Heap
여러 개의 값 중에서 가장 크거나 작은 값 등을 빠르게 찾기 위해 만들어진 이진 트리 자료구조, 짧게 Heap이라고 줄여서 부르기도 합니다.
영단어 자체의 의미로는 '무엇인가 차곡차곡 쌓아올린 더미'입니다.
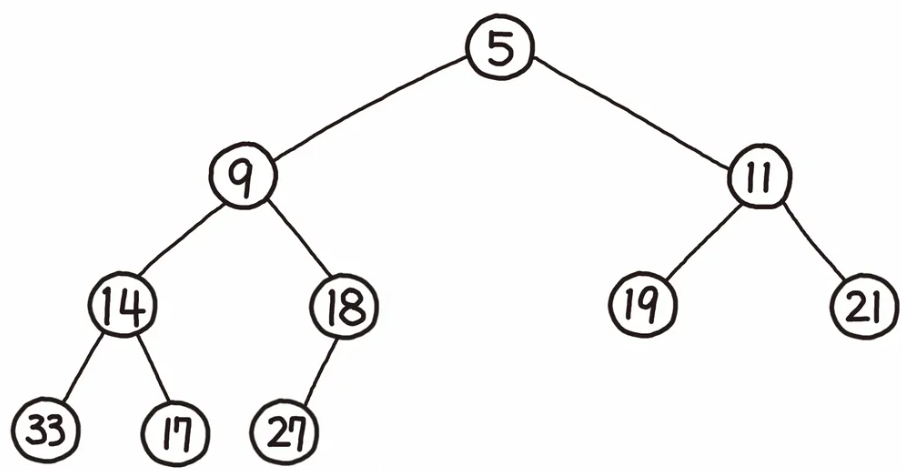
힙의 특징 중 하나로는 항상 완전 이진 트리의 형태이어야 합니다.
완전 이진 트리란?; 모든 Leaf Node의 높이가 최대 1 차이가 나고, 모든 노드의 오른쪽 자식이 있으면 왼쪽 자식이 있는 이진 트리입니다.
쉽게 이야기하자면, 원소를 왼쪽에서 오른쪽으로 하나 씩 빠짐없이 채워나간 형태를 의미합니다..
또 하나의 특징으로는, 이진 탐색 트리와는 다르게 Heap 트리에는 중복된 값 또한 허용합니다.
종류
최대 힙
- 부모 노드의 키 값이 자식 노드의 키 값보다 크거나 같은 완전 이진 트리
- Parent Key >= Child Key
최소 힙
- 부모 노드의 키 값이 자식 노드의 키 값보다 작거나 같은 완전 이진 트리
- Parent Key <= Child Key
데이터 처리
데이터의 삽입과 삭제 모두 O(logN)이 소요됩니다.
그 이유는 Heap은 완전 이진 트리의 구조이기 때문에 레벨이 늘어날 수록 노드의 수는 두배씩 증가하기 때문입니다.
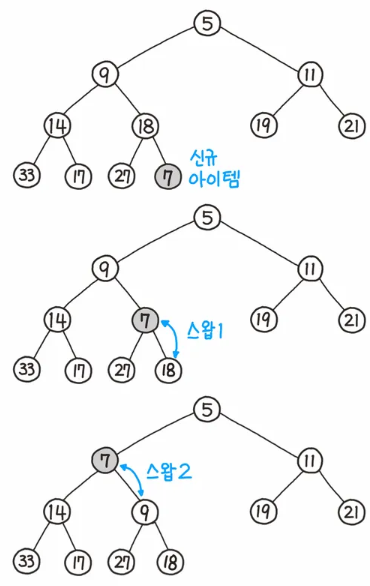
데이터 삽입
-
가장 끝의 자리에 노드를 삽입합니다.
-
그 노드와 부모 노드를 서로 비교합니다.
-
규칙에 맞으면 그대로 두고, 그렇지 않으면 부모와 교환합니다.
-
규칙에 맞을 때 까지 위의 3번 과정을 반복합니다.
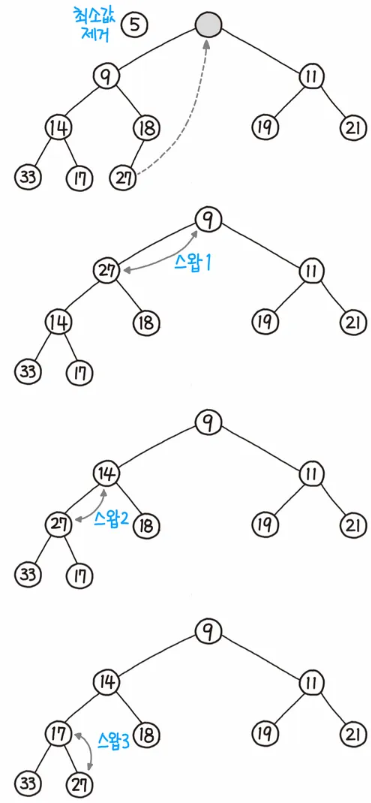
데이터의 삭제
- 루트 노드를 제거합니다.
( > 루트 노드란, 부모가 없는 노드를 의미합니다.)
-
루트 자리에 가장 마지막 노드를 삽입합니다.
-
올라간 노드와 그의 자식 노드를 비교합니다.
-
조건에 만족한다면 그대로 두고, 그렇지 않다면 자식과 데이터를 교환합니다.
-
조건을 만족할 때까지 4의 과정을 반복합니다.
Java에서의 Heap
java에는 Heap 자료구조가 따로 존재하지 않습니다.
그래서 최대 힙과 최소 힙을 Primary Queue를 활용하여 구현합니다.
최소 힙
PrimaryQueue<Type> minHeap = new PrioityQueue<>();최소 힙의 경우 Primary Queue를 그대로 사용하면 구현이 가능합니다.
최대 힙
PrioityQueue<Type> maxHeap = new PrioityQueue<Type>(new Comparator<Type>() {
@Override
public Type compare(Type a, Type b) {
return -Type.compare(a, b);
}
});최대 힙의 경우 최소 힙과는 다르게 Comparator 값을 세팅해야 사용이 가능합니다.
Heap을 공부하며 이진 탐색 트리와 비슷한 듯 다른 느낌에 많이 헷갈렸던 것 같습니다.
그렇지만 해당 자료구조를 잘 활용한다면 더욱 효율적인 구조의 코드가 가능할 것 같습니다.
이상 긴 블로그 글 읽어주셔서 감사드립니다.

참조 : Heap 나무위키