교육 정보
- 교육 명: 경기미래기술학교 AI 교육
- 교육 기간: 2023.05.08 ~ 2023.10.31
- 오늘의 커리큘럼: 노코드 DDDT(5/8 ~ 5/9)
- 강사: 정선미 강사님
- 강의 계획:
1. 데이터리터러시, 데이터 수집 및 분석
2. 소셜데이터 활용, 프로젝트
상관, 회귀분석
기술통계
-
기술통계란?
한 항목에 대한 값들의 평균, 표준편차, 최대값, 최소값, 신뢰수준등을 분석하는 방법
-
실습
엑셀에서 데이터-데이터분석-기술통계법 → 분석하고자 하는 데이터 선택
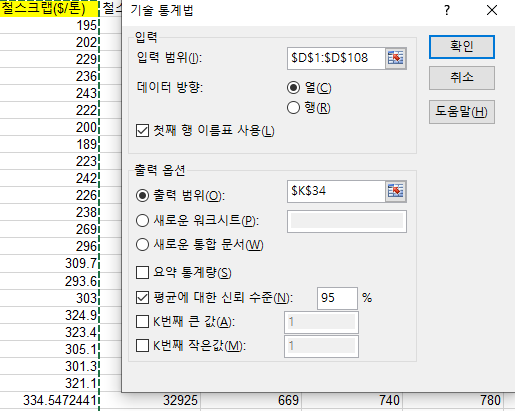
기술 분석은 데이터가 작아서 이것만으로 의사 결정하기 어려움
표준 편차가 작은 경우 값 변동성이 작음을 알 수 있음
상관분석
-
상관분석이란?
키워드 간의 상관성을 분석하는 방법
-
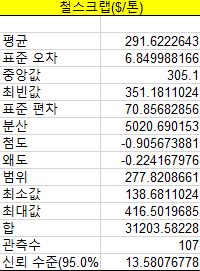
실습
서로 다른 키워드의 데이터를 상관분석법으로 분석함
-
다운로드 한 데이터를 엑셀에서 데이터-데이터분석-상관분석 → 분석하고자 하는 데이터 선택
실습1
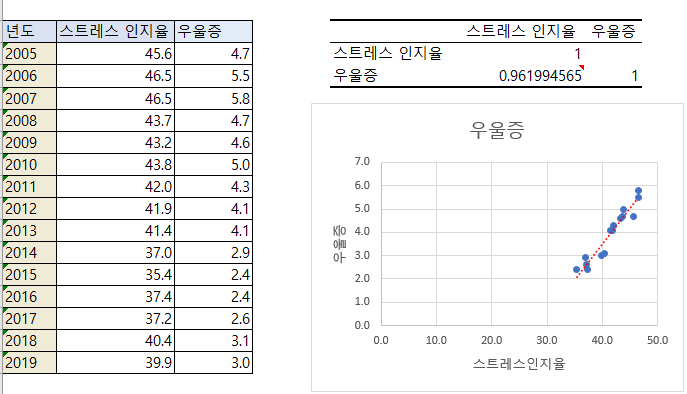
실습2
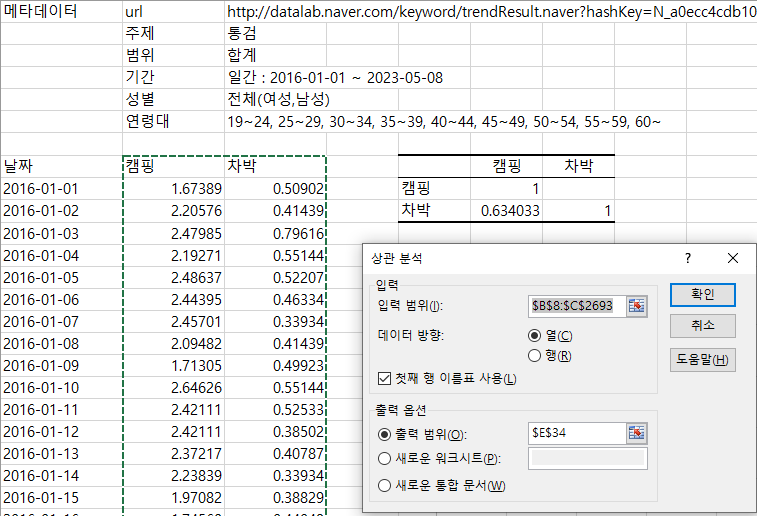
상관지수는 -1~1사이고 이 값이 0에서 멀 수록 상관 관계가 높다고 평가
유효 상관지수는 데이터에 따라 다름
→ 보통 -0.7이하 0.7이상이면 상관관계가 있다고 봄
우상향 그래프- 양의 상관관계
좌상향 그래프- 음의 상관관계 ex. 코로나 확진률과 자영업매출
-
상관분석데이터 얻기
데이터까지 다운로드 할 경우 - 캠핑-차박, 더위-아아(아이스아메리카노)등 연관이 있는 데이터를 네이버 데이터 랩을 통해 다운로드 한다. [https://datalab.naver.com](https://datalab.naver.com/) 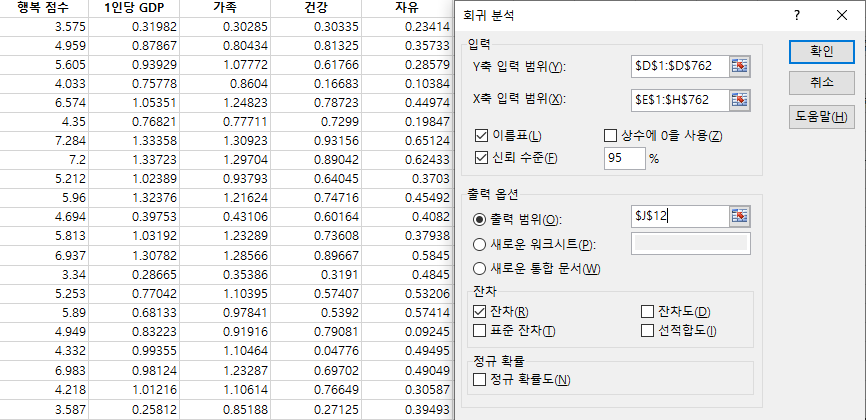 국가통계포털사이트 https://kosis.kr/index/index.do상관분석은 상관성을 확인하는것이고 회귀분석은 미래를 예측하는 것
-
회귀분석
- 회귀분석이란? 회귀분석이란 상관분석은 상관성을 확인하는것이고 회귀분석은 미래를 예측하는 것
단순 회귀분석을 해보려고 함 1인당 GDP에 행복점수를 분석해보려고 함 고려할 사항 시간적 선후관계 공변성 비허위성 시간적 선후 관계 및 공변성이 만족된다면 상관관계는 있지만 비허위성을 만족하지 못하는 경우에서는 인과관계를 만족하는 것이 아님 → 세가지 다 만족해야지만 원인과 결과를 모두 만족한다고 볼 수 있음 회귀분석에서 x와 Y는? Y 결과 변수, 종속변수라고 함 → 여기서는 행복점수 X 원인변수, 독립변수라고 함 → 여기서는 GDP
EX 연봉과 연차→ 연차가 올라가면 연봉이 올라간다 (O)/연봉이 올라가면 연차가 올라간다(X)
-
실습
엑셀에서 데이터-데이터분석-회귀분석 → 분석하고자 하는 데이터 선택
결과
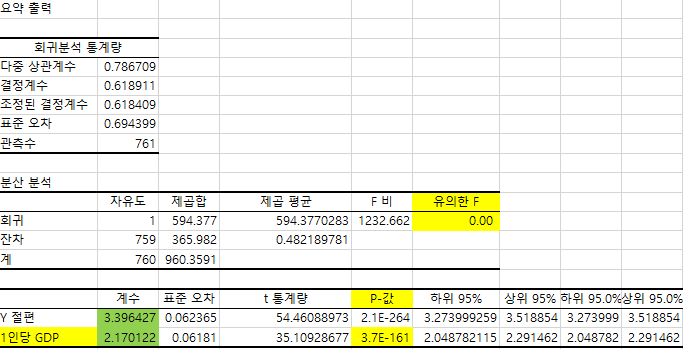
결정 계수 → 0에서 1사이의 값을 가짐 (실무에서는 R^2 알스퀘어 라고 사용함) → Y의 값 변동을 X가 결정계수 정도로 설명 할수 있는 인과관계가 있다 정도로 이해 /강하다 약하다는 아님높아야 인과관계가 있다는 느낌
회귀식이 유의한지 확인하기 위해서는 우선 결정계수가 높아야 하고 결정계수가 높더라도 그 전에 유효성 검증을 해야 함
-
유의한 F가 0.05이하여야 함
-
X에 대한 P값 (P value) 가 0.05이하여야 함
추가 정보
잔차오차와 같은 맥락임/한 값의 추세선에 대한 차이→ 잔차를 모두 더하면 0 (혹은 0에 수렴하는 값)이 나옴/보통 유의성 검사를 두개만 하지만 잔차까지 확인할 때도 있음
-
-
차원의 저주
실습시 사용한 데이터인 행복지수에는 이 4개 외에도 많은 변수가 있는데 여기서는 왜 4개만 골랐을까?
차원의 저주
-
차원의 저주란?
→ 변수가 증가함에 따라 신뢰도가 올라가다가 그 이후 떨어지는 현상
→ 적절한 변수의 수는 데이터에 따라 다른데, 이런 부분에 대한 검증을 머신러닝, 인공지능이 인간 대신 해주고 있다
→ 본 데이터에서는 회귀분석을 해서 상관성이 높은 변수 4개만 고른거임!
-
- 추가 실습- 보스턴 집값을 분석해보기 머신러닝에 많이 사용되는 보스턴 집값데이터를 회귀분석 방법으로 분석 해보기 회귀분석 방식
-
필요없어보이는 변수 제거
-
상관성이 높은 변수 선정 (상관분석)
→ 상관분석이 가능한 값 (숫자)로 변경-이런 과정을 맵핑이라고 함
위 작업은 엑셀로 해도 되고 파워쿼리 사용해도 됨 (새쿼리-데이터에서)
-
추가 실습 - DATA THINKING
최근 많이 사용되는 단어인 “갓생”에 대한 키워드를 수집하고 분석해보기
-
주제를 토대로 웹 크롤링 - 연관있는 키워드 수집
주제: 갓생 No. 키워드 1 부지런 2 MZ세대 3 인생 4 모범 6 성실 7 본분 8 루틴 9 성취감 10 만족감 11 무기력 12 코로나 13 보람 14 스스로 -
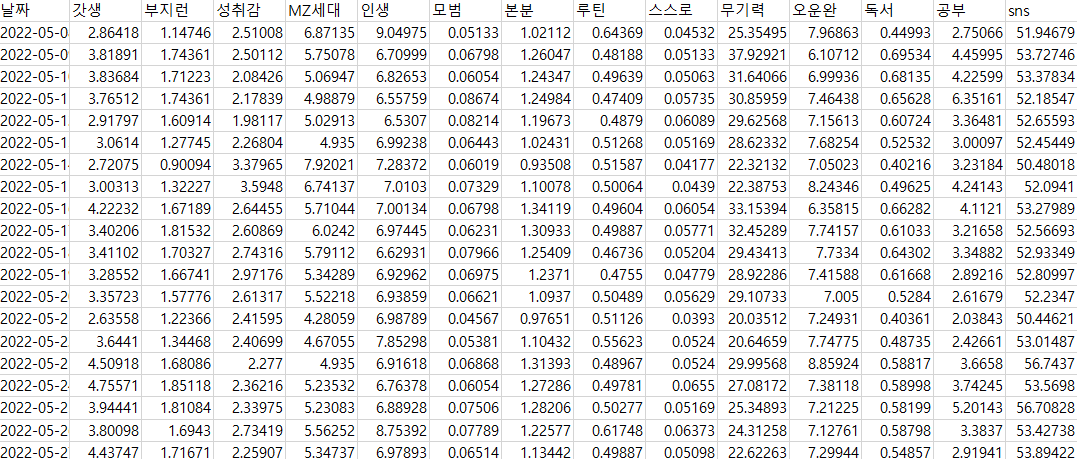
수집한 키워드를 네이버 데이터 랩을 통해 검색- 데이터 수집
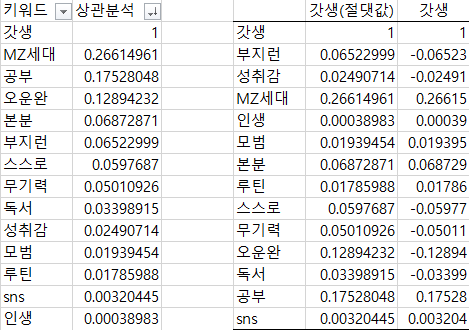
- 수집한 데이터를 상관분석 방식으로 분석하여 각 키워드가 주제에 얼마나 관계가 있는지 확인
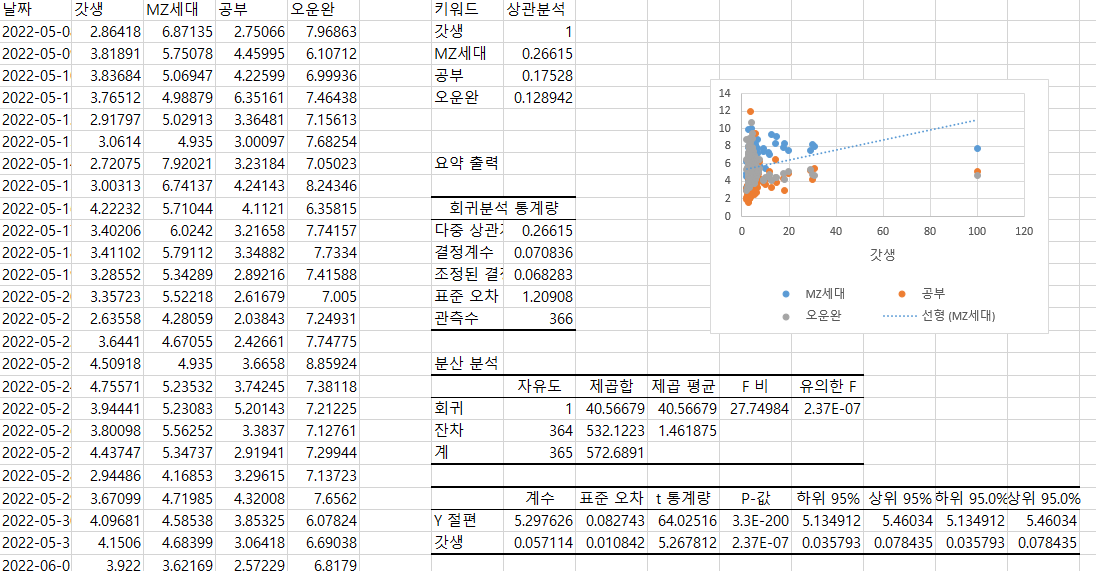
- 상관성 높은 키워드를 선정하여 회귀분석 진행
- 결과
- 전반적으로 수집한 키워드가 갓생이라는 주제와 상관성이 떨어져서 수집한 키워드 중 절대값이 큰 순으로 3개의 키워드를 선정하였다.
- 회귀분석을 진행하였을 때 유의한F와 P값은 0.05를 넘었으나 결정계수는 낮았는데 데이터 자체의 상관성이 낮기 때문으로 보인다.
- 개선방안
- 더 직접적인 연관성이 있는 키워드를 수집(인생, 성실 등은 너무 포괄적인 키워드)
- 주제(갓생)를 사용하는 연령대인 20~30대를 위주로 데이터를 확보
