교육 정보
- 교육 명: 경기미래기술학교 AI 교육
- 교육 기간: 2023.05.08 ~ 2023.10.31
- 강사: 양정은 강사님
- 강의 계획:
1. 딥러닝 소개 및 프레임워크 설치
2. Artificial Neurons Multilayer Perceptrons
3. 미분 기초 Backpropagation
4. MLP 구현하기
5. MLP로 MNIST 학습시키기(Mini-project)
6. Sobel Filtering
7. Convolutional Layers
8. 이미지 분류를 위한 CNNs
9. CNN으로 MNIST 학습시키기
10. VGGNet, ResNet, GoogLeNet
11. Image Classification 미니 프로젝트
12. Object Detection 소개
13. Region Proposal, Selective Search
14. RCNN
15. Single Shot Detection
CNN (Convolutional neural network)
CNN이란
- 특정 패턴을 추출하여 데이터를 분석하는, 특히 범주형 데이터를 분류하는데 사용되는 인공 신경망
- 지금까지 배운 fully connected layer에 convolution laye를 더한 것
- 이미지, 영상, 오디오 등에 많이 사용
CNN의 구조
-
(
Convolutional layer+Pooling layer) * N +Full connected layer→ 위에서
Convolutional layer+Pooling layer단계를 Feature extract 단계,Full connected layer단계를 Classifier 단계라 부름
- Convolutional layer: Filter가 데이터의 window를 돌면서 패턴을 추출하는 layer
- Pooling layer: 데이터(이미지)의 사이즈를 줄여주는 layer (연산량 감소가 가장 큰 목적)
CNN 모델 구현 및 결과 검토
- 모델 구현
class LeNet5(nn.Module):
def __init__(self):
super(LeNet5, self).__init__()
# ===== LY1
self.cv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, padding=2)
self.cv1_act = nn.Tanh()
# ===== LY2
self.cv1_pool = nn.AvgPool2d(kernel_size=2, stride=2)
# ===== LY3
self.cv2 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5)
self.cv2_act = nn.Tanh()
# ===== LY4
self.cv2_pool = nn.AvgPool2d(kernel_size=2, stride=2)
# ===== LY5
self.cv3 = nn.Conv2d(in_channels=16, out_channels=120, kernel_size=5)
self.cv3_act = nn.Tanh()
# ===== LY6
self.fc1 = nn.Linear(in_features=120, out_features=84)
self.fc1_act = nn.Tanh()
# ===== LY7
self.fc2 = nn.Linear(in_features=84, out_features=10)
def forward(self, x):
x = self.cv1(x)
x = self.cv1_act(x)
x = self.cv1_pool(x)
x = self.cv2(x)
x = self.cv2_act(x)
x = self.cv2_pool(x)
x = self.cv3(x)
x = self.cv3_act(x)
x = x.view(x.shape[0], -1)
x = self.fc1(x)
x = self.fc1_act(x)
x = self.fc2(x)
return x✏️ 배운 점
- Convolutional layer + activation layer+ pooling layer 가 한 세트라고 생각하면 될 듯
- 각 레이어 간의 in out shape를 고려
- shape 조정시 기본 shape를 고려하여 유지보수에 유리한 방향으로
- Conv2d output: (batch size, channel, hight, width)
- linear의 input: (batch size, n_features)
- Multiclass classification → softmax 함수 사용 이지만 본 코드에서는 loss 함수에서 softmax 함수의 역할을 대신 수행해 줄 것이므로 생략
-
결과 검토
-
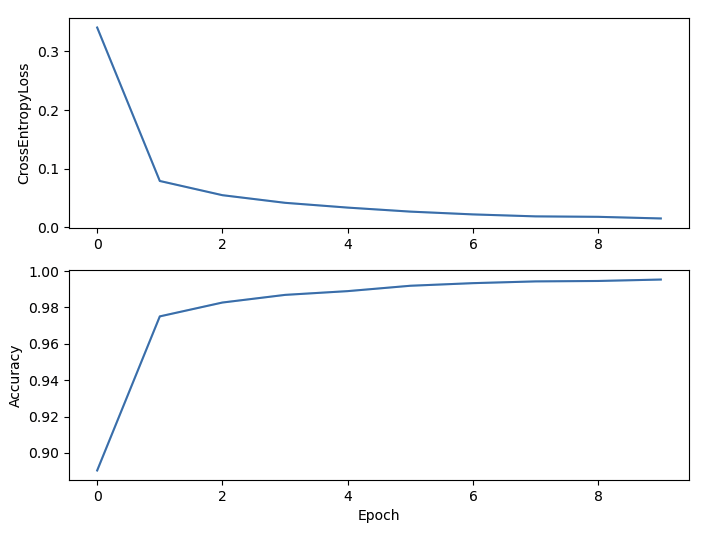
ReLU 사용
- EPOCH:10, Loss:0.0151, Acc:0.9953 LR = 0.1
-
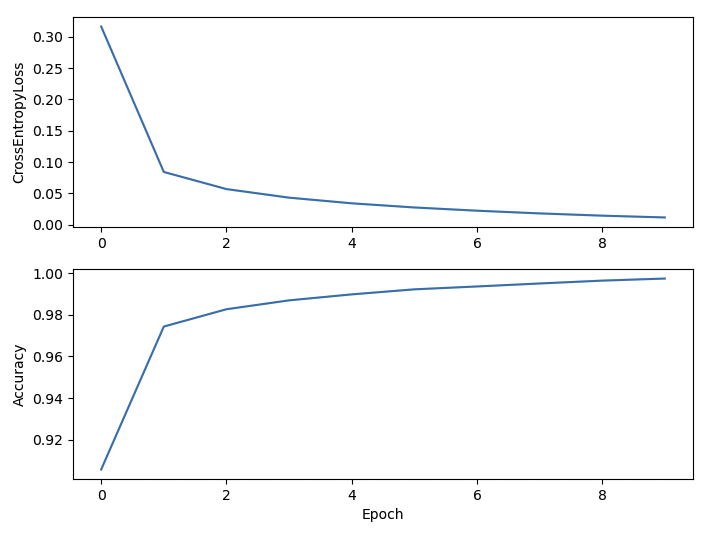
Tanh 사용
- EPOCH:10, Loss:0.0116, Acc:0.9974
-
→ Activation Function으로 Tanh을 사용한 경우가 조금더 acc 가 높지만 두 경우 모두 학습이 잘 이루어짐
→ 두 경우 모두 LR을 0.1로 준것이고 LR을 0.01로 주면 학습 속도가 약간 느려짐

:D