이번 포스팅에서는 Pod에 관한 전반적인 개념을 모두 다뤄볼 예정이다. 내용이 너무 많기때문에 아래의 주제 중에서 3가지만 먼저 얘기해보겠습니다!
- Pod의 개념과 Single Container Pod 실행 방법
- Multi Container Pod
- livenessProbe를 이용한 Self-healing Pod 생성하기
- Init Container
- Infra Container(pause) 이해하기
- Static Pod 생성하기
- Pod에 리소스(cpu, memory) 할당하기
- Pod의 환경변수 설정하기
Pod?
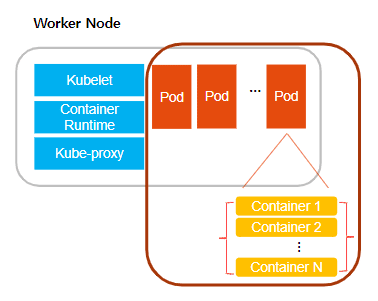
Pod(파드)는 쿠버네티스가 생성하고 관리하는 가장 작은 컴퓨팅 단위로 하나 또는 여러개의 컨테이너가 포함될 수 있다. 파드는 쿠버네티스 워커노드에 배치되어 실행되는데 쿠버네티스의 목적이 바로 파드들을 안정적이고 효율적으로 클러스터 내에서 실행시키는 것이라고 볼 수 있다.
Pod 실행하기
CLI로 생성하기
$ kubectl run web1 --image=nginx:1.14 --port=80
pod/web1 created
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
web1 1/1 Running 0 3m14skubectl run
kubectl run은 가장 간단하게 파드를 만드는 방식이다. 실행 커맨드에 각종 정보를 입력해서 생성하는데, 가장 간편하지만 실행시 입력한 정보가 남지 않는다는 단점이 있다.
yaml 파일로 생성하기
$ kubectl create -f pod-nginx.yaml
pod/nginx-pod created
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-pod 1/1 Running 0 53s 10.0.0.0 test-cluster-worker2 <none> <none>
web1 1/1 Running 0 5m34s 10.0.0.0 test-cluster-worker3 <none> <none>kubectl create
kubectl create는 파드의 정보가 기록된 yaml 파일을 활용해 파드를 생성한다. 입력한 정보가 파일 형태로 남아있기 때문에 재실행하거나 문제의 원인을 찾는 등의 작업이 수월하다.
트러블 슈팅
$ kubectl create -f pod-nginx2.yaml
pod/nginx-pod2 created
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-pod2 0/1 ContainerCreating 0 10s
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-pod2 0/1 ImagePullBackOff 0 110s새로운 파드를 생성 요청했을 때 어떠한 에러로 인해 정상적으로 실행되지 않는 경우 위의 명령어를 통해 파드의 status 값을 조회하는 것으로 어느정도 원인을 파악할 수 있다. 하지만 더 명확히 트러블 슈팅할 수 있는 방법이 있다.
바로 kubectl describe pod - 명령어를 통해 파드의 상세 정보를 확인할 수가 있는데 맨 마지막쯤에 파드가 생성되는 이벤트 과정을 로그로 보여준다.
$ kubectl describe pod nginx-pod2
.
.
.
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 2m8s default-scheduler Successfully assigned default/nginx-pod2 to test-cluster-worker3
Normal BackOff 30s (x5 over 118s) kubelet Back-off pulling image "nginx:2.14"
Warning Failed 30s (x5 over 118s) kubelet Error: ImagePullBackOff
Normal Pulling 19s (x4 over 2m8s) kubelet Pulling image "nginx:2.14"
Warning Failed 8s (x4 over 119s) kubelet Failed to pull image "nginx:2.14": rpc error: code = NotFound desc = failed to pull and unpack image "docker.io/library/nginx:2.14": failed to resolve reference "docker.io/library/nginx:2.14": docker.io/library/nginx:2.14: not found
Warning Failed 8s (x4 over 119s) kubelet Error: ErrImagePull로그에서 'Failed to pull image "nginx:2.14" ~' 를 통해 nginx :2.14 이미지가 존재하지 않아 다운로드 하지 못했다고 알려주고 있다. yaml 파일에서 이미지가 존재하는 버전으로 수정해준 다음 새롭게 생성해주면 정상적으로 파드가 실행될 것이다.
Multi Container Pod
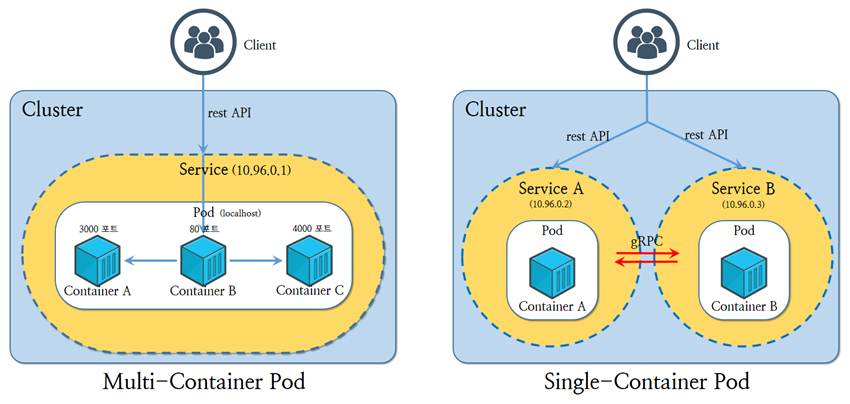
Multi Container Pod는 하나의 파드 안에 여러개의 컨테이너가 존재하는 것이다. 컨테이너 간에 어떠한 유기적인 관계를 연동하여 동작하는 형태이다.
Multi Container Pod 실행하기
// pod-multi.yaml
apiVersion: v1
kind: Pod
metadata:
name: multipod
spec:
containers:
#first pod
- name: nginx-container
image: nginx:1.14
ports:
- containerPort: 80
#second pod
- name: centos-container
image: centos:7
command:
- sleep
- "10000"$ kubectl create -f pod-multi.yaml
pod/multipod created
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
multipod 2/2 Running 0 4m11s 10.0.0.0 test-cluster-worker3 <none> <none>kubectl get 명령어에서 알 수 있듯이 컨테이너는 하나의 IP를 공유하기 때문에 <파드 IP>:80로 접속하면 nginx에 접속될 것이다. 또한 centos-container 내부로 들어가 localhost:80으로 접속하면 동일한 페이지에 접속할 수 있다. 이는 같은 파드 안에서 동작 중이기 때문이다.
파드 내 멀티 컨테이너에 각각 접속하는 방법
kubectl exec 명령어에 -c 옵션과 함께 컨테이너명을 선언해주면 된다.
// nginx 컨테이너에 접속
kubectl exec multipod -c nginx-container -it -- /bin/bash
// centos 컨테이너에 접속
kubectl exec multipod -c centos-container -it -- /bin/bashcentos-container 내부에서 curl 명령어를 통해 localhost:80으로 nginx가 접속되는지 확인해보자!
[root@multipod /]# curl localhost:80
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
...
</head>
<body>
<h1>Welcome to nginx!</h1>
...
</body>
</html>
livenessProbe를 이용한 Self-healing Pod 생성하기
Probe(프로브)는 kubelet에 의해 주기적으로 컨테이너를 진단하는데 그 중 livenessProbe는 컨테이너가 동작 중인지 여부를 나타낸다. 만일 컨테이너가 제대로 동작되지 못한다면 kubelet은 컨테이너를 죽이고 재시작하는 정책을 수행한다. 이는 쿠버네티스가 건강한 컨테이너로 서비스를 할 수 있음을 보장해준다.
또한 컨테이너에 문제가 생겨 재시작 하더라도 파드가 아닌 컨테이너 만을 재시작하기 때문에 IP주소가 변경되지 않는다.
livenessProbe 매커니즘
livenessProbe의 핸들러는 HTTPGetAction, TCPSocketAction, ExecAction 세 가지 타입이 있는데 yaml 파일의 spec에 정의한다.
HTTPGetAction
livenessProbe:
httpGet
path: /
port: 80IP주소, port, path에 HTTP GET 요청을 보내 해당 컨테이너가 응답하는지 확인한다. 반환 코드가 200이 아닌 값이 나오면 컨테이너 진단에 실패(Failure)되고 컨테이너를 다시 시작한다.
TCPSocketAction
livenessProbe:
tcpSocket:
port: 22지정된 포트에 TCP 연결을 시도. 연결되지 않으면 컨테이너를 다시 시작한다.
ExecAction
livenessProbe:
exec:
command:
- ls
- /data/fileexec 명령을 전달하고 명령의 종료코드가 0이 아니면 컨테이너를 다시 시작한다. 해당 컨테이너에서 동작 중인 프로세스를 체크할 수 있다.
livenessProbe 매개변수
livenessProbe 매개변수로는 다음과 같이 세 가지가 있다.
- periodSeconds: health check 반복 실행 시간(s)
- initialDelaySeconds: Pod 실행 후 delay할 시간(s)
- timeoutSeconds: health check후 응답을 기다리는 시간(s)
간단한 예제를 통해 매개변수의 default 값을 확인해보도록 하자.
// pod-nginx-liveness.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod
spec:
containers:
- name: nginx-container
image: nginx:1.14
ports:
- containerPort: 80
protocol: TCP
livenessProbe:
httpGet:
path: /
port: 80nginx 서버를 실행하는 간단한 yaml에 livenessProbe의 핸들러 중 httpGet만을 선언해주고 매개변수에 대한 값은 별도로 설정하지 않았다.
$ kubectl create -f pod-nginx-liveness.yaml
pod/nginx-pod created
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-pod-liveness 1/1 Running 0 4s
$ kubectl describe pod nginx-pod-liveness
...
Liveness: http-get http://:80/ delay=0s timeout=1s period=10s #success=1 #failure=3
...위의 설정 파일에서 분명 매개변수에 대한 값은 설정해주지 않았는데 실행 후 상세 정보를 확인해보니 Liveness에 대한 default 값이 들어가 있는 것을 볼 수 있다. (이후 yaml)
-
delay=0s : initialDelaySeconds에 대한 상태로 파드를 실행 후 언제부터 health check를 실행할 것인지 알려주고 있다.
-
timeout=1s : timeoutSeconds에 대한 상태로 health check 후 1초 동안 응답을 기다리겠다는 것이다.
-
period=10s : periodSeconds에 대한 상태로 10초마다 한번씩 검사하겠다는 것이다.
-
#success=1 #failure=3 : seccess가 1번 발생하면 프로브 결과가 Success, failure가 3번 발생하면 컨테이너 진단에 실패(Failure)했다는 의미이다.
※ 동작중인 파드를 yaml 형태로 보면 default 매개변수가 삽입되어 있는 것을 확인할 수 있다. 해당 부분을 카피하여 yaml 파일에 추가하는 것으로 수정하는 방법도 있으니 참고하자.
일부러 오류를 만들어 테스트 해보자!
smlinux/unhealthy 이미지는 10초마다 한번씩 총 5번의 요청만을 허용해주고 이후 500번의 에러를 응답하는 컨테이너이다.
// pod-liveness.yaml
apiVersion: v1
kind: Pod
metadata:
name: liveness-pod
spec:
containers:
- image: smlinux/unhealthy
name: unhealthy-container
ports:
- containerPort: 8080
protocol: TCP
livenessProbe:
httpGet:
path: /
port: 8080해당 이미지를 활용한 yaml 파일을 통해 파드를 생성하고 상태를 모니터링 해보자.
$ kubectl describe pod liveness-pod
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 2m11s default-scheduler Successfully assigned default/liveness-pod to test-cluster-worker
Normal Pulling 2m10s kubelet Pulling image "smlinux/unhealthy"
Normal Pulled 59s kubelet Successfully pulled image "smlinux/unhealthy" in 1m11.271s (1m11.271s including waiting). Image size: 263841919 bytes.
Normal Created 59s kubelet Created container unhealthy-container
Normal Started 59s kubelet Started container unhealthy-container
Warning Unhealthy 1s kubelet Liveness probe failed: HTTP probe failed with statuscode: 500
파드가 실행되고 60초 이후에 'Liveness probe failed...statuscode: 500'가 발생되었다.
...
Normal Pulled 21s kubelet Successfully pulled image "smlinux/unhealthy" in 1.654s (1.654s including waiting).
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
liveness-pod 1/1 Running 1 (21s ago) 2m41s이벤트 모니터링을 계속 진행하다 보면 실패가 난 이후에 kubelet이 해당 컨테이너를 새롭게 시작한 로그를 확인할 수 있다.
kubectl get pod 또한 RESTARTS 값에 재시작 한 횟수가 카운팅 된 것을 볼 수 있다.
이렇게 Pod의 모든것 1편에 대해 정리가 끝났다. 아직 많은 내용이 많이 남아있으니까 다음편도 기대해주시라!
[참고자료]
