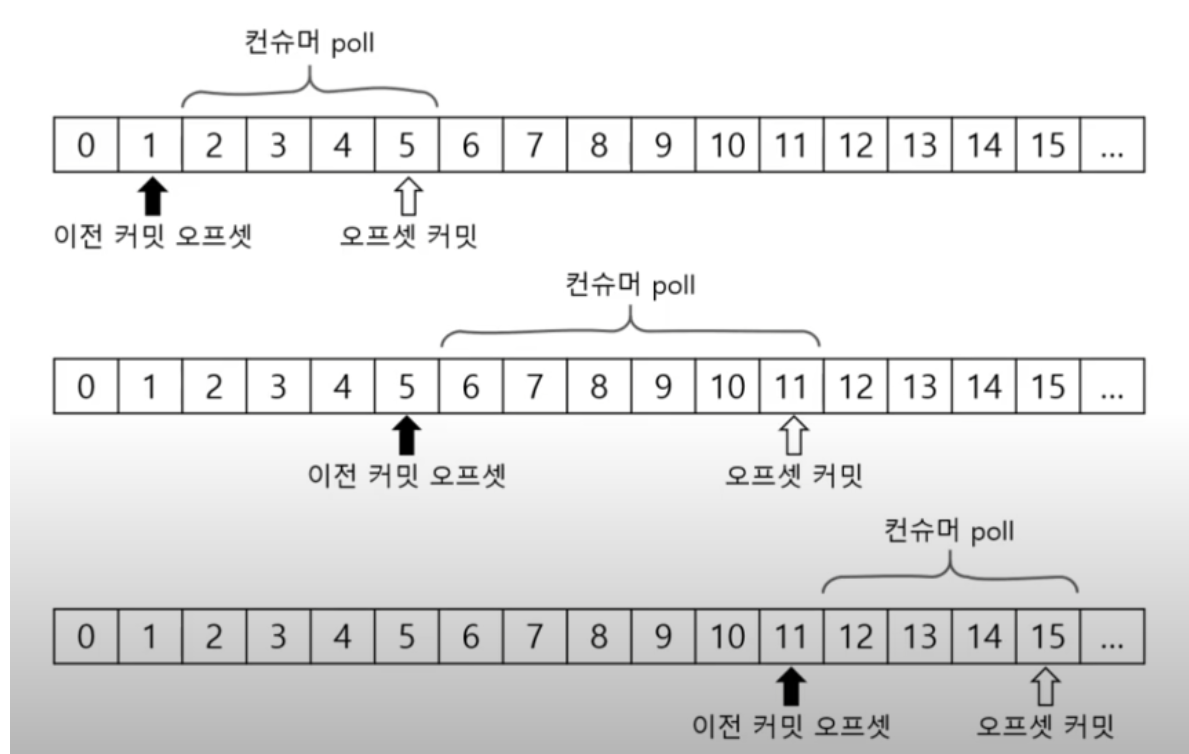
컨슈머에 poll 메서드는 이전에 커밋한 오프셋이 있으면 그 오프셋 이후에 레코드를 읽어온다.
마지막에 읽어온 레코드에 오프셋을 커밋을 한다, 그리고 poll 메서드를 사용하면 앞서 커밋한 오프셋 이후로 레코드를 읽어온다, 또 읽어온 레코드에 오프셋을 커밋한다.
이 과정을 계속 반복을 한다.
커밋된 오프셋이 없는 경우

만약에 커밋된 오프셋이 없는 경우 auto.offset.reset 설정을 한다.
이 값은 3가지 값을 지정할 수 있는데
- eariliest
- latest
- none
이 3가지가 있다, none을 지정하면 이셉션이 나오기 때문에 대게 사용하지 않는다.
컨슈머 설정

컨슈머 조회에 영향을 주는 설정이 크게 3가지 있다
- fetch.min.bytes
브로커가 전송할 최소 데이터 크기를 지정한다, 즉 poll 메서드로 브로커에 요청을 하면 브로커가 이 설정 값 이상의 데이터가 쌓일 때까지 기다렸다가 준다, 그래서 이 값이 크면 대기 시간이 늘지만 처리 량이 증가하는 효과를 볼 수 있다.
- fetch.max.wait.ms
데이터가 최소 크기가 될 때까지 기다리는 시간이다.
데이터가 최소 크기가 되지 않는다고 무한정 기다릴 수 없으니 기다리는 최대의 시간을 지정하는 것이다.
기본 값은 0.5초 이고 주의할 점은 이 시간은 브로커가 최소 데이터를 모으기 까지 대기하는 시간이기 때문에 poll() 메서드에 인자 값으로 전달하는 시간과는 다르다
- max.partition.fetch.bytes
파티션 당 서버가 리턴 할 수 있는 최대 크기를 지정한다, 이 최대 크기가 넘어가면 바로 리턴을 한다.
자동 커밋/수동 커밋
자동 커밋

- enable.auto.commit
이 설정의 기본 값은 true 이고 이 값이 true 이면 일정 주기로 컨슈머가 읽은 오프셋을 커밋하게 된다.
이 일정 주기는 아래의 auto.commit.interval.ms 로 지정하게 된다.
- auto.commit.interval.ms
이 자동 커밋 주기의 기본 값은 5000이다
-
poll(), close() 메서드 호출 시 자동 커밋 실행
수동 커밋

수동 커밋은 동기와 비동기 둘 중 하나로 처리할 수 있다
먼저 commitSync 메서드를 이용한 동기 커밋이 있다, 이 commitSync 메서드는 커밋이 성공하면 exception이 발생하지 않고 커밋에 실패하면 exception이 발생한다
commitAsync 메서드를 사용하면 비동기로 커밋을 하게 된다, 비동기기 때문에 코드 자체에서 바로 실패 여부를 알 수 없고 만약에 성공 실패 여부를 알고 싶다면 콜 백을 받아서 처리를 해야 한다.
재처리와 순서

카프카를 사용할 때 주의할 점은 컨슈머가 동일한 메시지를 읽어올 수 있다는 것이다.
일시적으로 커밋에 실패하거나 새로운 컨슈머가 생기거나 빠지는 등 리밸런스가 발생하는 경우에 동일한 메시지를 수신할 수 있게 된다.
그래서 컨슈머는 멱등성을 고려해서 구현해야 한다.
세션 타임아웃, 하트비트, 최대 poll 간격

카프카는 컨슈머 그룹을 알맞게 유지하기 위해서 몇 가지 설정을 사용한다.
그 설정 중 하나가 하트비트와, 세셧 타임아웃이다.
컨슈머는 하트비트를 계속해서 브로커에 전송을 하고 이를 통해서 연결을 유지한다.
이 브로커는 일정 시간 동안 컨슈머로 부터 하트 비트가 없으면 그 컨슈머를 그룹에서 뺀다, 그리고 리밸런스를 진행한다.
하트비트 연결 유지와 관련된 설정
- session.timeout.ms
지정한 시간 동안 하트 비트가 없으면 컨슈머가 올바르지 않다고 생각하고 컨슈머를 제외한다.
- heartbeat.interval.ms
하트 비트를 어느 정도 주기로 보낼 건 지를 설정한다.
- max.poll.interval.ms
poll() 최대 호출 간격을 지정한다, 이 시간이 지나도록 poll 하지 않으면 컨슈머를 그룹에서 빼고 리밸런스를 진행한다.
종료 처리

컨슈머를 다 사용하고 나면 close 메서드를 사용해서 종료 처리를 한다.
보통은 무한루프를 돌면서 poll 메서드로 레코드를 읽어 오는 코드를 작성하게 되는데, 이 루프를 벗어날 수 있는 게 바로 wakeup 메서드 이다
다른 쓰레드에서 wakeup 메서드를 호출하면 poll 메서드는 wakeupException을 발생 시킨다, 이 exception을 while문 바깥에서 캐치를 하고 컨슈머의 close 메서드를 호출한다.
주의 : 쓰레드 안전하지 않음

컨슈머를 사용할 때 주의할 점은 KafkaConsumer는 쓰레드에 안전하지 않다는 것이다.
그래서 여러 쓰레드에서 KafkaConsumer 객체를 동시에 사용하면 안된다.
wakeup() 메서드는 예외
출처