교육 정보
- 교육 명: 경기미래기술학교 AI 교육
- 교육 기간: 2023.05.08 ~ 2023.10.31
- 오늘의 커리큘럼: 빅데이터 기초 활용 역량 강화 (5/10~6/9) - 데이터 수집
- 강사: 조미정 강사님 (빅데이터, 머신러닝, 인공지능)
- 강의 계획:
1. 파이썬 언어 기초 프로그래밍
2. 크롤링 - 데이터 분석을 위한 데이터 수집(파이썬으로 진행)
3. 탐색적 데이터 분석, 분석 실습
- 분석은 파이썬만으로는 할 수 없으므로 분석 라이브러리/시각화 라이브러리를 통해 분석
4. 통계기반 데이터 분석
5. 미니프로젝트
1. 데이터 분석
데이터 분석의 목적
- 데이터 분석의 목적은 과거의 데이터를 토대로 미래를 분석하는 것이다.
- 과거에 어떤 일이 일어났는지 파악하고
- 과거에 일어난 일에 어떤 원인이 있는지 분석하고
- 분석을 토대로 앞으로 어떤 일이 일어날지 예측한다.
→ 추후 의사결정에서 불확실성을 해소할 수 있다.
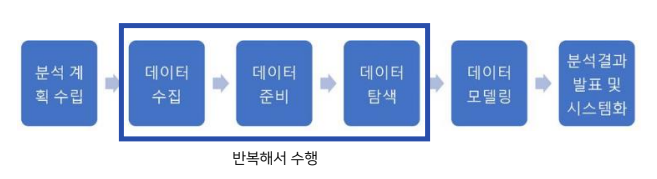
데이터 분석의 과정
- 데이터 분석의 과정
- 분석 계획 수립
- 해결하고자 하는 문제가 무엇인지, 해결을 위해 어떤 데이터를 수집해야할지(데이터의 출처, 발생 기간 등), 수집한 데이터를 어떻게 분석할지, 최종적으로 어떤 결과를 도출하고자 하는지 계획을 수립하는 단계
- 데이터 수집
- 분석계획에 맞춰 목적에 맞는 데이터를 수집하면서 데이터 사용에 문제(개인 정보 침해 등)가 없도록 확인
- 데이터 준비
- 수집한 데이터를 사용할 수 있게 수정하거나 정제하는 단계. 데이터 전처리(Pre_processing)라고도 함
- 데이터 분석에서 가장 많은 시간을 소요하는 과정이기도 함
- 데이터 탐색
- 변수간의 관련성, 패턴 존재 여부등을 확인하는 데이터 분석 과정. 그래프 등을 많이 사용
- 데이터 모델링
- 변수를 선택하여 모델을 구성
- 분석 결과 발표 및 시스템화
- 분석과정을 발표하고 자동화 함
참고 - 데이터의 형태
- 데이터는 형태에 따라 정형 데이터, 반 정형 데이터, 비정형 데이터로 나눌 수 있음
- 정형 데이터 (Structured Data)
- 엑셀, 관계형 데이터베이스(RDB)의 데이터 등 구조화된 데이터
- 반정형 데이터 (Semi-Structured Data)
- 구조화 되었지만 데이터 안에 해당 구조에 대한 설명이 있어서 파싱(parsing)이 필요한 데이터. HTML, JSON 문서 등
- 비정형 데이터 (Unstructured Data)
- 정해진 구조가 없는 데이터. SNS 텍스트나 이미지, 영상 등
크롤링
- 웹페이지에 존재하는 컨텐츠를 수집하는 작업
- HTML/CSS Parsing
- Open API 활용
- 파이썬의 requests(데이터를 가져옴), BeautifulSoup(가져온 데이터를 parsing) 라이브러리를 사용하여 웹 페이지의 데이터를 가져오고 파싱해보기
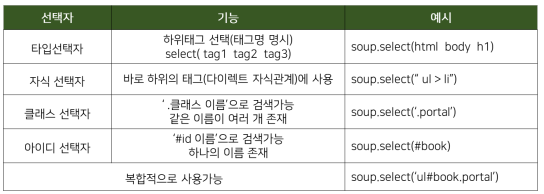
CSS selector
페이지 요청
requests 라이브러리를 사용하여 웹페이지에서 소스 받아오기
import requests url = "http://example.com" res = requests.get(url) print(res.status_code) # print(res.text) #이걸로 모든 소스코드를 가져올 수 있음 print(type(res.text)) # 하지만 타입이 str이라서 데이터 가져오기 어려움 -> 파싱해야 함 # # 결과 200 # response의 status code가 200이면 데이터를 잘 받아온것 (HTML status code 참고) <class 'str'> # response.text로 받아온 데이터는 str 타입이라서 데이터를 가져오기 어려우므로 파싱해서 가져와야 함
데이터 추출
BeautifulSoup 라이브러리를 사용하여 HTML문서를 파싱하여 원하는 데이터만 받아오기
예시 HTML문html = ''' <!doctype html> <html> <head> <meta charset="utf-8"> <title>이것은 html예제입니다</title> </head> <body> <h1>New book Information</h1> <img src='https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcS0viO8Xa1JqS_OSsHYlxdaMimrAXUnfIkYaA&usqp=CAU'/> <p id ="book_title">재미있는 파이썬</p> <p id="author">파이썬그룹</p> <a href='http://google.com'>more information...</a> <p id ="book_title">토지</p> <p id="author">박경리</p> <p id ="book_title">태백산맥</p> <p id="author">조정래</p> <h1>자주가는 사이트 모음</h1> <p id="contents">이 곳은 자주가는 사이트를 모아둔 곳입니다</p> <a class = "portal" href='https://www.google.com' id="google">구글</a> <a class = "portal" href='https://www.naver.com' id="naver">네이버</a> <a class = "portal" href='https://www.daum.com' id="daum">다음</a> </body> </html> '''에서 데이터를 파싱해보기
from bs4 import BeautifulSoup soup = BeautifulSoup(html, "html.parser") # BeautifulSoup사용하여 html문을 파싱함 print(type(soup)) # #결과 <class 'bs4.BeautifulSoup'> # HTML문이 bs4.BeautifulSoup 형태로 저장되어있음 → soup.select()문을 사용하여 원하는 데이터를 추출할 수 있음
- 태그로 찾기
태그로 데이터를 가져올때에는 soup.select("tag명")형태로 찾음print(soup.select("head")) print(soup.select("p")) # #결과 #head태그의 내용을 여는 태그부터 닫는 태그까지 전부 받아옴 [<head> <meta charset="utf-8"/> <title>이것은 html예제입니다</title> </head>] # 찾고자 하는 태그가 여러개 있으면 전체를 리스트처럼 받아옴 [<p id="book_title">재미있는 파이썬</p>, <p id="author">파이썬그룹</p>, <p id="book_title">토지</p>, <p id="author">박경리</p>, <p id="book_title">태백산맥</p>, <p id="author">조정래</p>, <p id="contents">이 곳은 자주가는 사이트를 모아둔 곳입니다</p>] #받아온데이터는 아래의 포멧을 가짐 → 추가 가공 가능 <class 'bs4.element.ResultSet'>
- 같은 태그가 여러개일때 하나씩 받아오기
print(soup.select_one("p")) # #결과 <p id="book_title">재미있는 파이썬</p>
- 태그 안의 text 가져오기
p_list = soup.select("p")) for p_content in p_list: print(p_content) # 여는 태그부터 닫는 태그까지 다 보여줌 print(p_content.text) # .text를 사용하면 해당 태그의 본문 (text)만 받아옴 # #결과 <p id="book_title">재미있는 파이썬</p> 재미있는 파이썬 <p id="author">파이썬그룹</p> 파이썬그룹 <p id="book_title">토지</p> 토지 <p id="author">박경리</p> 박경리 <p id="book_title">태백산맥</p> 태백산맥 <p id="author">조정래</p> 조정래 <p id="contents">이 곳은 자주가는 사이트를 모아둔 곳입니다</p> 이 곳은 자주가는 사이트를 모아둔 곳입니다
- 상위 하위 태그 지정하여 받아오기
soup.select("body p") # body 아래의 모든 p 태그를 받아오기 (상위태그 띄어쓰기 하위태그) soup.select("body > p") # body "바로"아래의 p 태그만 받아오기 (상위태그 > 하위태그) # #결과 [<p id="book_title">재미있는 파이썬</p>, <p id="author">파이썬그룹</p>, <p id="book_title">토지</p>, <p id="author">박경리</p>, <p id="book_title">태백산맥</p>, <p id="author">조정래</p>, <p id="contents">이 곳은 자주가는 사이트를 모아둔 곳입니다</p>] [<p id="book_title">재미있는 파이썬</p>, <p id="author">파이썬그룹</p>, <p id="book_title">토지</p>, <p id="author">박경리</p>, <p id="book_title">태백산맥</p>, <p id="author">조정래</p>, <p id="contents">이 곳은 자주가는 사이트를 모아둔 곳입니다</p>] # 본 예시에서는 모든 p 태그가 body 태그의 바로 아래 있으므로 결과가 같음
- id로 찾기
- id명으로 찾을때는 soup.select("#id명")형태로 찾음
soup.select("#book_title") # id = book_title인 경우를 조회 soup.select("p#book_title") #p 태그안에 id = book_title인 경우만 조회 # #결과 [<p id="book_title">재미있는 파이썬</p>, <p id="book_title">토지</p>, <p id="book_title">태백산맥</p>] [<p id="book_title">재미있는 파이썬</p>, <p id="book_title">토지</p>, <p id="book_title">태백산맥</p>] # 본 예시에서는 모든 book_title이 p 태그하에 있으므로 결과가 같음
- 클래스로 찾기
- 클래스 명으로 찾을때는 soup.select("tag명.class명") 형태로 찾음
print(soup.select(".portal") # 전체 portal 클래스 조회 print(soup.select("p.portal") # p태그의 portal 클래스 조회 # #결과 [<a class="portal" href="https://www.google.com" id="google">구글</a>, <a class="portal" href="https://www.naver.com" id="naver">네이버</a>, <a class="portal" href="https://www.daum.com" id="daum">다음</a>] []
- 속성으로 찾기
- 이미 가져온 데이터 (여는태그부터 닫는 태그까지)에서 특정 속성 값만 가져오고 싶은경우
→ 속성들은 dict형태로 저장되어있기 때문에 dict의 value 접근하듯이 가져 올 수 있음print(soup.select_one("a.portal")["href"]) print(soup.select("#book_title")[0].text) # #결과 https://www.google.com 재미있는 파이썬

:D