오늘은 머신러닝 3일차로 어제에 이어 여러 알고리즘을 더 배운 날이였습니다.
알고리즘
어제에 이어 머신러닝에서 사용되는 다양한 알고리즘에 대해 계속 알아보는 날이였습니다.
▶학습곡선
데이터가 많으면 성능이 항상 좋은지에 대해 의문이 있을 것입니다.
학습곡선을 통해 이를 알아보고자 학습곡선을 그려보면 아래와 같은 그래프가 그려집니다.
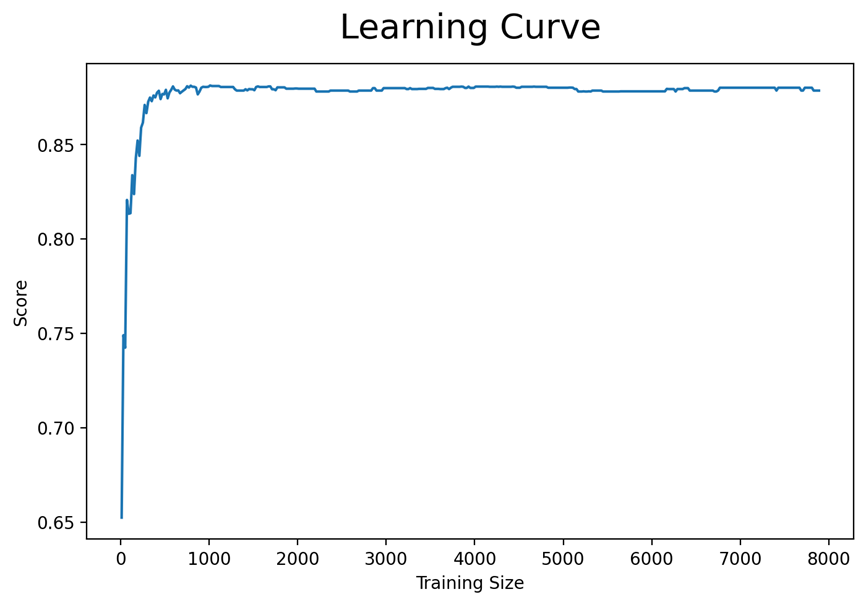
위 그래프를 보면 약 1000건의 데이터 이후로는 성능이 오르지 않습니다. 즉, 대량의 데이터를 학습 시킨다고 머신러닝의 성능이 좋아지는 것이 아니라 데이터의 질이 중요하다는 것을 알 수 있습니다.
▶VIF
타겟을 제외한 종속변수들을 가지고 각 각 상관계수를 찾아서 높은 상관계수가 나온 변수들을 제외하고 머신러닝에 학습합니다. 하지만 무조건 상관계수가 높게 나왔다는 이유만으로 배제를 하면 안됩니다. 상관계수가 높게 나왔다는 것은 한 독립변수를 다른 독립변수들이 얼마나 잘 설명해주냐는 것인데 이를 기반으로 해당 독립변수가 없어도 된다고 생각해서 없애는 작업이 VIF입니다. 다만 위에 말했던 것처럼 무조건 없앤다고 더 좋은 성능의 모델이 만들어지는 것은 아니므로 이런 방법도 있구나라고 생각하면 좋습니다.
▶규제(Regularization)
선형회귀는 변수가 많으면 머신러닝의 성능이 떨어집니다. 이런 상황을 해결하기 위해 가중치 크기를 제어해야 합니다.
Ridge는 변수들의 가중치 크기를 제어합니다.
Lasso는 중요하지 않은 변수들의 가중치를 0으로 바꿀수 있습니다.
ElasticNet는 Ridge와 Lasso의 기능을 함께 사용할 수 있습니다.
최근접이웃(K-Nearest Neighbor)
K-최근접 이웃이라고도 하면 회귀와 분류에 사용되는 지도학습 알고리즘입니다. 다른 알고리즘에 비해 간단하지만 연산속도가 느리다는 단점을 가지고 있습니다. KNN을 사용할 때 옵션 값으로 주어지는 k가 있는 k에 따라서 값이 변동되기 때문에 k를 설정해줄 때 주의해주어야 합니다. 만약 k가 너무 커지면 모델이 단순해집니다.
값의 범위가 다를 때 스케일링을 해주어서 값의 범위를 맞춰줍니다. 정규화(스케일링)에 따라 모델 성능이 달라지기 때문에 k값과 정규화가 KNN에서는 매우 중요합니다.
사이킷런에서는 MinMaxScaler를 제공해주어서 해당 패키지를 사용해서 스케일링을 진행할 수 있습니다.
▶정규화(스케일링) 실습
공식을 사용한 정규화 방법을 보겠습니다.
# 최댓값, 최솟값 구하기
x_max = x_train.max()
x_min = x_train.min()
# 정규화
x_train = (x_train - x_min)/(x_max - x_min)
x_test = (x_test - x_min)/(x_max - x_min)
함수를 사용한 정규화 방법을 보겠습니다.
# 모듈 불러오기
from sklearn.preprocessing import MinMaxScaler
# 정규화
scaler = MinMaxScaler()
scaler.fit(x_train)
x_train = scaler.transform(x_train)
x_test = scaler.transform(x_test)단 함수를 사용하면 배열로 데이터 타입으로 바뀌게 됩니다. 그래서 아래와 같은 방식으로 다시 데이터프레임으로 유지해줄 수 있습니다.
# 모듈 불러오기
from sklearn.preprocessing import MinMaxScaler
# 정규화
x_col = list(x)
scaler = MinMaxScaler()
scaler.fit(x_train)
x_train = scaler.transform(x_train)
x_test = scaler.transform(x_test)
#추후를 대비해서 데이터프레임으로 다시 변환함
x_train = pd.DataFrame(x_train, columns=x_col)
x_test = pd.DataFrame(x_test, columns=x_col)
#확인
x_train.head()▶KNN 사용 실습
KNN사용 실습을 보겠습니다.
# 1단계: 불러오기
from sklearn.neighbors import KNeighborsRegressor
from sklearn.metrics import mean_absolute_error, r2_score
# 2단계: 선언하기
model = KNeighborsRegressor(n_neighbors=3)
#n_neighbors가 k값입니다. 아무 옵션값을 안주면 5로 디폴드 값입니다
# 3단계: 학습하기
model.fit(x_train, y_train)
# 4단계 예측하기
y_pred = model.predict(x_test)
# 5단계: 평가하기
print(mean_absolute_error(y_test, y_pred))
print(r2_score(y_test, y_pred))
결정트리(Dession Tree )
특정 변수에 대한 의사결정 규칙을 나무가지처럼 뻗어가는 분류방법입니다. 직관적이고 이해하기 쉽다는 장점이 있습니다. 단, 의미 있는 질문을 처음에 해서 분류를 하는 것이 중요합니다.
불순도를 줄이는 방법으로 가지를 뻗쳐나갑니다. 불순도에는 지니불순도와 엔트로피가 있습니다.
결정트리의 핵심 로직은 어떤 변수에 관해 질문했을 때 불순도가 낮게 나오는지 찾아서 질문해 나가는 것입니다.
정보이득이 크다는 것은 어떤 속성으로 분할할 때 불순도가 줄어드는 것을 의미합니다. 정보이득을 크게하는 방향으로 결정트리는 분기합니다.
max_depth옵션을 사용하면 일정량 이상 질문을 하지 못하도록 제한을 걸어둬서 과대적합과 일반화를 막아줄 수 있습니다. 학습데이터에 대한 성능은 떨어지지만 평가데이터에 대한 성능을 올릴 수 있기 때문에 적절한 max_depth 옵션 값을 찾아서 설정해주면 됩니다.
Dession Tree, 결정트리 분류모델도 결국 확률에 근거해서 예측을 합니다.
결정트리의 시각화 방법이 여러가지 있지만 그 중에 graphize방식을 사용하면 결정트리의 시각화를 확인할 수 있습니다.
▶결정트리 사용 실습
결정트리는 아래와 같이 사용할 수 있습니다. 아래의 방법은 분류모델을 만드는 것입니다.
# 1단계: 불러오기
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import confusion_matrix, classification_report
# 2단계: 선언하기
model = DecisionTreeClassifier(max_depth = 5, random_state=1)
#정보이득이 높은 것을 변수로 선택해서 분개하는데 만약 같은것이 있다면 랜덤으로 돌리기 때문에
#random_state 옵션을 쓰면 다른사람과 같은 결과를 볼 수 있다.
# 3단계: 학습하기
model.fit(x_train, y_train)
# 4단계: 예측하기
y_pred = model.predict(x_test)
# 5단계 평가하기
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))변수 중요도의 시각화는 아래와 같습니다.
# 변수 중요도
plt.figure(figsize=(5, 5))
plt.barh(list(x), model.feature_importances_)
plt.show()
.importance_를 사용하면 변수의 중요도를 알 수 있습니다.
※최근접 이웃도 그렇고 결정트리도 그렇고 모델이 복잡하다 단순하다는 설명을 했는데 모델이 복잡하다라는 의미는 깊이 있게 학습한다라는 의미로 좋은 것이 아니라 과대적합이 발생할 수 있다는 것을 의미합니다.
오늘은 머신러닝의 분류와 회귀에 대한 알고리즘에 대해 배웠습니다.
※공부하고 있어 다소 틀린점이 있을 수 있습니다. 언제든지 말해주시면 수정하도록 하겠습니다.
※용어에 대해 조금 공부 더 해서 수정하겠습니다.
