OOV에 대한 전반적인 설명은 이전 포스팅에서 다루었다.
Ziniu Hu, Ting Chen, Kai-Wei Chang, and Yizhou Sun. 2019. Few-Shot Representation Learning for Out-Of-Vocabulary Words. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4102–4112, Florence, Italy. Association for Computational Linguistics.
Introduction
분산 단어 임베딩 (Distributional word embedding) 모델들은 유사한 문맥에서 나타나는 단어는 유사한 의미를 가진다는 분포가설(Distributional Hypothesis)을 따른다. 이에 저차원 벡터에 단어의 의미를 분산하여 표상한다. 그런데 실험 코퍼스에 있는 단어가 훈련 코퍼스에 부재했거나 빈도가 매우 낮은 경우, 즉 Out-of-Vocabulary (OOV) 단어는 이러한 문맥 기반 임베딩 모델들이 임베딩 벡터를 정확하게 추론할 만한 정보가 부족하다. OOV 문제는 다음과 같은 연구 질문으로 표현할 수도 있다.
추론 시간 동안 OOV 단어를 몇 번만 관찰하고도 OOV 단어에 대한 정확한 임베딩 벡터를 어떻게 학습할 수 있을까?
인간은 단어의 다음처럼 1)문맥과 2)형태에 대한 총체적인 이해를 바탕으로 단어의 의미를 유추해내는 능력이 있다.
1. OOV 단어가 포함된 문장 몇 개만 주어진다면 각 문장의 의미를 해석하고 여러 문장을 종합하여 단어의 의미를 유추한다.
2. 문맥 정보를 서브워드(sub-word)나 다른 형태학적 요소를 결합하여 더욱 정교하게 단어의 의미를 유추한다.
본 연구에서는 OOV 임베딩의 학습을 퓨샷(few-shot) 회귀 문제로 정식화하면서, 적은 샘플로도 단어의 의미를 유추해내는 구조를 제안한다.
- 어텐션(attention) 기반 계층적 문맥 인코더 (HiCE)가 멀티 헤드 셀프 어텐션(multi-head self-attention)을 통해 여러 문맥에서 가져온 정보를 병합하고,
- OOV 단어의 문자 임베딩 벡터를 구한다. 두 정보를 결합한 것이 최종 OOV 단어 임베딩 벡터이다.
The Approach
The Few-Shot Regression Framework
본 연구는 인공 신경망이 학습할 회귀 함수 를 정의한다. 매개변수 는 훈련 코퍼스 로부터 정의된다.
에 입력으로 몇 개의 문맥 정보와 단어의 형태학적 특징이 주어지면, 출력 임베딩은 충분히 많은 관찰로부터 학습했다고 가정한 오라클(oracle) 임베딩 벡터와 최대한 가까워야 한다.
이를 위해 해당 심층 회귀 함수는 이미 훈련 코퍼스에서 충분히 관찰된 개의 단어들 을 가지고 매개변수의 최적값을 구한다. 각 단어의 임베딩 벡터 가 하나의 오라클 임베딩이 된다.
퓨샷 러닝 과제에서처럼 번의 에피소드를 생성하여 함수를 학습시킨다. 각 에피소드마다 다음의 과정을 거친다. 안에 를 포함하는 모든 문장들을 라고 하자.
- 로부터 개의 문장들을 무작위 추출하고, 해당 문장들에서 를 마스킹하여 마스킹된 문맥 집합 를 구한다.
- 의 문자 시퀀스를 로 명명하여 형태적 특징들로 정의한다.
임베딩 간 유사도는 코사인 유사도로 구할 때, 훈련 목표는 다음과 같다:
이 훈련되면 추론 시간에 OOV의 문맥 정보와 OOV 단어의 문자 시퀀스를 함수에 넣어 OOV 단어의 임베딩 벡터를 구할 수 있게 된다.
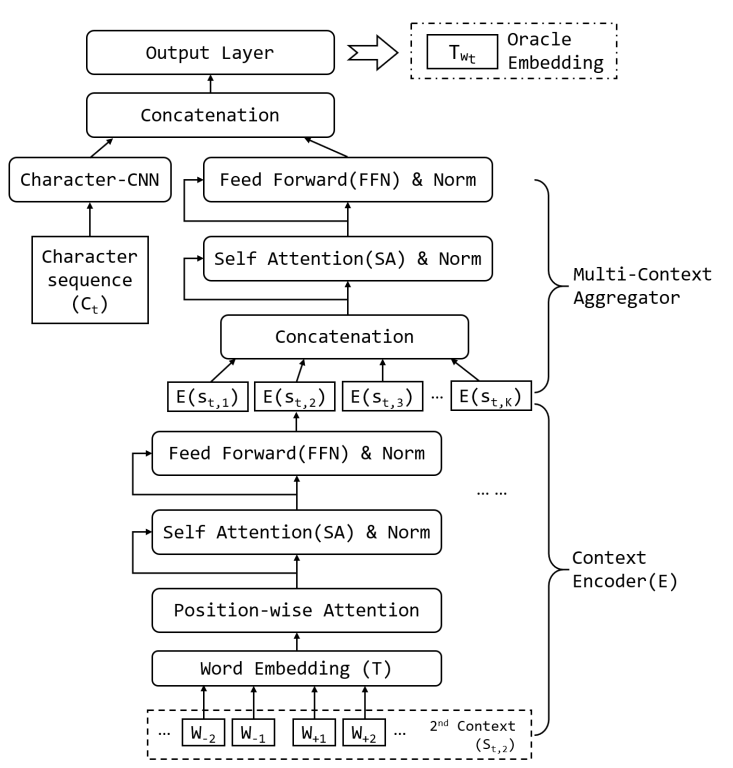
Hierarchical Context Encoding (HiCE)
함수는 복합적인 정보를 문맥으로부터 추출하고 병합하고, 형태학적 정보도 반영해야 하므로 더욱 정교한 인코더가 필요하다. 본 연구에서는 셀프 어텐션 기법을 기반으로 한 트랜스포머를 기본 단위로 하여 HiCE 구조를 설계하고, 이를 함수로서 사용한다.
Self-Attention Encoding Block
셀프 어텐션은 자기 자신에 수행하는 어텐션으로, 입력 시퀀스 행렬을 query, key, value의 세 가지 행렬로 표상하고, scaled dot product으로 스케일링을 수행한다. 이를 여러번 병렬로 수행한 뒤 결합하는 멀티 헤드 어텐션(multi-head self-attention) 기법을 연구에서는 적용한다. 잔차 연결(residual connection)과 계층 정규화(layer normalization)은 트랜스포머 논문에서와 동일하게 적용하여 빠른 수렴 속도와 범용성을 꾀한다. 연구진은 단어들의 상대 위치 정보를 반영하기 위해 포지셔널 임베딩보다는 포지션 어텐션(position-wise attention) 단위에서 특정 값을 곱해주는 방식을 취한다.
HiCE Architecture
종합하면, HiCE 구조는 크게 두 가지 계층으로 구성된다:
- Context Encoder: 2개(왼쪽, 오른쪽) 이상의 문맥 단어들의 임베딩 벡터에 멀티 헤드 셀프 어텐션을 적용하여 문맥 임베딩 벡터를 구한다.
- Multi-Context Aggregator: Context encoder로부터 인코딩된 모든 문맥 정보에 셀프 어텐션을 적용하여 전체 문맥 임베딩 벡터를 구한다.
여기에 OOV 단어 내 문자들을 Character-CNN의 입력값으로 활용하여 문자 임베딩 벡터를 생성하고, 이를 Multi-Context Aggregator의 출력과 결합하여 최종 OOV 단어에 대한 임베딩 벡터를 생성한다.
Fast and Robust Adaptation with MAML
함수가 훈련된 훈련 코퍼스 와 실험 코퍼스 간에 간극이 있다면 제대로 된 임베딩이 생성되지 못할 수 있다. 같은 형태의 단어들이 다른 도메인이나 시기에 쓰일 경우 다른 의미를 가질 수 있기 때문이다.
본 연구에서는 Model Agnostic Meta-Learning (MAML) 기법을 차용하여 HiCE의 일반화 성능을 강화한다. 실험 코퍼스 전체에 대해 미세조정(fine-tuning)하는 대신, 실험 코퍼스 내 샘플 몇 개만 가지고도 매개변수가 적절히 업데이트 및 적합될 수 있도록 함수를 훈련시키는 것이다.
- 훈련 코퍼스 에 대해 훈련 시 경사 하강법을 이용해 매개변수 가중치 를 구한다.
- 실험 코퍼스 내 몇 개 샘플에 대해 훈련 시 를 초기값으로 확률적 경사 하강법 (Stochastic Gradient Descent)을 이용해 매개변수 가중치를 업데이트한다().
Experiments
HiCE는 WikiText-103 데이터로 훈련하며, 임베딩 벡터는 nonce2vec 연구에서 제공하는 것을 사용한다.
Baseline Methods
- Word2Vec: 중심 단어에서 주변 단어를 예측하는 Skip-gram 방식으로 학습하여 단어 임베딩
- FastText: Word2Vec의 확장으로, 서브워드를 고려하여 단어 임베딩
- Additive: 문맥 문장들의 단어 임베딩 벡터들을 평균하여 OOV 임베딩
- nonce2vec: Word2Vec의 확장 개선판으로, 더 나은 additive 벡터 초기값, 높은 학습률, 큰 문맥 윈도 등 수정사항 반영
- a la carte: Additive 모델을 기반으로 선형변환 적용
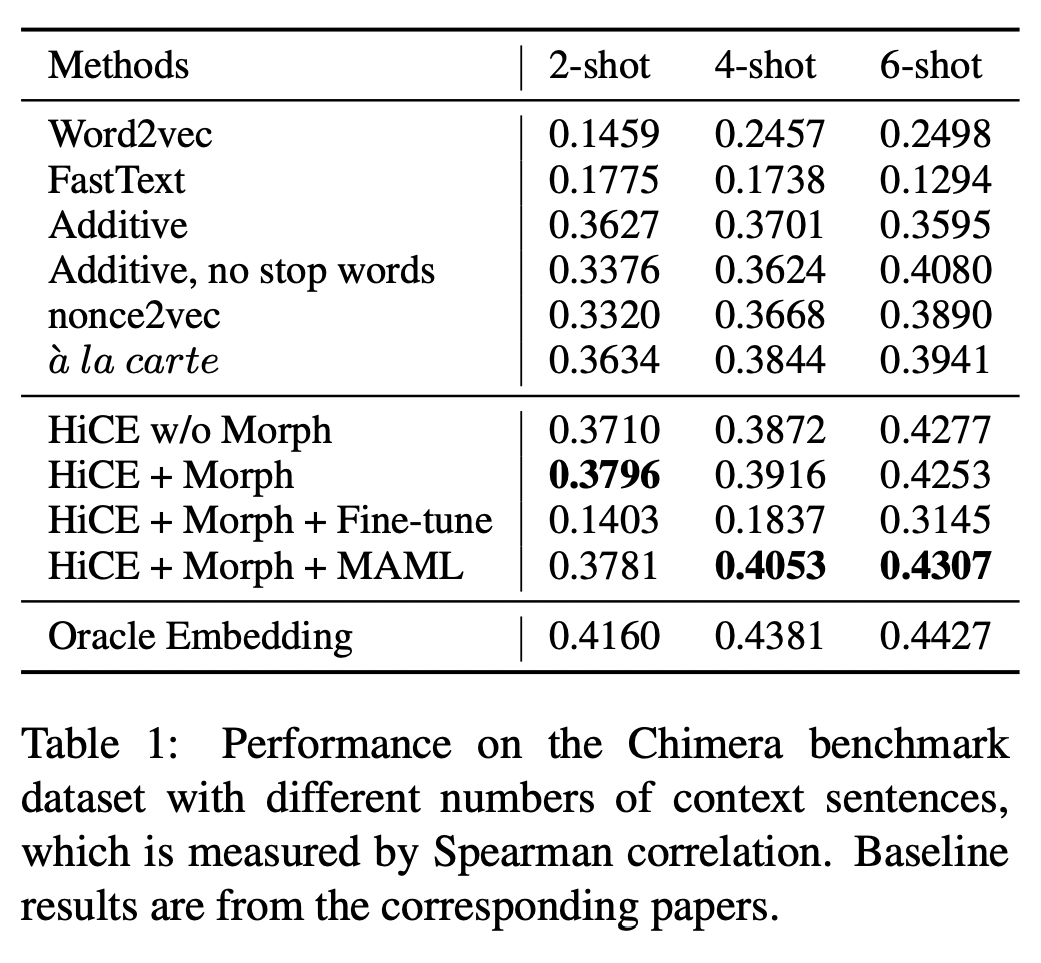
Intrinsic Evaluation: Evaluate OOV Embeddings on the Chimera Benchmark
Chimera Benchmark에 관한 설명은 이전 포스팅에서 언급했다.
- HiCE에 형태적 특징들을 반영하면 문맥 정보가 부족한 2-shot, 4-shot 세팅에서 성능 개선이 확인된다.
- HiCE에 형태적 특징들을 반영하고 MAML로 adaption을 개선하면 문맥 정보가 많은 4-shot, 6-shot 세팅에서 성능이 크게 개선된다. MAML은 미세조정보다도 더 유연하고 범용적인 것이 확인된다.
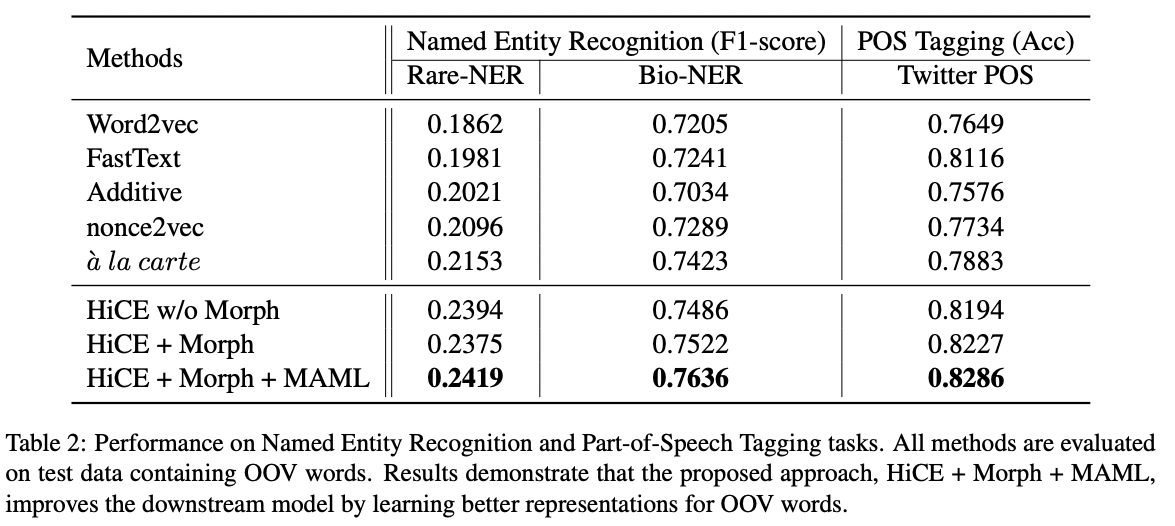
Extrinsic Evaluation: Evaluate OOV Embeddings on Downstream Tasks
- HiCE + Morph + MAML가 최고성능을 보인다.
- OOV 단어 비율이 더 높은 Rare-NER에서는 F1-score가 대체로 다 낮다.
- HiCE가 위키피디아 코퍼스에 훈련되었음에도 불구하고, 소셜미디어(Rare-NER)와 생명과학(Bio-NER) 분야의 실험 코퍼스에서도 좋은 성능을 보인 것은 MAML을 통한 일반화 성능이 좋음을 암시한다.
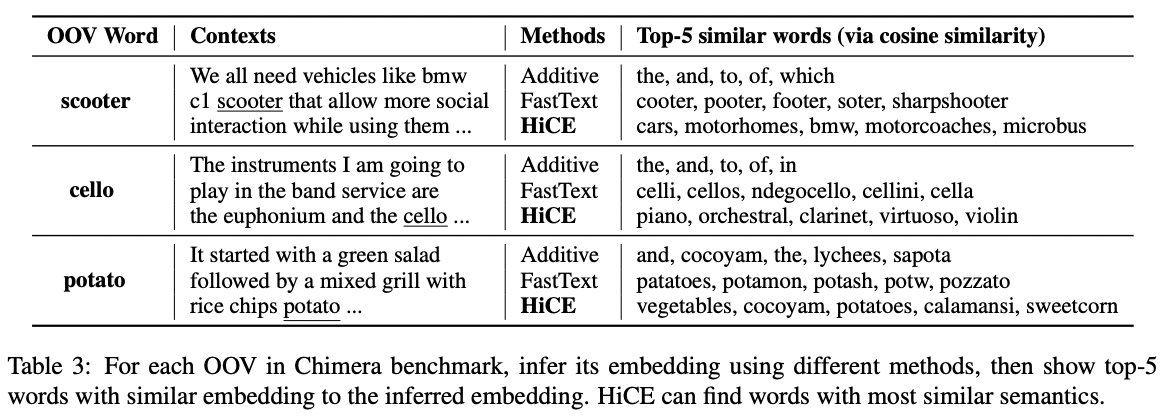
Qualitative Evaluation of HiCE
-
HiCE는 중심 단어와 관련 있는 단어들에 높은 어텐션 가중치를 잘 부여한다. 문장 단위 문맥에 대해서도 중요도를 잘 구분하고 있다.

-
HiCE는 OOV 단어들의 진짜 의미를 잘 포착해낸다. Additive는 의미론적, 형태론적으로 모두 무관한 단어들을, FastText는 의미론적으로 상이한 단어들을 포함시키는 것과는 차이가 있다.