예제 실습3 - 단순 선형 회귀 모델
아이스크림 판매량 예측
온도가 올라가면 아이스크림 판매량이 증가?
내가 한 풀이
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score, mean_squared_error
# 시각화 한글 깨짐 방지 설정
plt.rcParams['font.family'] ='Malgun Gothic'
plt.rcParams["axes.unicode_minus"] = False
data = {
'temperature' : [5,7,10,14,18,20,22,25,28,30],
'sales' : [20,23,30,38,50,60,65,80,90,100]
}
df = pd.DataFrame(data)
# 1. X, y 정의
# 온도 x 세일즈 y 가 된다.
X = df[['temperature']] # (n, 1), 2차원 형태로 여러개 독립변수일수도 있기에 df형태
y = df['sales'] # 종속변수 y 추출
# X = df.drop('sales', axis=0) # X가 많은 경우에 사용될 수 있음, x 독립변수 많을때 x1,x2,x3, y이렇게 있다면 sales 삭제
# 원래는 데이터 분할을 해야됩니다! train_test_split으로 훈련 셋/테스트 셋으로 분할 해야함
# 2. 모델 생성 및 학습
model = LinearRegression() # 단순 선형 회귀 모델 생성
model.fit(X, y) # 모델 훈련 -> 파라미터 값(절편과 기울기를 구할 수 있다)
# 3. 회귀 계수/절편 확인
print(f'기울기(coef): {model.coef_[0]:.3f}')# 기울기(coefficient)그중 첫번째 인덱스 소수점
print(f'절편(intercept): {model.intercept_:.3f}') # 절편(intercept)
# 4. 전체 예측
# 원래는 여기서 X_teest 예측해야 되는데, 훈련 데이터로 예측 그대로 진행
pred = model.predict(X) # 예측 수행 호, 결과 받기
# 5. 새로운 값 예측
# 기온이 27도일 때의 아잉스크림 판매량은? 무엇일까?
new_temperature = np.array([[27]]) # 2차원 형태로
new_pred = model.predict(new_temperature) # 새로운 테스트 데이터에 대해 예측
# new_pred에 예측 값이 담겨있다
print(f'온도가 27도일 때 예상 판매량:{new_pred[0]:.2f}개')# 인덱싱하기 여기선 독립변수가 하나기에 0번째라고 함 만약 리스트 형태로 꺼낼려면 []없애고, :.2f없애면 됨
# 6. 시각화
# 데이터 산점도 X축: 온도, Y축: 판매량
plt.scatter(df['temperature'] ,df['sales'], color='blue', label='실제 값')
# 회귀선을 선 그래프로 그리기 X축: 온도, Y축: 판매량(예측으로 구한)
plt.plot(df['temperature'], pred, color='red', label='회귀선')
plt.xlabel('기온')
plt.ylabel('판매량(개)')
plt.title('아이스크림 판매 예측')
plt.legend()
plt.grid(alpha=0.3)
plt.show()
# y = 3.208x + (-1.819)
# 7. 결과 확인: R ^2 score, MSE, RMSE
# 평가는 실제 y_test랑 예측 y_pred랑 비교
print(f'R^2: {r2_score(y, pred)}') # 0~1 사이의 값: 1에 가까울수록 좋은 모델
print(f'MSE: {mean_squared_error(y,pred)}') # MSE; 평균 오차 제곱합
print(f'RMSE: {np.sqrt(mean_squared_error(y, pred))}') # RMSE; MSE의 제곱근(루트)기울기(coef): 3.208
절편(intercept): -1.819
온도가 27도일 때 예상 판매량:84.79개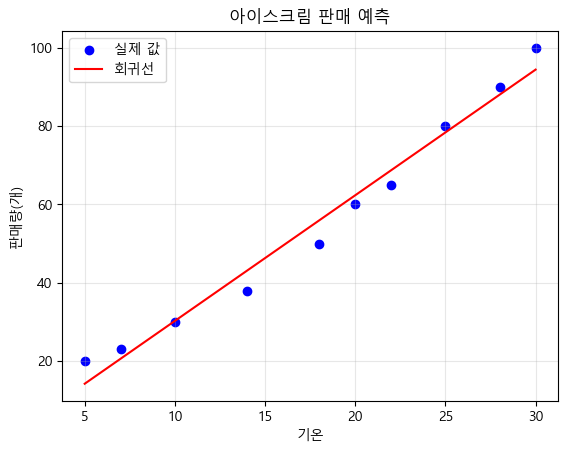
R^2: 0.9780893943026799
MSE: 15.741455557182599
RMSE: 3.9675503219471078단순 선형회귀 - 공부시간과 시험점수
한 학생의 일일 공부시간과 시험점수 간의 관계를 분석하려고 합니다. 공부시간이 시험점수에 어떤 영향을 미치는지 예측 모델을 만들어보세요.
공부시간(시간) | 시험점수(점)
1 | 55
2 | 60
3 | 65
4 | 70
5 | 75
6 | 80
7 | 85
8 | 90- 위 학습 데이터로 모델을 학습시키세요.
- 공부시간이 9시간일 때 예상 점수를 예측하세요.
- 산점도와 회귀선(Regression Line)을 그래프로 시각화하세요.
- 모델의 성능(R Squared Score)을 확인하세요.
내가 한 풀이
# 1. 라이브러리 불러오기
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score
# 시각화 한글 깨짐 방지 설정
plt.rcParams['font.family'] ='Malgun Gothic'
plt.rcParams["axes.unicode_minus"] = False
# 2. 데이터셋 정의
df = pd.DataFrame({
'study_hours' : [1, 2, 3, 4, 5, 6, 7, 8],
'test_score' : [55, 60, 65, 70, 75, 80, 85, 90]
})
# 3. 데이터 준비하기 (X, y)
X = df[['study_hours']] # 독립변수: 2차원 형태로 만드세요.
y = df['study_hours'] # 종속변수
# 4. 모델 생성 후, 학습을 진행하세요!
model = LinearRegression()
model.fit(X, y)
# 5. 모델 파라미터 출력하기 (절편, 기울기(계수))
print(f"기울기(계수): {model.coef_[0]:.2f}")
print(f"절편: {model.intercept_:.2f}")
# 6. 예측하기
# 예측용 테스트 데이터
new_study_hours = np.array([[9]]) # 2차원 형태
# 예측하기
predicted_score = model.predict(new_study_hours)
print(f'예측 점수: {predicted_score[0]}')
# 7. 성능 평가
y_pred = model.predict(X) # 데이터 X에 대해 예측하기
r2 = r2_score(y, y_pred) # R2 score
print(f'R^2 점수: {r2:.4f}')
# 8. 시각화 (산점도와 회귀선에 대한 선 그래프)
plt.figure(figsize=(10, 6))
# 산점도
plt.scatter(df['study_hours'], y_pred, color='blue', label='실제 데이터', s=100)
# 구한 회귀선을 선 그래프로
plt.plot(df['study_hours'], y_pred, color='red', linewidth=2, label='회귀선')
plt.xlabel('공부 시간 (시간)', fontsize=12)
plt.ylabel('시험 점수 (점)', fontsize=12)
plt.title('공부시간과 시험점수의 관계', fontsize=14)
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
# 9. 회귀식 출력 (y = ax + b 형태)
print(f'y = {model.coef_[0]:.2f}x + {model.intercept_:.2f}')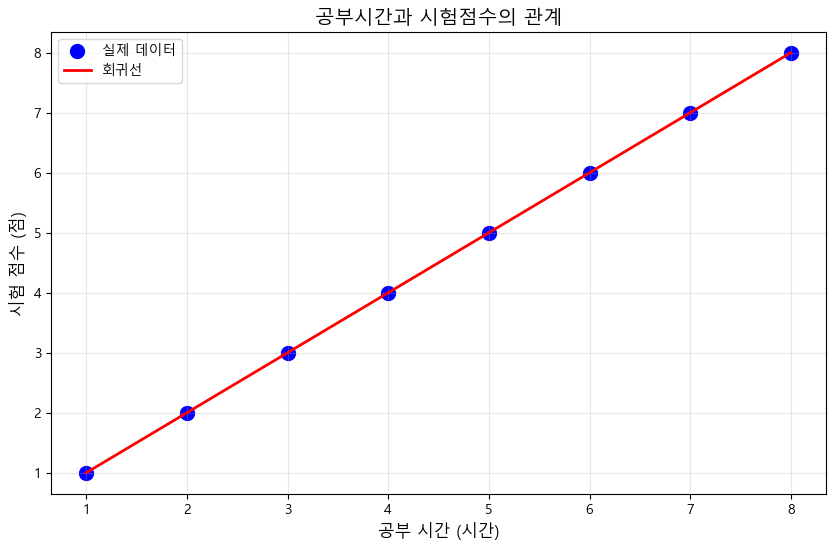
y = 1.00x + -0.00다중 선형 회귀 - 아파트 가격 예측
아파트의 면적, 방 개수, 건축연수를 바탕으로 가격을 예측하는 모델을 만들어보세요.
면적(㎡) | 방개수 | 건축연수(년) | 가격(백만원)
60 | 2 | 5 | 300
75 | 3 | 3 | 400
85 | 3 | 10 | 380
100 | 4 | 2 | 520
110 | 4 | 7 | 480
120 | 4 | 15 | 450
130 | 5 | 5 | 580
140 | 5 | 12 | 550- 위 데이터로 다중회귀 모델을 학습시키세요
- 면적 95㎡, 방 3개, 건축연수 8년인 아파트의 가격을 예측하세요
- 각 특성(면적, 방개수, 건축연수)의 회귀계수를 확인하세요
- 어떤 특성이 가격에 가장 큰 영향을 미치는지 분석하세요
- 모델의 성능(R² 점수, MSE)을 평가하세요
내가 한 풀이
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score, mean_squared_error
# 시각화 한글 깨짐 방지 설정
plt.rcParams['font.family'] ='Malgun Gothic'
plt.rcParams["axes.unicode_minus"] = False
# 1. 데이터 불러오기
data = {
"area" : [60, 75, 85, 100, 110, 120, 130, 140],
"rooms": [2, 3, 3, 4, 4, 4, 5, 5],
"age": [5, 3, 10, 2, 7, 15, 5, 12],
"price": [300, 400, 380, 520, 480, 450, 580, 550]
}
df = pd.DataFrame(data)
# 데이터 살펴보기
print(df)
# 2. 데이터 준비 X, y 데이터
X = df[['area', 'rooms', 'age']] # 독립변수(면적, 방개수, 건축연수) 3개 컬럼 추출
y = df['price'] # 종속변수 (가격)
# 3. 모델 생성 및 학습
model = LinearRegression() # 단순 선형 회귀 모델 생성
model.fit(X, y)
print(model)
# 4. 모델 파라미터(계수, 절편) 확인
for feature, coef in zip(X.columns, model.coef_):
print(f" {feature} 계수: {coef:.2f}")
print(f"절편: {model.intercept_:.2f}")
# 6. 새로운 데이터 예측
# 원하면 데이터를 추가해보세요!
new_apartment = np.array([[95, 3, 8]]) # 95㎡, 방3개, 8년일 때!?
predicted_price = model.predict(new_apartment)
print(f"예측 결과:")
print(f"면적: 95㎡, 방: 3개, 건축연수: 8년")
print(f"예상 가격: {predicted_price.flatten()[0]:.2f}")
# 7. 모델 성능 평가
y_pred = model.predict(X) # X에 대해 예측을 진행하세요.
r2 = r2_score(y, y_pred) # R^2 Score
mse = mean_squared_error(y, y_pred) # MSE
rmse = np.sqrt(mse) # RMSE
print(f"모델 성능:")
print(f"R^2 점수: {r2:.4f}")
print(f"평균 제곱 오차(MSE): {mse:.2f}")
print(f"평균 제곱근 오차(RMSE): {rmse:.2f}")
# 8. 시각화: 실제값 vs 예측값
# 실제 값과 예측 값에 대한 산점도를 그리세요!
# x축: 실제 값, y축: 예측 값
plt.scatter(df['price'], y_pred, alpha=0.7, s=100)# 예측 변수에 대한 비교
plt.plot([y.min(), y.max()], [y.min(), y.max()], 'r--', lw=2)
plt.xlabel('실제 가격 (백만원)', fontsize=12)
plt.ylabel('예측 가격 (백만원)', fontsize=12)
plt.title('실제 가격 vs 예측 가격', fontsize=14)
plt.grid(True, alpha=0.3)
plt.show() area rooms age price
0 60 2 5 300
1 75 3 3 400
2 85 3 10 380
3 100 4 2 520
4 110 4 7 480
5 120 4 15 450
6 130 5 5 580
7 140 5 12 550
LinearRegression()
area 계수: -0.81
rooms 계수: 113.63
age 계수: -3.36
절편: 139.14
예측 결과:
면적: 95㎡, 방: 3개, 건축연수: 8년
예상 가격: 376.24
모델 성능:
R^2 점수: 0.9944
평균 제곱 오차(MSE): 43.18
평균 제곱근 오차(RMSE): 6.57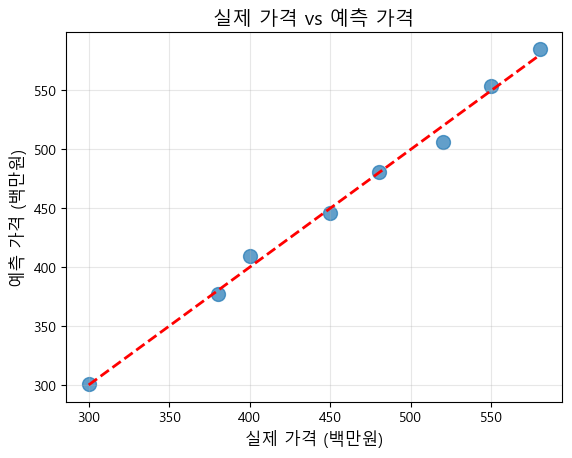
집 전기요금 예측
현대 가정에서는 전기사용량이 꾸준히 증가하면서 전기요금 관리가 중요한 이슈가 되고 있습니다.
특히 가전제품 사용량 증가, 계절 변화에 따른 냉·난방 기기 사용, 가구 형태의 다양화 등으로 인해 전기요금의 변동 폭이 커졌습니다.
가정의 전기 사용 패턴을 기반으로 전기요금을 예측하는 회귀 모델을 만들어보는 것이 목표입니다.
전력 사용량(kWh), 집에 있는 가전제품의 수, 평균 기온과 같은 변수들이 전기요금에 어떤 영향을 미치는지 분석하고,이를 통해 새로운 가정의 전기요금을 예측해보게 됩니다.
- usage_kwh: 월 전력 사용량 (kWh)
- appliance_cnt: 가전제품 수
- temperature: 평균기온(°C)
- bill: 월 전기요금(만원)
| usage_kwh | appliance_cnt | temperature | bill |
|---|---|---|---|
| 250 | 5 | 5 | 4.2 |
| 300 | 6 | 10 | 4.8 |
| 150 | 4 | 15 | 3.1 |
| 400 | 8 | 0 | 6.0 |
| 350 | 7 | 8 | 5.4 |
| 200 | 4 | 12 | 3.5 |
| 100 | 3 | 18 | 2.7 |
| 450 | 9 | -2 | 6.8 |
내가 한 풀이
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression
electric_data = {
"usage_kwh": [250,300,150,400,350,200,100,450],
"appliance_cnt": [5,6,4,8,7,4,3,9],
"temperature": [5,10,15,0,8,12,18,-2],
"bill": [4.2,4.8,3.1,6.0,5.4,3.5,2.7,6.8]
}
df_elec = pd.DataFrame(electric_data)
# 데이터를 X, y로 분리 (누가 독립변수들? 누가 종속변수?)
X = df_elec[['usage_kwh', 'appliance_cnt', 'temperature']] # 독립변수
y = df_elec['bill'] # 종속변수
# 모델 생성 및 학습
model = LinearRegression()
model.fit(X, y)
# 회귀 계수와 절편 출력하기
print(f"회귀 계수: {model.coef_[0]:.3f}")
print(f"절편: {model.intercept_:.3f}")
# 새 집 예상 전기요금
new_house = np.array([[320, 6, 9]]) # 예측용 테스트 데이터(필요시 더 추가해보세요!)
pred = model.predict(new_house) # 예측하기
print("예상 전기요금:", pred[0])회귀 계수: 0.006
절편: 1.085
예상 전기요금: 4.904654970760234의료보험료 예측
의료보험 시스템에서는 각 개인의 건강 상태, 생활 습관, 인구통계학적 요인에 따라 산출되는 보험료가 매우 다양합니다.
예를 들어 나이, BMI(체질량 지수), 흡연 여부, 자녀 수, 거주 지역 등은 보험료에 큰 영향을 미치는 요소로 잘 알려져 있습니다.
Medical Cost Personal Dataset(insurance.csv) 를 활용하여
개인의 특성 정보를 기반으로 의료보험료를 예측하는 회귀 모델을 직접 구축해봅시다.
None으로 되어있는 부분을 직접 채워봅시다!
- 데이터셋을 읽고 간단한 탐색(EDA)을 진행합니다.
- 구조 파악
- 결측치 탐색 후, 만약에 있다면 처리하기
- X 데이터(독립 변수)와 y 데이터(종속 변수)를 분리합니다.
- 범주형 변수에 대해 모델 학습을 위해 OneHotEncoder로 인코딩을 진행합니다.
- 'sex', 'smoker', 'region'
- 수치형 변수에 대해 모델 학습을 위해 StandardScaler로 스케일링을 진행합니다.
- 'age', 'bmi', 'children'
- 2,3번이 진행된 결과에 train_test_split으로 훈련 데이터와 테스트 데이터를 분리합니다. (8:2 비율로)
- LinearRegression 모델을 생성 후, 학습합니다.
- 테스트 데이터에 대해 학습된 모델에 예측을 진행합니다.
- 예측 후, y_test와 y_predicted를 데이터프레임 형태로 출력합니다.
- 최종적으로 mean_squared_error와 r2_score로 모델의 성능을 출력합니다.
내가 한 풀이
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.metrics import mean_squared_error, r2_score
import numpy as np
# 데이터 로드
df = pd.read_csv("insurance.csv")
df
# 0. 간단한 EDA (구조 파악 및 결측치 탐색)
Q1 = df['charges'].quantile(0.25)
Q3 = df['charges'].quantile(0.75)
IQR = Q3 - Q1
outliers = df[(df['charges'] < Q1 - 1.5 *IQR) | (df['charges'] > Q3 + 1.5 * IQR)]
# 1. X, y 분리 (drop을 활용하세요!)
X = df.drop("charges", axis=1)
y = df["charges"]
# 스케일링할 컬럼 이름 목록을 리스트를 정의하세요
num_cols = df[['age', 'bmi', 'children']]
# 인코딩할 컬럼 이름 목록을 리스트로 정의하세요
cat_cols = df[['sex', 'smoker', 'region']]
# 2. 원핫 인코딩
# 인코더 생성하기
ohe = OneHotEncoder(sparse_output=False)
# 인코딩할 컬럼만 따로 추출하세요
# X_categories = ohe.fit_transform(cat_cols)
# 원핫 인코딩 수행하기
X_cat_encoded = ohe.fit_transform(cat_cols)
# 3. 스케일링(Z-Score)
# 스케일러 생성하기
scaler = StandardScaler()
# 스케일링할 컬럼만 따로 추출하세요
X_nums = scaler.fit_transform(num_cols)
# 스케일링 수행하기
X_num_scaled = pd.DataFrame(X_nums, columns=num_cols.columns)
# [수정 금지] 인코딩한 결과와 스케일링한 결과 합치기
# X_final: 스케일링/인코딩을 수행한 최종 결과 데이터
X_final = np.concatenate([X_num_scaled, X_cat_encoded], axis=1)
# 4. 훈련, 테스트 데이터 분할 (8:2)
X_train, X_test, y_train, y_test = train_test_split(X_final, y, test_size=0.2, random_state=42)
# 5. 회귀 모델 생성 후, 훈련
model = LinearRegression()
model.fit(X_train, y_train)
# None
# 6. 예측 진행
pred = model.predict(X_test)
# 실제 값과 예측 값 비교하는 데이터프레임 생성
result = pd.DataFrame({
'y_actual' : y_test,
'y_predicted' : pred
})
print(result)
# 7. 평가 진행 및 결과 출력
# -실제 값과 예측 값과의 오차에 대한 평가
rmse = np.sqrt(mean_squared_error(y_test, pred))
print("RMSE:", rmse) # RMSE
print(r2_score(y_test, pred)) # R2 Score y_actual y_predicted
764 9095.06825 8969.550274
887 5272.17580 7068.747443
890 29330.98315 36858.410912
1293 9301.89355 9454.678501
259 33750.29180 26973.173457
... ... ...
109 47055.53210 39061.500932
575 12222.89830 11761.499198
535 6067.12675 7687.563632
543 63770.42801 40920.291512
846 9872.70100 12318.586653
[268 rows x 2 columns]
RMSE: 5796.284659276274
0.7835929767120722
A Normal Programmer