교육 정보
- 교육 명: 경기미래기술학교 AI 교육
- 교육 기간: 2023.05.08 ~ 2023.10.31
- 오늘의 커리큘럼:
머신러닝
(7/17 ~ 7/28)- 강사: 이현주, 이애리 강사님
- 강의 계획:
1. 머신러닝
데이터 처리 및 시각화 기법
데이터 처리 및 시각화 기법
- histogram hue (group)
- seaborn (hue, multiple)
- plotly (color, barmode)
seaborn
sns.histplot(data=전체데이터,
x=data',
hue=범주,
multiple=시각화 타입(“layer”, “dodge”, “stack”, “fill”),
shrink=그룹당 넓이
)plotly
px.histogram(x=data,
color=범주,
barmode=시각화 타입("group", "relative", "overlay")
)sns.histplot(data=df,
x='Sleep Disorder',
hue='Gender',
multiple="dodge",
shrink=.8)
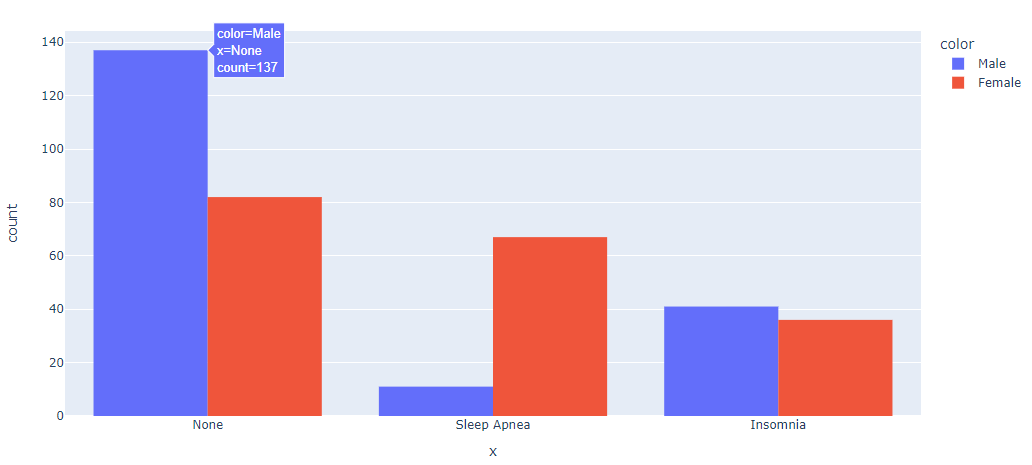
fig = px.histogram(x=df['Sleep Disorder'], color=df['Gender'], barmode='group')
fig.show()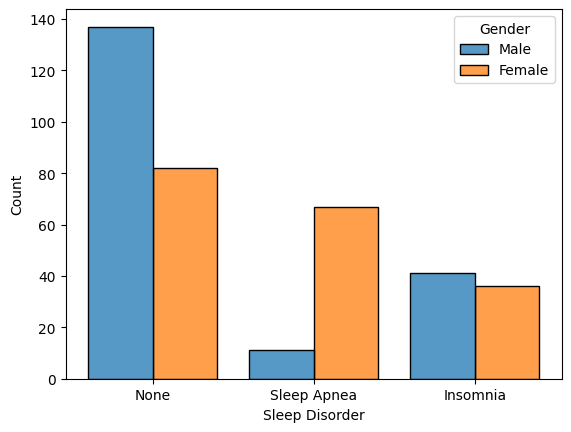
- 수치형 데이터 범주화
- if 문
- pandas.cut()
if 문
age_ranges = [(0, 19), (20, 29), (30, 39), (40, 49), (50, 59), (60, 100)]
class_labels = ['0-19', '20-29', '30-39', '40-49', '50-59', '60+']
def age_classifier(age):
for idx, (lower, upper) in enumerate(age_ranges):
if (lower <= age <= upper):
return class_labels[idx]
df['Age_Range'] = df['Age'].apply(age_classifier)
df['Age_Range'].value_counts()
#
# 결과
30-39 142
40-49 117
50-59 96
20-29 19
Name: Age_Range, dtype: int64pandas.cut()
pandas.cut(data,
bins (데이터를 자를 갯수 혹은 기준 array),
right=True(우측값 포함 여부),
labels=구간에 따른 라벨,
retbins=False(라벨 기준 반환 여부),
precision=3,
include_lowest=False(맨 처음 값 포함 여부),
duplicates='raise'(범위가 겹칠때 값 처리 방법),
ordered=True
)📕 <주의> retbins를 True로 하면 객체가 하나 추가되면서 전체 데이터 길이가 2가 되므로 배열을 사용하기위해서는 지정해줘야 함
참고
[] 대괄호: 이상, 이하
() 소괄호: 초과, 미만
# age_ranges = [(0, 19), (20, 29), (30, 39), (40, 49), (50, 59), (60, 100)]
age_ranges = [0, 19, 29 ,39 ,49 ,59, 100]
class_labels = ['0-19', '20-29', '30-39', '40-49', '50-59', '60+']
df['Age_Range'] = pd.cut(df['Age'], bins=age_ranges, labels=class_labels)
df['Age_Range'].value_counts()
#
# 결과
30-39 142
40-49 117
50-59 96
20-29 19
0-19 0
60+ 0
Name: Age_Range, dtype: int64서포트 벡터 머신(SVM) - 분류
SVM 개요
https://scikit-learn.org/stable/modules/generated/sklearn.svm.SVC.html
딥러닝이 떠오르기전까지 머신러닝 분야에서 가장 인기가 높은 데이터 분류 방법
현재의 데이터를 잘 분리하면서도, 새로운 데이터가 들어왔을 때에도 분리를 잘 할 수 있는 결정경계를 찾는 것
SVM은 두 데이터 그룹을 나누는 평면 중에서 폭이 가장 넓은 것을 찾는 방법이고, 이 분리 평면은 결정 경계라고도 한다.
결정 경계면은 2차원에서는 직선이지만 그 이상의 차원에서는 가시화할 수 없는 평면으로 초평면hyperplane이라고 부른다.
결정 경계와 서포트 벡터 사이의 거리를 마진margin이라고 부른다.
마진 결정에 영향을 미치는 데이터들이 서포트 벡터support vector, 지지 벡터라고 한다.
하드 마진hard margin 어떠한 데이터도 이 마진 내에 들어오지 않는다.
어떤 경우에는 마진 안에 아무런 데이터도 들어오지 않도록 하는 것이 불가능할 수도 있다. 그리고 불가능하지는 않더라도 어떤 데이터는 잡음이나 이상치로 판단하여 무시하는 것이 좋을 수도 있다. 이럴 때는 일부 데이터가 마진 내에 들어오도록 허용하면서 분리 평면을 찾을 수 있다. 이것은 소프트 마진soft margin이라고 부른다.
하드 마진을 사용할 경우에는 분류가 안될 수도 있고, 잡음에 민감할 수밖에 없으므로 소프트 마진을 사용하는 것이 바람직하다. 잡음에 민감하다는 것은 데이터에 과적합 된다는 의미이다. 따라서 소프트 마진을 사용하는 것도 모델 규제 혹은 정칙화의 일종이라 볼 수 있다.
소프트 마진을 사용할 때는 마진 내에 들어갈 수 있는 데이터의 수를 제어한다. 이 값을 제어하는 변수를 슬랙slack 변수라고 부른다.
SVM은 분류오류와 마진에러를 모두 줄이는 방향으로 학습을 진행하되 두 오류 중 어느 오류를 더 줄이는 방향으로 할지 대한 정책을 정해야 한다.
분류오류와 마진에러최소화 사이의 트레이드오프
분류 오류와 마진 에러 간의 트레이드오프를 결정하기 위하여 필요한 파라미터가 바로 C(cost의 약어)라고 하는 하이퍼파라미터이다.
SVM 오류는 C*분류 오류 + 마진 에러로 이루어져있다
C값은 기본 1 , 클수록 하드마진 (즉, 오류 허용 안 함), 작을수록 소프트마진(즉, 오류를 허용함)
하이퍼라파미터
C (Cost, Penalty Parameter): C는 SVM 모델에서 오분류에 대한 패널티를 조절하는 하이퍼파라미터입니다. C 값이 클수록 오분류에 대한 패널티가 커지므로, 결정 경계를 훈련 데이터에 더욱 맞추려고 할 것입니다. 이는 모델이 훈련 데이터에 더 맞추려고 하므로 복잡한 결정 경계를 만들어낼 수 있습니다. 그러나 C 값이 너무 크면 오버피팅(overfitting)의 위험이 있을 수 있습니다. 반대로 C 값이 작으면 오분류에 대한 패널티가 작아지므로, 마진을 넓게 유지하려고 할 것이며, 결정 경계가 단순해질 수 있습니다. C 값은 교차 검증을 통해 적절한 값을 설정
커널 (Kernel): SVM은 기본적으로 선형적으로 구분되지 않는 데이터셋을 처리하기 위해 고차원으로 매핑하는데, 이때 사용하는 함수를 커널이라고 합니다. 커널은 데이터를 고차원 특징 공간으로 변환하는 함수로, 기본적으로는 선형 커널(linear kernel)을 사용하지만, 비선형 데이터셋을 다루기 위해 다양한 커널 함수를 사용
선형 커널 (Linear Kernel): 가장 기본적인 커널로, 입력 데이터를 그대로 사용합니다.
다항 커널 (Polynomial Kernel): 주어진 차수에 따라 다항식을 계산하여 데이터를 변환합니다.
가우시안 RBF 커널 (Gaussian Radial Basis Function Kernel): 가우시안 분포를 기반으로 데이터를 고차원으로 변환합니다.
시그모이드 커널 (Sigmoid Kernel): 하이퍼볼릭 탄젠트를 이용하여 데이터를 변환
감마 (Gamma): 감마는 가우시안 RBF 커널과 시그모이드 커널에서 사용되는 하이퍼파라미터입니다. 감마 값이 크면 고차원 공간에서 더 가까운 데이터 포인트들만 영향을 주게 됩니다. 이로 인해 결정 경계가 더욱 구불구불해지며, 모델이 훈련 데이터에 더욱 적합해질 수 있습니다. 감마 값이 작으면 더 넓은 영역의 데이터 포인트들이 영향을 주게 됩니다. 이는 결정 경계가 더 부드러워지고 일반화 성능이 향상
- SVM
from sklearn.svm import SVC
# SVM 모델 생성 및 학습
svm_model = SVC()
svm_model.fit(X_train, y_train)
# 테스트 데이터로 예측
y_pred = svm_model.predict(X_test)
from sklearn.metrics import confusion_matrix
# 혼동행렬 출력
cm = confusion_matrix(y_test, y_pred)
print("Confusion Matrix:")
print(cm)
# 혼동행렬 시각화 (선택사항)
sns.heatmap(cm, annot=True, cmap="Blues", cbar=False)
plt.title('Confusion Matrix')
plt.xlabel('Predicted')
plt.ylabel('True')
plt.show()
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
# 정확도 (Accuracy)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.4f}")
# classification_report
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred))Grid Search
https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.GridSearchCV.html
Grid Search는 머신러닝 모델을 학습시킬 때 하이퍼파라미터 튜닝을 위해 사용되는 일반적인 방법 중 하나로 모델에 가장 적합한 하이퍼파라미터 찾기
Grid Search는 가능한 모든 하이퍼파라미터 조합을 조사하는 방법
- Grid Search의 동작 단계
- 하이퍼파라미터 그리드 정의: 사용할 하이퍼파라미터들과 그에 대한 가능한 값들을 미리 정의
- 그리드 생성: 정의한 하이퍼파라미터들의 가능한 조합들로 그리드를 생성
- 학습 및 평가: 생성된 그리드의 각 조합에 대해 모델을 학습하고, 검증 데이터를 사용하여 모델의 성능을 평가, 교차 검증을 사용하여 더욱 신뢰성 있는 결과를 얻을 수 있음
- 최적의 하이퍼파라미터 선택: 학습 및 평가를 마친 후, 가장 성능이 좋은 하이퍼파라미터 조합을 선택
- 모델 재학습: 최적의 하이퍼파라미터 조합을 사용하여 전체 학습 데이터로 모델을 다시 학습
교차 검증
고정된 테스트 데이터로 인해 머신러닝의 성능이 오히려 떨어지는 것을 개선하기 위해 사용하는 방법으로 훈련 데이터의 일부를 여러 번 떼어 내어 모델을 검증하는데, k-fold 교차 검증에서 K등분하여 1/k을 검증 데이터로 나머지를 학습데이터로 사용하여 K번 반복한다.
from sklearn.model_selection import GridSearchCV
param_grid = {'C': [0.1, 1, 10],
'kernel':['linear', 'poly', 'rbf', 'sigmoid'],
'gamma':['scale', 'auto', 0.1, 1]
}
#교차검증
from sklearn.model_selection import RepeatedStratifiedKFold
cv = RepeatedStratifiedKFold(n_splits =10,
n_repeats=3,
random_state = 1 )
grid_search = GridSearchCV(estimator=svm_model,
param_grid =param_grid,
cv = cv,
n_jobs = -1)
grid_result = grid_search.fit(X_train, y_train)
best_params = grid_result.best_params_
best_score = grid_result.best_score_
print(f"Best: {best_score} using {best_params}" )
#최상의 파라미터로 재학습
svm_model = SVC(**best_params)
svm_model.fit(X_train, y_train)
#예측
predictions=svm_model.predict(X_test)
# 혼동행렬 출력
cm = confusion_matrix(y_test, predictions)
print("Confusion Matrix:")
print(cm)
#분류평가 레포트 출력
print(classification_report(y_test, predictions))
#
#report
precision recall f1-score support
Insomnia 0.80 0.94 0.86 17
None 0.99 0.97 0.98 71
Sleep Apnea 0.94 0.85 0.89 20
accuracy 0.94 108
macro avg 0.91 0.92 0.91 108
weighted avg 0.95 0.94 0.95 108
RandomForest 성능 개선
# RF 학습
from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier()
rfc.fit(X_train, y_train)
#예측
y_pred = rfc.predict(X_test)
#분류평가 레포트 출력
print(classification_report(y_test, y_pred))
# feature_importances_ 출력
rfc.feature_importances_
#feature_importances_ 를 시리즈로 출력 (인덱스는 칼럼명)
f_i = pd.Series(rfc.feature_importances_, index=X.columns)
f_i_s = f_i.sort_values(ascending=False)
# 성능 개선
param_grid = {
'n_estimators': [50, 100, 150], # 트리의 개수
'max_depth': [None, 10, 20, 30], # 트리의 최대 깊이 (None은 무한대를 의미)
'min_samples_split': [2, 5, 10], # 노드를 분할하기 위한 최소 샘플 수
'min_samples_leaf': [1, 2, 4] # 리프 노드가 되기 위한 최소 샘플 수
}
#교차검증
from sklearn.model_selection import RepeatedStratifiedKFold
cv = RepeatedStratifiedKFold(n_splits =10,
n_repeats=3,
random_state = 1 )
grid_search = GridSearchCV(estimator=svm_model,
param_grid =param_grid,
cv = cv,
n_jobs = -1)
grid_result = grid_search.fit(X_train, y_train)
best_params = grid_result.best_params_
best_score = grid_result.best_score_
print(f"Best: {best_score} using {best_params}" )
rfc = RandomForestClassifier(** best_params)
rfc.fit(X_train, y_train)
#예측
y_pred = rfc.predict(X_test)
#분류평가 레포트 출력
print(classification_report(y_test, y_pred))
#
# report
precision recall f1-score support
Insomnia 0.83 0.88 0.86 17
None 0.95 0.97 0.96 71
Sleep Apnea 0.94 0.80 0.86 20
accuracy 0.93 108
macro avg 0.91 0.88 0.89 108
weighted avg 0.93 0.93 0.93 108오류 처리 사항
- dataframe을 하나 더 생성하고 sklearn LabelEncoder를 적용했는데 원본 dataframe의 데이터까지 변경됨 → 메모리 주소 문제
기존 방법
df_e = df
df_e[ob_cols] = df_e[ob_cols].apply(le.fit_transform)
df.info()
df_e.info()
→ 두 데이터프레임의 object 값이 모두 변경됨
: 두 변수가 동일 메모리에 있는 데이터프레임에 접근해서 그럼
수정 방법
df_e = df
df_e[ob_cols] = df_e[ob_cols].apply(le.fit_transform)
df.info()
df_e.info()
→ 의도대로 수정됨
