1. 카프카 기초 개념
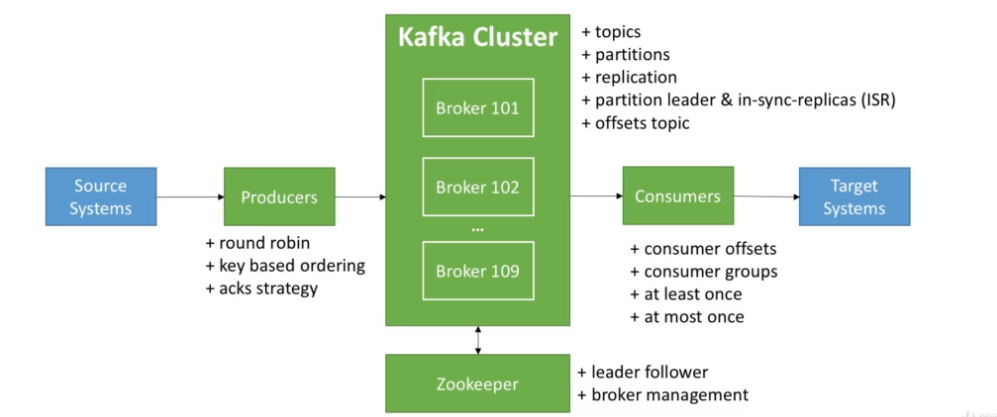
카프카를 다루는 포스팅을 이어나가기 전에 카프카 관련 기초 개념을 숙지한 상태에서 진행할 필요가 있기에 카프카를 이루는 구성 요소 및 운영 환경에 대한 개념들을 정리하였다.
1.1 Topics, Partitions and Offsets
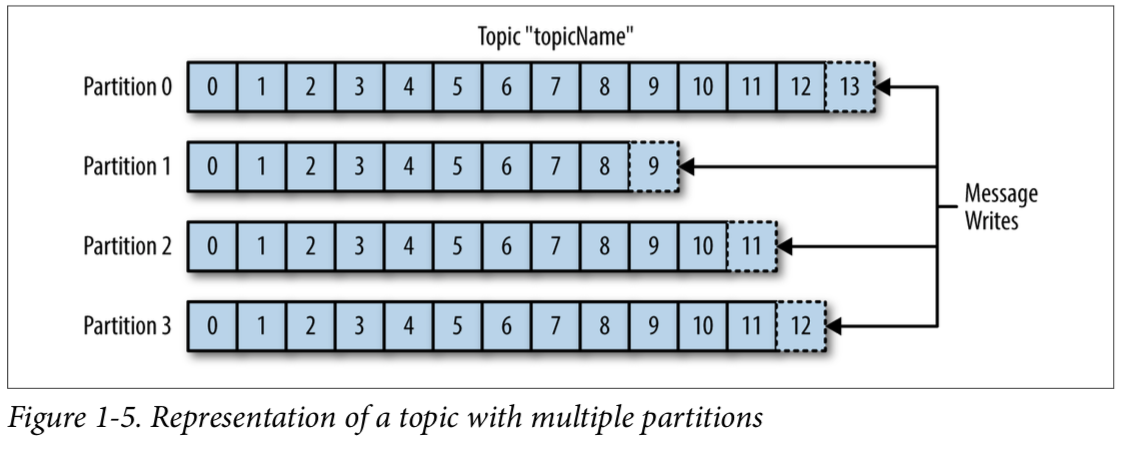
1.1.1 Topics
Topic은 kafka에서 특정한 데이터 스트림을 의미한다.
- 기존 데이터베이스의 테이블과 유사
- 토픽의 개수는 원하는 만큼 생성 가능
- 토픽은 이름에 의해 구분된다
- Topic은 1개 이상의 Partition으로 나뉜다(개수 명시 필요)
1.1.2 Partitions
각 Partition은 서로 독립적
- 토픽을 구성하는 파티션은 정렬되어있다
- 데이터는 유한한 시간 동안 저장(기본적으로 일주일)
- 파티션에 한 번 쓰여진 데이터는 변경 불가하다
- 데이터는 키 값이 제공되지 않으면 파티션에 랜덤하게 할당된다.
- 각 파티션 속 메세지는 오름차순의 id 값인 Offset을 가지고 있다
1.1.3 Offsets
각 Offset은 속해 있는 파티션에서만 의미있는 값이다
- Offset 값이 파티션마다 다를 수 있다
- 순서는 속해 있는 파티션에서만 보장된다
- 다른 파티션에서 동일한 Offset이 가리키는 데이터는 같지 않다
1.2 Brokers and Topics
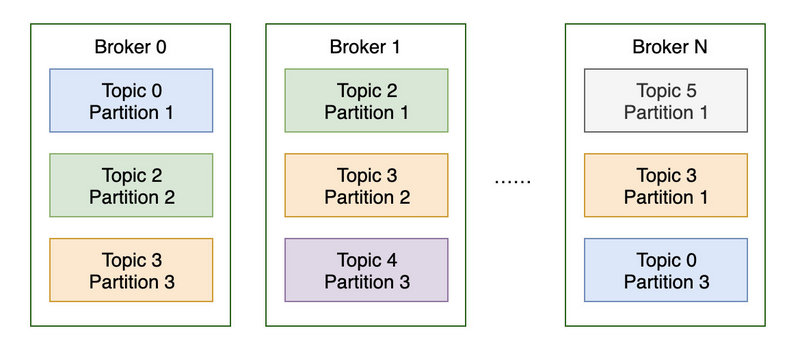
- 카프카 클러스터는 1개 이상의 브로커(서버)로 구성된다.
- 각 브로커는 정수형 ID 값으로 구분
- 각 브로커는 특정한 토픽의 파티션을 보유
- 브로커끼리 연결하면 클러스터가 된다
- 브로커는 3개 이상을 가지는 것이 좋다(장애 허용 관점)
- 토픽을 생성하면 카프카가 자동적으로 파티션들을 브로커에 분배
1.3 Topic Replication
위와 같이 토픽의 정보를 브로커에 분산 처리하게 될 때 하나의 브로커에 장애가 발생해도 시스템이 정상적으로 운영되게 하기 위해 다른 브로커에 레플리케이션(복사본)을 만들어두는 것이 안정적이다. 아래는 레플리케이션이 3개인 토픽이 브로커가 3개인 클러스터에 각 파티션이 분산되어 있는 예시이다.
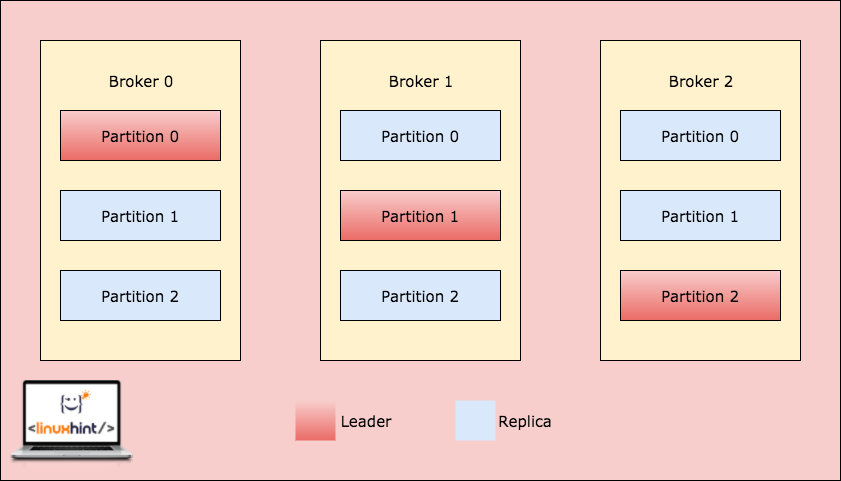
- 토픽은 replication의 개수가 1개 보다 커야 좋다(보통 3개)
- 브로커가 다운되면 다른 브로커가 데이터를 처리해준다
1.3.1 Leader & Replica
레플리케이션 정책에서 오직 하나의 브로커만이 주어진 파티션 복사본들의 리더가 될 수 있다. 그리고 오직 이 리더 하나만 데이터를 받고 처리하는 파티션이 된다.
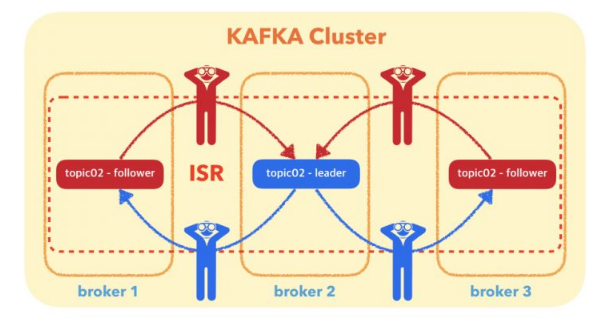
- 다른 브로커들은 데이터를 동기화한다
- 각 파티션은 하나의 리더와 다수의 ISR(In-Sync Replica)이 있다
1.4 Producers & Consumers
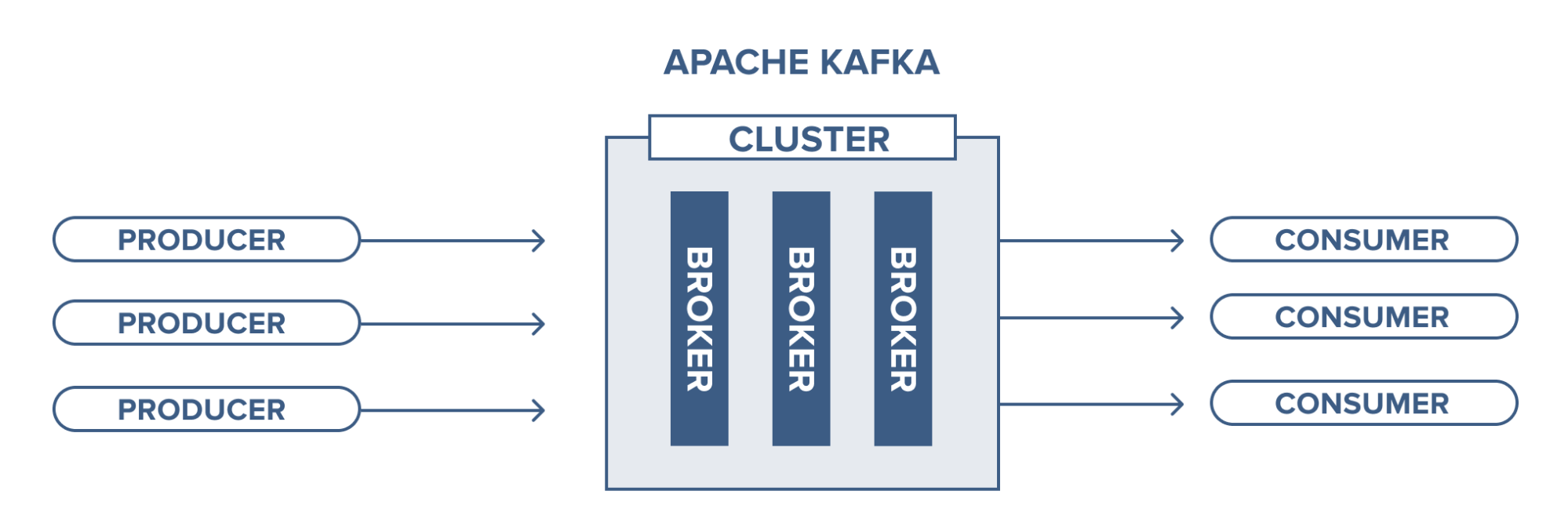
1.4.1 Producers
기본적으로 카프카에서 프로듀서는 토픽에 데이터를 쓰는 개체이다.
- 어떤 브로커의 파티션에 저장해야는지 자동으로 저장 위치를 안다
- 브로커에 장애 발생시 프로듀서는 자동적으로 회복이 된다
- 다수의 브로커와 파티션으로 인해 기본적으로 로드 밸런싱이 되어 있다.
- 데이터 저장 성공 여부를 acks 를 통해 확인할 수 있다
acks 를 통한 저장 여부 확인

- acks=0 : 저장 확인 여부 기다리지 않음(데이터 손실 가능)
- acks=1 : 리더의 저장 확인 여부만 기다림(제한된 데이터 손실)
- acks=all: 리더와 레플리카들의 확인 여부 기다림(데이터 손실 없음)
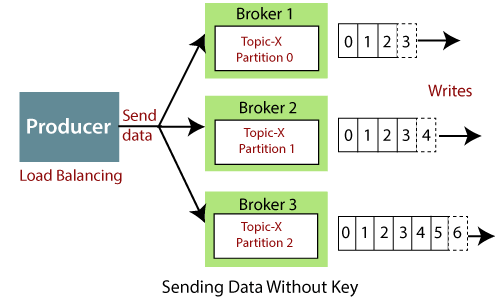
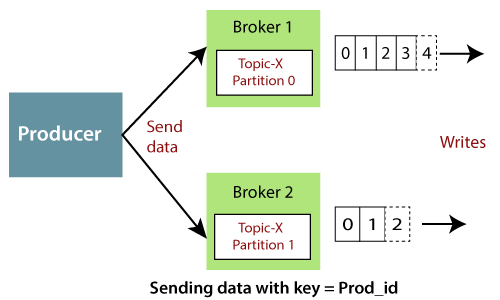
Key 를 포함한 메세지
프로듀서는 메세지에 문자열이나 숫자 등의 키 값을 포함해서 메세지를 보낼 수 있다.
- 키 값이 없으면 데이터는 라운드 로빈 방식으로 브로커에 전송(로드 밸런싱)
- 키 값이 있으면 메세지는 (키 해싱에 의한)하나의 파티션에만 지속적으로 전달
- 특정한 데이터 필드에 대한 요청이 필요하면 키를 활용
1.4.2 Consumers
컨슈머는 토픽으로부터 데이터를 읽어드린다
- 컨슈머는 어떤 브로커로부터 읽어드릴지 알고 있다
- 브로커에 장애가 발생하면 컨슈머는 회복하는 방법을 알고 있다
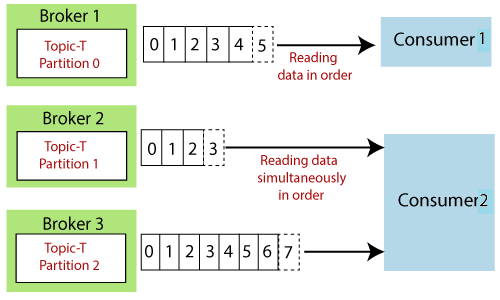
- 데이터는 각 파티션에 들어온 순서대로 읽힌다
- 읽어드리는 파티션의 순서는 정해져 있지 않고 돌아가면서 병렬처리 된다.(파티션 순서에 대한 보장 없음)
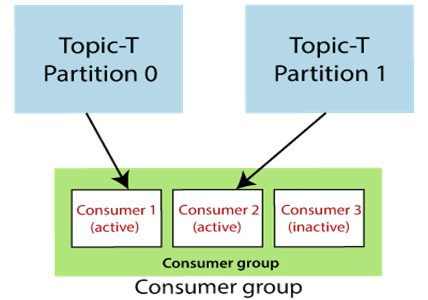
A. Consumer Group
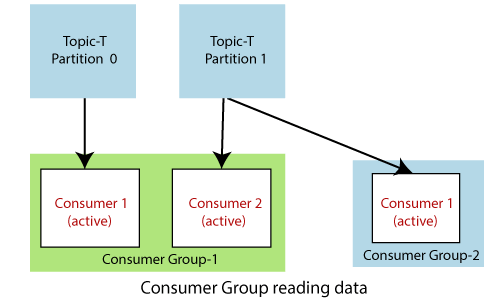 컨슈머 그룹은 개별 컨슈머들을 하나로 묶은 논리적 그룹 단위이다.
컨슈머 그룹은 개별 컨슈머들을 하나로 묶은 논리적 그룹 단위이다.
- 그룹 내 특정 컨슈머에 장애가 생겨도 다른 컨슈머들이 데이터를 읽을 수 있다
- 컨슈머 그룹내 컨슈머가 파티션 숫자보다 많으면 비활성화되는 컨슈머가 발생
- 컨슈머와 파티션의 개수를 잘 조절해야 한다
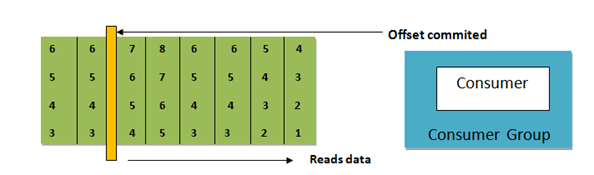
B. Consumer Offsets
- 컨슈머 그룹 단위로도 데이터를 읽은 위치 정보인 오프셋이 관리된다
- 읽어드린 위치를 기록하는 오프셋은 __consumer_offsets로 관리, 토픽에 저장
- 데이터를 읽어드린 순간 오프셋이 기록된다
- 컨슈머가 중지되면 오프셋에 저장된 위치에서부터 다시 데이터를 읽어드린다
C. Delivery semantics
오프셋이 기록 시점 관련 정책에는 3가지가 있다
- At most once(비선호)
- 컨슈머가 메세지를 받는 순간 기록
- 처리가 잘못되어도 메세지는 이미 삭제되어 있다(데이터 손실)
- At least once(선호)
- 메세지를 받은 컨슈머가 데이터를 처리하는 순간 기록
- 프로세스가 잘못되면 메세지를 다시 읽어드린다
- 데이터 중복 처리가 발생해도 시스템에 문제가 없는 프로세스에만 적용
- Exactly once
- 카프카 생태계(카프카->카프카)에서 가능(Kafka Stream API 등)
- 외부 시스템과의 연결을 할 때는 연산을 여러번해도 결과가 달라지지 않는 컨슈머만 가능(멱등 시스템)
1.5 Broker Discovery & Zookeeper
1.5.1 Kafka Broker Discovery
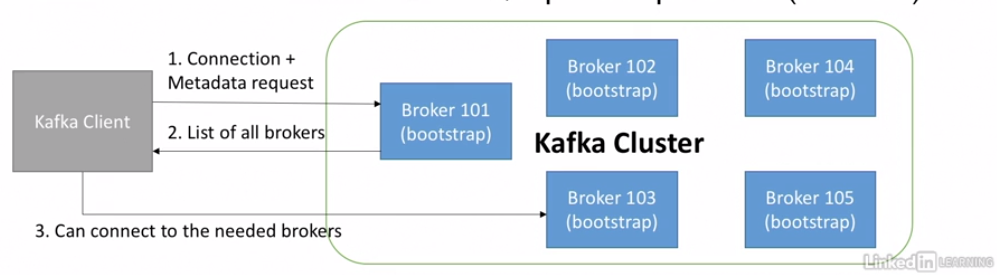
모든 카프카 브로커는 "부트스트랩 서버"라 불리운다.
- 다른 브로커 하나와만 연결해도 전체 클러스터에 연결
- 각각의 브로커는 전체 브로커와 토픽들 그리고 파티션들에 대한 정보(메타데이터)를 알고 있다
1.5.2 Zookeeper
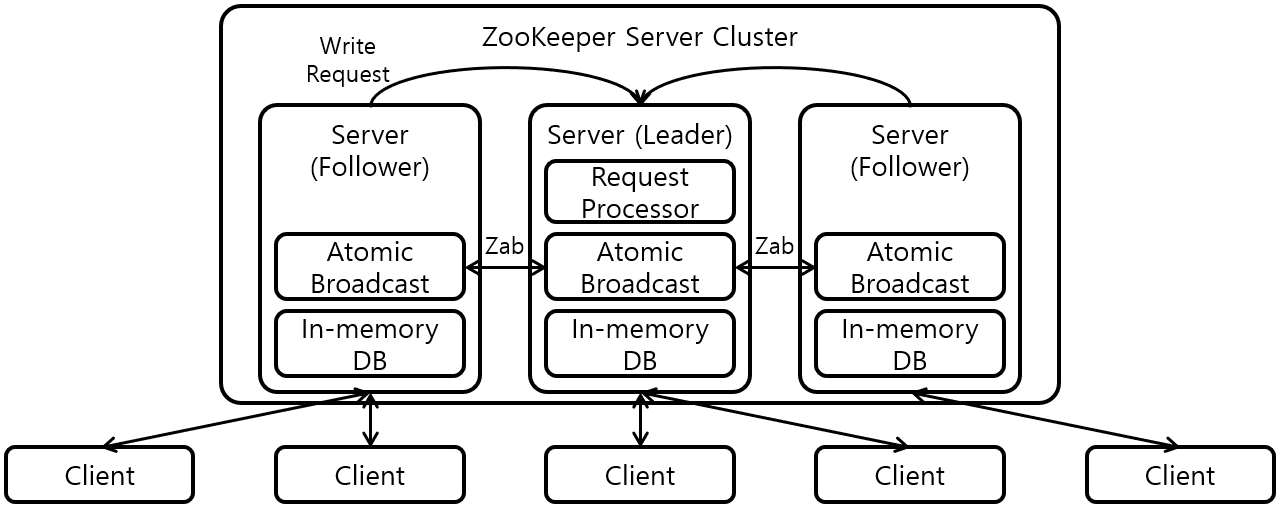
주키퍼는 카프카 클러스터 내의 브로커들의 리스트를 가지고 있으며 브로커들을 관리하며 카프카는 주키퍼 없이 실행할 수 없다.
- 리더 파티션에 장애가 발생시 주키퍼를 통해 새로운 리더 파티션을 선발
- 새로운 토픽 추가, 브로커 장애 및 토픽 삭제 등의 변경 정보를 카프카에 전달한다
- 주키퍼는 홀수 개의 서버를 가지고 있어야 한다(3,5,7)
- 주키퍼는 쓰기를 관장하는 리더 서버 1개와 읽기를 관장하는 나머지 팔로워 서버로 구성된다

Arch-ITech