오늘은 미니프로젝트가 끝나고 다시 이론을 공부하는 날이였습니다. 오늘은 미니프로젝트에 대해서 공부했습니다.
서버와 클라이언트
클라이언트가 URL요청을 하면 웹 서버에서는 request(요청)을 받아서 데이터를 클라이언트에게 response(응답) 해줍니다. 그러면 해당 데이터를 가지고 컴퓨터에 보여줍니다.
▶URL의 구성요소
https://는 프로토콜이라 합니다. 프로토콜은 통신 규약을 나타냅니다.
DNS는 예를들어 naver.com을 IP주소로 바꿔주는 역할을 진행합니다. IP주소는 컴퓨터의 고유한 주소입니다.
포트번호는 서버 컴퓨터에서 어떤 서비스를 이용할 지 분류해줍니다.
path는 디렉토리 경로를 알 수 있어서 어떤 디렉토리에 접근할 것인지 알 수 있습니다.
page는 디렉토리 안의 파일을 의미합니다.
▶인터넷
인터넷은 컴퓨터로 연결하여 TCP/IP라는 통신 규약을 사용해서 데이터를 주고 받는 컴퓨터 네트워크를 의미합니다.
데이터 요청 방식
▶get방식
URL에 데이터가 포함되어 있으며 길이에 제한이 있습니다.
▶post방식
데이터가 body에 포함되어 있는 방식이라 URL에 데이터가 안보입니다.
쿠키(cookie)와 세션(session)
Cookie는 클라이언트에 저장하는 문자열 데이터로 도메인별로 따로 저장이 이뤄집니다.
Seesion은 연결 정보이며, 브라우저와 연결 시 세션ID가 생성이 됩니다.
※Cache(캐쉬)는 메모리에 저장했다가 빠르게 데이터를 가져오는 목정의 저장소!
HTTP Status Code
서버와 클라이언트가 데이터를 주고 받으면서 주고 받은 결과를 상태코드로 확인이 가능합니다.
200번대 코드는 성공적으로 데이터가 송수신 되었을 때 나타납니다.
300번대 코드는 저장되어 있는 데이터를 불러올 때 나옵니다.
400번대 코드는 request에러가 발생해 없는 페이지가 호출될 때 나옵니다.
500번대 코드는 server에러로 서버에서 데이터를 받을 때 클라이언트가 잘못된 데이털를 요청했을 때 나옵니다.
웹 크롤링 방법
크롤링 방법에 앞서 웹 페이지 종류를 먼저 알아보겠습니다.
▶웹 페이지 종류
정적 페이지는 화면내에서 이벤트로 인한 변경이 없는 페이지를 정적 페이지라고 합니다.
동적 페이지는 이벤트로 인해 화면의 변경이 있는 것을 의미합니다.
다음으로는 웹 크롤링 방법에 대해서 알아보겠습니다.
▶request 이용
받아오는 문자열에 따라 두가지 방법으로 나눠집니다.
json 문자열로 받아오는 방식으로 주로 동적 페이지 크롤링을 할 때 사용합니다.
html 문자열을 받아오는 방식은 주로 정적 페이지 크롤링을 할 때 사용합니다.
▶selenium 이용
브라우저를 직접 열어서 크롤링이 가능합니다.
데이터 수집의 순서
크롤링을 진행할 때 아래와 같은 순서로 진행합니다.
- 웹 서비스 분석 => 크롤링할 곳의 URL을 찾습니다.
- 서버에 데이터 요청
- 서버에서 받은 데이터 피싱(데이터 형태를 변환함)
서버에서 어뷰징을 막았을 때
서버관리자가 어뷰징을 막았을 경우 관리자도구를 통해 웹 페이지를 분석해보면 header의 user-agent의 값을 확인할 수 있습니다. 그 값을 같이 넣어서 매개변수로 넘겨주거나 reference를 가져와서 붙여주면 해결이 될 수도 있습니다.
당연히 모든 웹 페이지가 그런것은 아닙니다.
크롤링 정책
robots.txt에 크롤링 정책 설명이 명시되어 있습니다.
만약 네이버의 크롤링 정책을 확인해볼려 한다면 주소창에 naver.com/robots.txt라고 입력을 해주면 네이버 크롤링 정책이 적힌 텍스트 파일 하나가 다운로드 됩니다.
크롤링법은 아직 법적으로 정해진 것은 없지만 과도한 크롤링으로 인하여 서비스에 영향을 줄 수 있습니다(DDOS 공격). 그러면 업무방해로 인해 고소가 들어올 수 있으니 조심해야합니다.
법적 문제를 피하기 위해서 API를 활용하기도 합니다. API를 사용하면 데이터를 가지고 있는 업체에서 데이터를 사용자가 가져갈 수 있도록 합니다.
API사용
- 클라이언트가 app(애플리케이션) 등록(API이용신청)을 하면 서버에서 key 값을 반환해줍니다.
- URL을 확인합니다. => doc문서에 확인하면 사용법과 URL이 같이 있습니다.
- request와 response를 해줍니다.
- 받은 데이터를 파싱하여 최종적으로 데이터프레임으로 변환해줍니다.
실습
먼저 API사용이 아닌 웹 크롤링을 진행하겠습니다.
▶동적 페이지 크롤링
동적 페이지 크롤링을 진행하면 데이터형태가 json형태입니다. xml형태도 있는데 요즘은 대부분이 json형태라고 합니다.
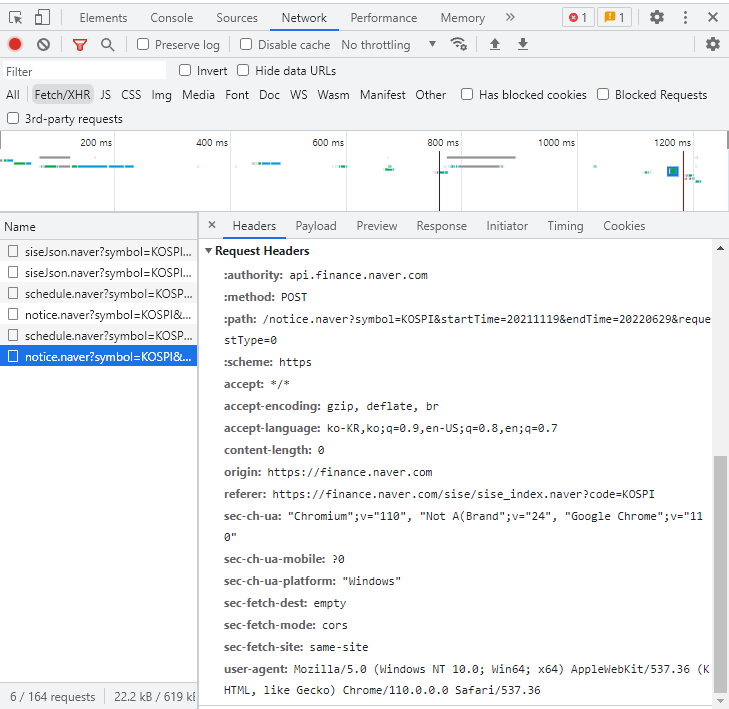
먼저 크롤링 진행을 위해 URL을 알아야하는데 크롤링을 원하는 해당 페이지까지 이동 후 관리자도구를 열어줍니다. 저는 F12키를 눌러서 관리자도구를 열어주었습니다. 관리자도구를 열어준 후에 위의 메뉴들 중에 Network를 눌러주면 Fetch/XHR이 있습니다. 그 부분에서 크롤링하고 싶은 웹 사이트를 분석합니다.
▶동적 페이지 크롤링 순서
1. 웹서비스를 분석해서 URL을 찾아줍니다.
환경설정
import pandas as pd
import requests
필요한 패키지를 가져왔으면 URL을 찾아서 url 변수에 넣어줍니다.
url = f'url주소'f-formating을 사용해준 이유는 가져온 url에 데이터를 넘겨줄 때 변수를 섞어서 사용하기 위해 사용합니다.
2. 서버에 데이터 요청
request(URL) -> response : json(str)
url을 요청하면 json(str)타입의 문자열로 이루어진 데이터를 받습니다.
response = requests.get(url)
respinse #통신이 원할히 이루어졌다면 <Response [200]>라는 값을 반환합니다.3. 데이터 파싱(데이터프레임으로 데이터형태를 변환)
위 에서 사용한 코드들을 통해 데이터를 받아왔다면 이제 데이터의 형태를 데이터프레임으로 바꿔줍니다.
type(response)response는 requests.models.Response타입을 반환합니다.
data = response.json()data의 타입은 list입니다.
df = pd.DataFrame(data)['뽑아줄 컬럼명']위 코드를 작성해주면 data의 컬럼중에서 뽑아줄 컬러명을 설정하여 원하는 컬럼만 뽑아서 데이터프레임으로 만들어줍니다.
▶API활용
API활용을 위해서는 app등록이 이루어져야 합니다. app 등록이 완료되면 key와 id를 지급해줍니다.
나머지의 순서는 동적 페이지 크롤링과 같습니다만 발급 받은 키와 ID를 header에 넣어주면 됩니다.
사용방법은 대부분 doc에 설명이 되어 있습니다.
미니프로젝트 끝나고 오랜만에 이론을 나간다는 느낌을 받았습니다. 여러가지 많이 알려주시고 재밌었던 수업이었습니다. 내일은 정적 페이지 크롤링을 배운다는데 기대가 됩니다.
※공부하고 있어 다소 틀린점이 있을 수 있습니다. 언제든지 말해주시면 수정하도록 하겠습니다.
※용어에 대해 조금 공부 더 해서 수정하겠습니다.
