1. JVM과 자바 코드
1.1 JVM이란 무엇인가
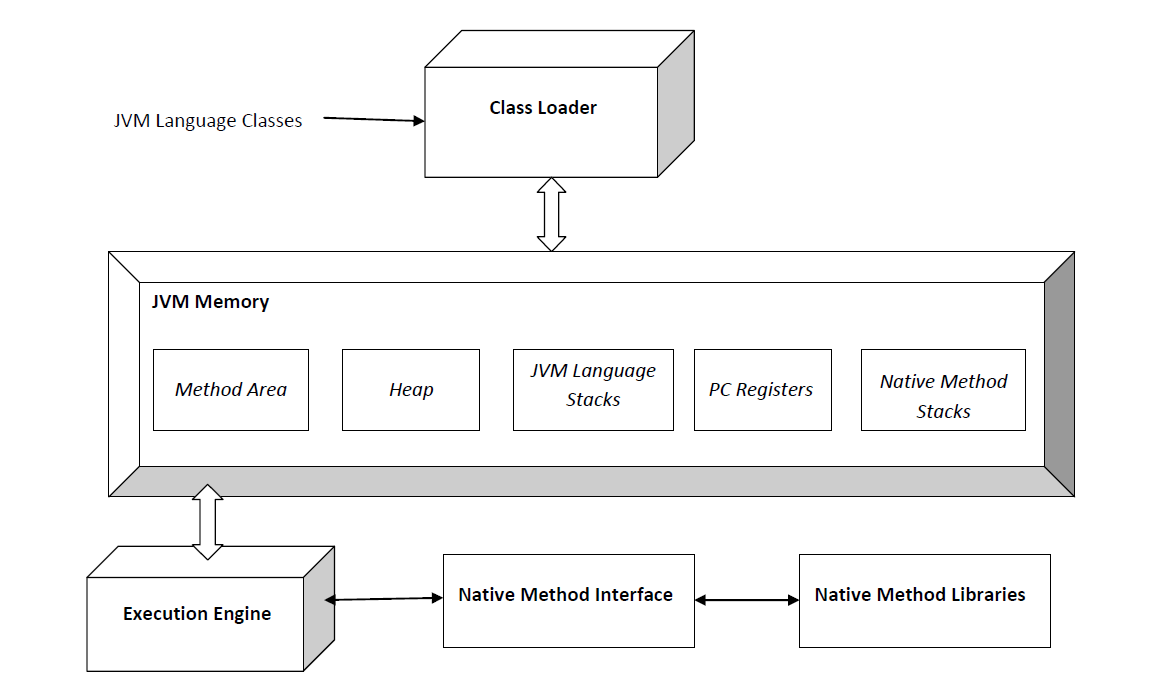
자바 프로그램은 완전한 기계어가 아닌, 중간 단계의 바이트 코드이기 때문에 이것을 해석하고 실행할 수 있는 가상의 운영체제가 필요하고 이것이
활용JVM (Java Virual Machine)이다. 다시 말해 JVM이란, 가상의 운영체제로써 "자바를 실행시키는 가상의 기계"라고 생각하면 된다. JVM은 바이트 코드로 컴파일된 자바 파일을 운영체제에 상관없이 실행시킬 수 있도록 하지만 이를 위해선 JVM 자체는 각 운영체제에 종속적이다.
1.2 컴파일 하는 방법
자바 프로그램을 실행시키기 위해선 JVM에서 기계어로 번역하기 위한 바이트 코드를 만들어야 하고 이는 컴파일을 통해 진행되고 절차는 아래와 같다.
- 확장자가 .java인 파일 작성(소스 파일)
- javac.exe로 소스 파일 컴파일
- 확장자가 .class인 바이트 코드 파일 생성
1.3 실행하는 방법
앞에서 생성된 확장자가 .class인 바이트코드 파일은 JVM 구동 명령어(java.exe)에 의해 JVM에서 해석되고 해당 운영체제에 맞게 기계어로 번역된다. 즉, 바이트코드는 하나지만 기계어는 운영 체제에 따라서 달라진다.
1.4 바이트코드란 무엇인가
자바 바이트코드(Java bytecode)는 JVM이 이해(해석)할 수 있는 언어로 변환된 자바 소스 코드를 의미하고 자바 컴파일러에 의해 변환되는 코드의 명령어 크기가 1 바이트 이기 때문에 바이트코드라고 불린다. 바이트코드의 확장자는 .class 이고 JVM만 있으면 어떤 운영체제에서라고 실행될 수 있다.
1.5 JIT 컴파일러와 동작
한 번 작성하면 어디서든 실행된다는 자바의 큰 장점이 있지만 한 번의 컴파일링으로 바로 실행가능한 기계어가 만들어지지 않아 C 나 C++ 대비 느린 실행 속도가 단점이었다. 그리고 이를 보완하기 위해 JVM 내부의 최적화된 JIT (Just In Time) 컴파일러를 통해 바이트코드를 기계어로 빠르게 변환해주며 속도차를 줄일 수 있게 되었다.
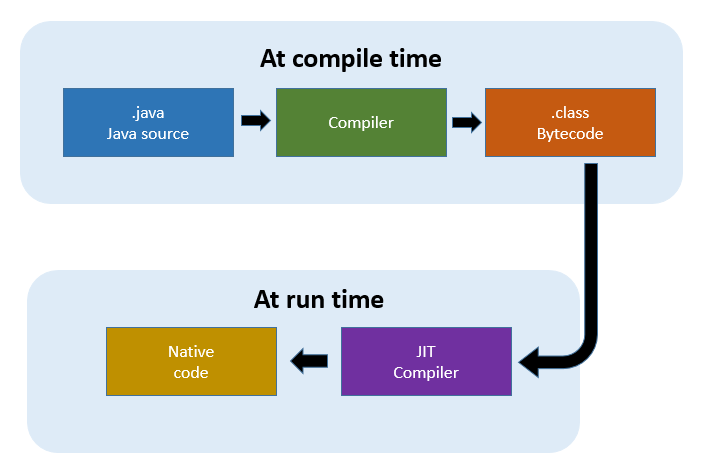
여기서 다시 한 번 짚고 넘어가야하는 부분이 있다. 자바는 바이트코드로 컴파일을 하고 이 바이트코드를 다시 해석(인터프리터)하여 기계어로 변환하는 방식으로 실행된다.
- 컴파일 방식 : 소스코드를 한꺼번에 변환
- 인터프리터 방식 : 런타임에 한줄 한줄 읽어가며 변환
이때 인터프리터 방식은 컴파일 방식에 비해 오랜 시간이 들어가는 단점이 있다. 그래서 JIT 컴파일러는 인터프리터 방식의 단점을 해결하기 위해 런타임에 중복 실행 될 부분은 인터프리팅하지 않고 바이트코드를 컴파일하면서 변한된 기계어를 캐슁한다. 메소드가 컴파일되면 호출 할 때 마다 JVM이 인터프리트하는 대신 해당 메소드의 컴파일된 코드를 하드웨어가 직접 호출하는 방식으로 인터프리터의 단점을 해결한다.
1.6 JVM 구성 요소
JVM은 다음 크게 다음과 같이 구성된다.
1. 클래스 로더
2. 런타임 데이터 영역
3. 실행 엔진
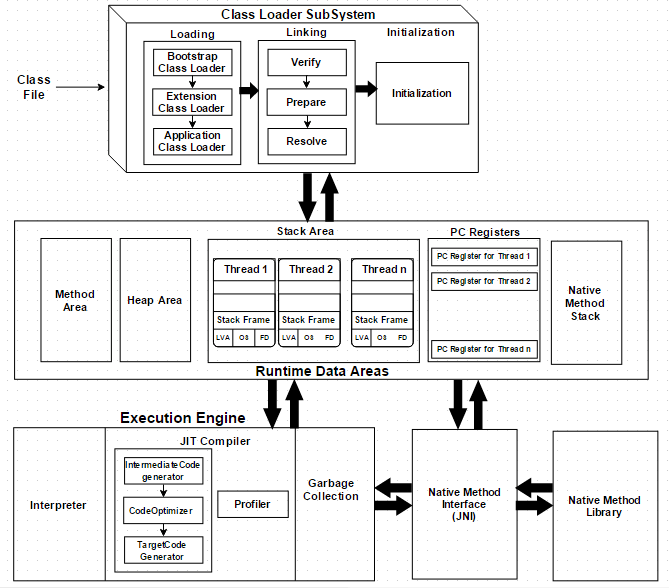
1.6.1 클래스 로더 (Class loader)
말 그대로 JVM에 클래스 파일을 런타임에 메모리에 로드하는 역할을 한다. 다른 작업들이 수행되기 위해 파일을 로드하는 작업을 하기 때문에 JVM의 구조 설계상 가장 첫 번째 요소이다. 그리고 클래스 로더는 세부적으로 로딩, 링킹, 초기화의 세 단계를 거친다.
로딩 (Loading)
클래스 파일을 바이트 코드로 읽어 메모리로 가져오는 과정이며 세가지의 ClassLoader가 있다.
- BootStrap ClassLoader: rt.jar 외에는 부트스트랩 클래스 경로에서 클래스를 로드하는 역할을 하며 로더 중 가장 높은 우선 순위
- Extension ClassLoader: ext폴더(jre\lib)에 있는 클래스를 로드
- Application ClassLoader: Application Level Classpath, 경로가 언급된 환경 변수 등을 로드
링킹 (Linking)
로딩 이후의 과정은 링킹으로 세 단계로 구성되어 있다.
- Verify: 바이트 코드 검증기는 생성 된 바이트 코드가 적절한 지 여부를 확인합니다. 검증이 실패하면 검증 오류가 발생한다.
- Prepare: 모든 정적 변수에 대해 메모리가 할당되고 기본값으로 할당된다.
- Resolve: 모든 심볼릭 메모리 참조가 메서드 영역의 원래 참조로 대체된다.
초기화 (Initilization)
ClassLoading의 마지막 단계이며 모든 정적 변수는 원래 값으로 할당되고 정적 블록이 실행된다.
1.6.2 런타임 데이터 영역(Runtime Data Area)
런타임 데이터 영역은 Method Area, Heap Area, Stack Area, PC Registers 그리고 Native Method Stacks로 5 개로 나눌 수 있다.
Method Area
- 정적 변수를 포함하여 모든 클래스 수준의 데이터가 저장
- JVM당 1개
- 메모리를 공유하기 때문에 저장된 데이터가 스레드에 안전하지 않다
Heap Area
- 모든 객체와 해당 인스턴스 변수 및 배열들이 저장
- JVM당 1개
- 메모리를 공유하기 때문에 저장된 데이터가 스레드에 안전하지 않다
Stack Area
- 모든 스레드에 대해 별도의 런타임 스택이 생성
- 모든 메서드 호출에 대해 스택 메모리에 Stack Frame 항목 신규 생성
- 모든 지역 변수는 스택 메모리에 생성
- 공유 리소스가 아니기 때문에 스레드에 안전
- Stack Frame은 3가지 하위 항목으로 나뉨
- Local Variable Array: 메소드와 관련있는 로컬 변수 개수 및 해당 값들이 저장
- Operand Stack: 중간에 연산을 수행해야 할 때 연산을 위해 런타임 작업영역을 수행
- Frame Data: 메소드에 해당하는 모든 심볼이 저장되고 예외가 발생하면 Catch 블록의 정보가 유지
PC Registers
각 스레드에는 별도의 PC Register가 있으며, 실행 중인 명령이 완료되면 PC Register가 다음 명령을 업데이트 시킨다.
Native Method Stacks
이름 그대로 native method들이 저장되는 영역이며 스레드마다 별도로 존재한다.
1.6.3 실행 엔진 (Execution Engine)
마지막으로 실행 엔진은 런타임 데이터 영역에 할당 된 바이트 코드를 읽어들이고 조각별로 실행한다.
- Interpreter: 바이트 코드를 빠르게 해석하지만 실행이 느린 단점이 있다. 그리고 하나의 메서드가 호출 될 때마다 매번 새로 해석하는 문제가 있다.
- JIT Compiler: 인터프리터의 단점을 해결하기 위해 인터프리터가 반복되는 코드를 발견하면 JIT Compiler를 활용해 기계어로 변경하고 반복되는 메서드 호출 시 새로 해석하는 것이 아니라 시스템이 직접 이 코드를 호출하는 것으로 반복 문제를 해결한다.
- Garbage Collector: 참조되지 않는 객체를 자동으로 수집하고 제거한다. System.gc()를 호출하는 것으로 GC를 실행시킬 수 있지만 보장되진 않는다.
위와는 별도로 실행엔진은 JVM에 있는 JNI(Java Native Interface)와 Native Method Libraries를 활용해 프로그램을 실행한다.
1.7 JDK와 JRE의 차이
1.7.1 JDk (Java Development Kit)
- 자바 프로그램을 개발 할 때 사용
- JRE, 컴파일러, 인터프리터 등을 포함한 개발 환경 제공
1.7.2 JRE (Java Runtime Envrionemt)
- JRE는 자바 프로그램 실행 환경을 빌드
- 프로그램 실행을 위한 SW와 라이브러리를 가지고 있다
- 자바 코드를 사용되는 라이브러리와 연결해준다.
- JVM 실행을 시작시킨다
