머신러닝 문제 리뷰
2025년 11월 24일 월요일
오후 4:59
시험 합격 예측
한 학원에서 학생들의 학습 시간과 이전 시험 점수를 바탕으로 최종 시험 합격 여부를 예측하려고 합니다. Logistic Regression을 사용하여 학생의 합격 가능성을 예측하는 모델을 만들어보세요.
요구사항
1. 주어진 데이터셋을 train/test로 분리하세요 (test_size=0.2)
2. Logistic Regression 모델을 학습시키세요
3. 테스트 데이터에 대한 정확도를 출력하세요
4. 새로운 학생(학습시간=7, 이전점수=85)의 합격 여부를 예측하세요
예상 결과 출력
테스트 정확도: 1.00
예측 결과: 합격
합격 확률: 0.9999999367826911내가 한 풀이
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import numpy as np
import pandas as pd
data = {
"study_time": [2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 1, 2, 8, 9, 10],
"previous_score": [50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 45, 48, 88, 92, 96],
"pass": [0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1]
}
df = pd.DataFrame(data)
# 1. 데이터를 X, y로 분리하고, 훈련셋과 테스트셋으로 분리하세요
X = df[['study_time', 'previous_score']] # get dummies는 인코딩과 함과 동시에 x데이터 받을려 씀 무조건 쓰면 안됨 인코딩 하면서 부울링 할때만 씀 drop 방식도 써도 됨
y = df['pass']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 여기서도 순서 주의!
# 2. 모델 생성과 학습을 진행하세요.
model = LogisticRegression()
model.fit(X_train, y_train) # 여기서도 혼동 주의 fit은 훈련이기에 훈련데이터 써야 함
# 3. 테스트셋으로 예측 후, 정확도를 출력하세요.
y_pred = model.predict(X_test)# 학습 한 모델에 대해서 predict 테스트 데이터셋으로 예측
accuracy = accuracy_score(y_test, y_pred) # 실제 정답과 예측값이 얼마나 일치하는지 비교
print(f'테스트 정확도: {accuracy:.2f}')
# 4. 새로운 학생에 대한 예측 진행
new_students = np.array([[7, 85]]) # 공부시간=7, 이전 시험점수=85
new_pred = model.predict(new_students) # 새로운 학생에 대한 예측(실제예측) 혼동주의 확률값 구하고, 임계값을 통해 0인지1인지 예측 이럴때 쓰는게 predict_proba
probability = model.predict_proba(new_students) # 예측 확률을 구하세요 2차원 배열 넣기 사실상 둘이 같은거임 new_pred는 최종적으로 예측한 클래스 레이블 0or1
print(f'예측 결과: {"합격" if new_pred[0] == 1 else "불합격"}')
print(f'합격 확률: {probability[0][1]}') # [0]: 첫번째 행, [1]: '합격' 레이블
``
## 시험 합격 예측
한 학원에서 학생들의 학습 시간과 이전 시험 점수를 바탕으로 최종 시험 합격 여부를 예측하려고 합니다. Logistic Regression을 사용하여 학생의 합격 가능성을 예측하는 모델을 만들어보세요.
요구사항
1. 주어진 데이터셋을 train/test로 분리하세요 (test_size=0.2)
2. Logistic Regression 모델을 학습시키세요
3. 테스트 데이터에 대한 정확도를 출력하세요
4. 새로운 학생(학습시간=7, 이전점수=85)의 합격 여부를 예측하세요
예상 결과 출력테스트 정확도: 1.00
예측 결과: 합격
합격 확률: 0.9999999367826911
과일 분류
과일 가게에서 무게와 색상 점수를 기반으로 과일을 사과와 오렌지로 분류하려고 합니다. Decision Tree를 사용하여 과일을 분류하는 모델을 만들고, 의사결정 규칙을 확인해보세요.
요구사항
1. 주어진 데이터로 Decision Tree 모델을 학습시키세요 (max_depth=3)
2. 테스트 데이터에 대한 정확도를 출력하세요
3. 특성 중요도(feature importance)를 출력하세요
4. 새로운 과일(무게=180g, 색상점수=7)을 분류하세요
예상 결과 출력
테스트 정확도: 1.0
무게
: 1.000
색상점수
: 0.000
예측 결과: 오렌지내가 한 풀이
import numpy as np
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
data = {
"weight": [150, 170, 140, 130, 160,
180, 200, 190, 210, 195,
145, 155, 185, 205, 175],
"color_score": [8, 9, 7, 8, 9,
3, 4, 3, 2, 4,
7, 8, 3, 2, 4],
"label": [0, 0, 0, 0, 0,
1, 1, 1, 1, 1,
0, 0, 1, 1, 1]
}
df = pd.DataFrame(data)
# 1. 데이터 분리와 분할(test_size=0.2)을 수행하세요.
X = df[['weight', 'color_score']] # df.drop('label', axis=1) 도 가능
y = df['label']
# 2. 모델 생성 및 학습
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = DecisionTreeClassifier(
max_depth=3,
random_state=42
)
model.fit(X_train, y_train)
# 3. 테스트셋으로 예측 후, 정확도 출력
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_pred, y_test)# 실제값과 예측값 비교
print(f'테스트 정확도: {accuracy}')
# 4. 특성 중요도 출력
importances = model.feature_importances_# 중요 feature 계산, 핵심 feature 가져오기
for name, importance in zip(['무게
', '색상점수
'], importances):
print(f' {name}: {importance:.3f}')
# 5. 새로운 과일 예측
new_fruit = np.array([[180, 7]])
prediction = model.predict(new_fruit) # 새로운 데이터에 대한 예측
print(f"\n예측 결과: {'오렌지' if prediction[0] == 1 else '사과'}")요구사항 8:2비율 실수로 빼먹음
이메일 스팸 필터 만들기
이메일 서비스에서 특정 단어의 출현 빈도를 기반으로 스팸 메일을 자동으로 분류하는 시스템을 만들려고 합니다. '무료', '할인' 등의 단어 출현 횟수를 특성으로 사용하여 스팸 여부를 예측하는 Logistic Regression 모델을 만들어보세요.
요구사항
1. 주어진 데이터를 train/test로 분리하세요 (test_size=0.25, random_state=42)
2. Logistic Regression 모델을 학습시키고 정확도를 출력하세요
3. 새로운 이메일 3개에 대해 스팸 확률과 예측 결과를 출력하세요
예상 결과 출력
테스트 정확도: 1.00
이메일 1 (무료:1회, 할인:1회)
예측: 스팸
스팸 확률: 19.06%내가 한 풀이
import numpy as np
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# free_count: 무료 출현 횟수, discount_count: 할인 출현 횟수, spam: 스팸 여부
df = pd.DataFrame({
"free_count": [0, 0, 1, 1, 0,
2, 1, 2, 3, 2,
3, 4, 2, 4, 3,
5, 4, 5, 6, 5],
"discount_count": [0, 1, 0, 1, 2,
0, 2, 1, 2, 3,
3, 2, 4, 3, 4,
3, 5, 4, 5, 6],
"spam": [0, 0, 0, 0, 0,
0, 0, 1, 1, 1,
1, 1, 1, 1, 1,
1, 1, 1, 1, 1]
})
# 데이터 분리, 분할(test_size=0.25) 수행
X = df[['free_count', 'discount_count']] # 독립변수, df.drop('spam', axis=1) 도 가능
y = df['spam'] # 타깃변수
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state=42)
# 모델 생성 및 학습
model = LogisticRegression()
model.fit(X_train, y_train)
# 테스트 데이터셋으로 정확도 평가
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_pred, y_test) # 실제값, 예측값 비교
print(f'테스트 정확도: {accuracy:.2f}')
# 새로운 이메일 예측 수행(예측 확률, 최종 예측)
new_emails = np.array([
[1, 1], # 이메일 1: 무료 1번, 할인 1번
[0, 0], # 이메일 2: 무료 0번, 할인 0번
[5, 4] # 이메일 3: 무료 5번, 할인 4번
])
predictions = model.predict(new_emails) # 실제 예측이 된 결과(스팸이냐, 스팸이 아니냐)
probabilities = model.predict_proba(new_emails) # 그렇게 예측이 된 근거
# enumerate의 prediction을 predictions으로 수정
for i, (email, pred, prob) in enumerate(zip(new_emails, predictions, probabilities), 1):
print(f"이메일 {i} (무료:{email[0]}회, 할인:{email[1]}회)")
print(f" 예측: {'스팸' if pred == 1 else '정상'}")
print(f" 스팸 확률: {prob[1]:.2%}")
print()test_size = 0.25, random_state=42) 빼먹음
타이타닉 생존자 예측
Titanic 데이터셋은 1912년 타이타닉호 침몰 사고에서 승객들의 생존 여부를 다룬 유명한 데이터셋입니다. 승객의 나이, 성별, 객실 등급 등의 정보를 바탕으로 생존 여부를 예측하는 Decision Tree 모델을 만들어봅니다.
- 타겟: Survived (0: 사망, 1: 생존)
titanic3.csv파일을 읽고 아래 요구사항을 따르세요.
요구사항
- Titanic 데이터셋을 로드하고 기본 정보를 확인하세요
- 결측치를 처리하고 범주형 변수를 인코딩하세요
- 'age'와 'fare' 컬럼을 각각 중앙 값으로 채우세요.
- 'sex' 컬럼을 인코딩하세요. (여기서는 단순하게 pandas의 map()을 활용하세요.)
- (선택) 자유롭게 EDA 과정을 거쳐보세요!
- 데이터를 train/test로 분리하세요 (test_size=0.2, random_state=42)
- Decision Tree 모델을 학습하고 테스트 정확도를 출력하세요.
- 특성 중요도를 출력하세요.
- 트리 구조를 출력하고 주요 결정 규칙을 출력하세요.
- 테스트 데이터에 대한 예측 결과를 분석하세요.
예상 결과 출력(일부분)
테스트 정확도: 0.76
트리 깊이: 4
리프 노드 수: 16
새로운 승객 예측:
[1 0 1]
import numpy as np
import pandas as pd
from sklearn.tree import DecisionTreeClassifier, export_text, plot_tree
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
# 시각화 한글 깨짐 방지 설정
plt.rcParams['font.family'] ='Malgun Gothic'
plt.rcParams["axes.unicode_minus"] = False
# 1. 데이터 로드 및 기본 구조 확인
df = pd.read_csv('titanic3.csv')
df.shape()
# 2. 데이터 전처리
# 모델에 사용할 feature만 추출합니다. (pclass, sex, age, sibsp, parch, fare, survived)
# 사용할 feature 이름 리스트를 정의하세요.
features = df[['pclass', 'sex', 'age', 'sibsp', 'parch', 'fare', 'survived']]
df = features.copy()
df.describe()
# 2-1. 결측치 처리
# 결측치를 처리하고 범주형 변수를 인코딩하세요
# - 'age'와 'fare' 컬럼을 각각 중앙 값으로 채우세요.
# - 'sex' 컬럼을 인코딩하세요. (여기서는 단순하게 pandas의 map()을 활용하세요.)
print(df.isna().sum())# 결측치 처리
df['age'] = df['age'].fillna(df['age'].median()) # inplace=True 사용가능
df['fare'] = df['fare'].fillna(df['fare'].median())
# 2-2. 인코딩
# le = LabelEncoder()
# df['embarked'] = le.fit_transform(df['embarked'])
df['sex'] = df['sex'].map({'male':0, 'female':1}) # pd.getdummies도 가능
# 3. EDA 과정을 거쳐보세요! (선택)
# plt.boxplot(df['age'], df['fare'], df['sex'])
# plt.xticks([1,2,3], labels=['나이', '페어', '성별'])
# plt.title('1912년 타이타닉호 침몰 사고에서 승객들의 생존 여부')
# plt.show()
# 4. 데이터 X,y 분리 + 데이터 분할
X = df[['pclass', 'sex', 'age', 'sibsp', 'parch', 'fare']] # .drop('survived', axis=1)
y = df['survived']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
print(f'Train Size: {X_train.shape}')
print(f'Test Size: {X_test.shape}')
# 5. 모델 생성 및 학습 5. Decision Tree 모델을 학습하고 테스트 정확도를 출력하세요.
model = DecisionTreeClassifier(
criterion='gini',
max_depth=4,
random_state=42
)
model.fit(X_train, y_train)
# 6. 테스트 데이터로 예측 및 정확도 구하기
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f'테스트 정확도: {accuracy:.3f}')
# 7. 특성 중요도
importances = model.feature_importances_# 핵심 피처를 가져옴
feature_importance_df = pd.DataFrame({
'특성 이름': X.columns, # 독립변수 6개에 대한 이름 목록
'중요도': importances
}).sort_values('중요도', ascending=False)
print(feature_importance_df)
# 8. 트리 구조 출력
tree_rules = export_text(model, feature_names=X.columns)
print(tree_rules)
# 9. 트리 시각화(plot_tree)
plot_tree(model,
feature_names=X.columns,
class_names=['사망', '생존'],
filled=True,
rounded=True,
fontsize=10)
plt.title(f'Decision Tree (max_depth=4)')
plt.tight_layout()
plt.show()
# 10. 트리 정보 출력
print(f"\n트리 깊이: {model.get_depth()}")
print(f"리프 노드 수: {model.get_n_leaves()}")
# 11. 새로운 승객 예측
new_passengers = pd.DataFrame({
'pclass': [1, 3, 2],
'sex': [1, 0, 1], # 1: female, 0: male
'age': [25, 30, 40],
'sibsp': [0, 1, 1],
'parch': [0, 2, 0],
'fare': [100, 15, 50]
})
print("\n새로운 승객 예측:")
predictions = model.predict(new_passengers)
print(predictions)print(df.isna().sum())# 결측치 처리
pclass 0
sex 0
age 263
sibsp 0
parch 0
fare 1
survived 0
dtype: int64
Train Size: (1047, 6)
Test Size: (262, 6)
테스트 정확도: 0.763
특성 이름 중요도
1 sex 0.598113
0 pclass 0.202848
2 age 0.085930
5 fare 0.071196
3 sibsp 0.041914
4 parch 0.000000
|--- sex <= 0.50
| |--- age <= 9.50
| | |--- sibsp <= 2.50
| | | |--- age <= 0.79
| | | | |--- class: 0
| | | |--- age > 0.79
| | | | |--- class: 1
...
| | | | |--- class: 0
| | | |--- age > 5.50
| | | | |--- class: 0
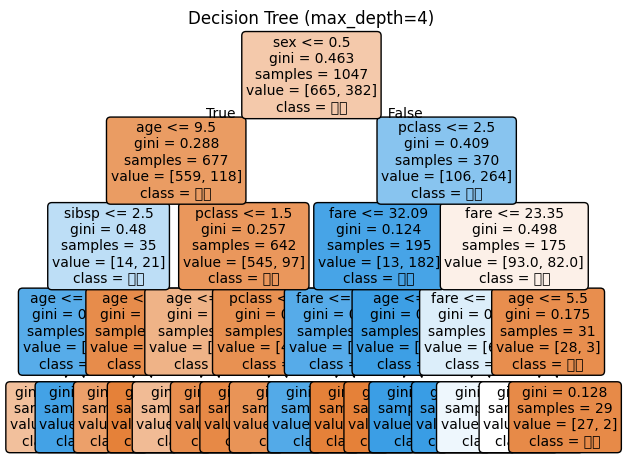
트리 깊이: 4
리프 노드 수: 16
새로운 승객 예측:
[1 0 1]
선택과제 EDA 시각화
내가 한 풀이
# 3. EDA 과정을 거쳐보세요! (선택)
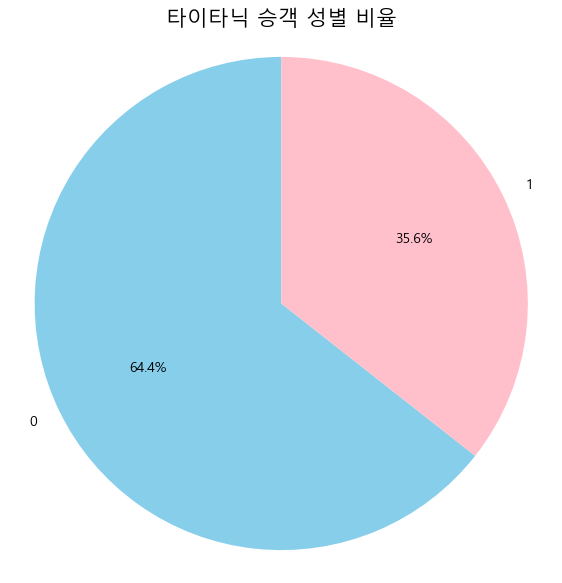
# 1. 'sex' 변수의 각 범주별 개수를 계산합니다.
sex_counts = df['sex'].value_counts()
# 2. 파이 그래프를 그립니다.
plt.figure(figsize=(7, 7))
plt.pie(
sex_counts.values, # 각 범주의 개수 (크기)
labels=sex_counts.index, # 범주 이름 ('male', 'female')
autopct='%1.1f%%', # 백분율 포맷 (소수점 첫째 자리까지)
startangle=90, # 시작 각도 설정
colors=['skyblue', 'pink'] # 색상 지정
)
# 3. 그래프 제목을 설정하고 축을 원형으로 조정합니다.
plt.title('타이타닉 승객 성별 비율', fontsize=15)
plt.axis('equal') # 파이 그래프를 완벽한 원으로 만듭니다.
plt.show()