오늘은 미니프로젝트(2) 2일차로 row데이터처리와 데이터분석, 모델링까지 진행했습니다.
실습
오늘은 row데이터부터 시작해서 모델링까지 프로젝트를 진행했습니다. HTML코드의 데이터를 BeautifulSoup을 통해 데이터를 처리해서 모델링 전 데이터로 가공하는 법을 익혔습니다.
Row 데이터 처리
먼저 BeautifulSoup 패키지를 불러옵니다.
from bs4 import BeautifulSoup다음으로 row데이터를 BeautifulSoup을 통해 변환해보겠습니다.
soup = BeautifulSoup(데이터프레임['컬럼명'][0], 'html.parser')html.parser을 통해 데이터를 파싱해줍니다. 원래는 반복문을 돌려서 데이터 하나 하나에 접근해봐야했지만 실습 시간 부족으로 다음으로 미뤘습니다.
▶태그의 길이를 계산
데이터 파싱이 끝났다면 태그의 길이를 구하는 코드는 아래와 같습니다.
soup = BeautifulSoup(데이터프레임['컬럼명'][0], 'html.parser')
print('script 길이 : ',len(str(soup.head.script.getText())))▶특정 태그를 찾기
res = soup.find_all('body')해당 코드는 body의 태그를 찾는 코드입니다.
▶특정 태그에 속성이 있어 해당 속성을 가지는 태그 찾기
soup.findAll('컬럼명',{"속성이름:True"})딕셔너리 형태이므로 여러개의 속성을 사용해줄 수 있습니다.
데이터 분석 및 전처리
▶단변량 분석
저는 단변량의 분석 같은 경우 아래와 같이 진행합니다.
plt.figure(figsize=(8,5))
plt.subplots(constrained_layout=True)
plt.subplot(2,1,1)
sns.histplot(데이터프레임['컬럼명'])
plt.subplot(2,1,2)
sns.boxplot(데이터프레임['컬럼명'])
plt.show()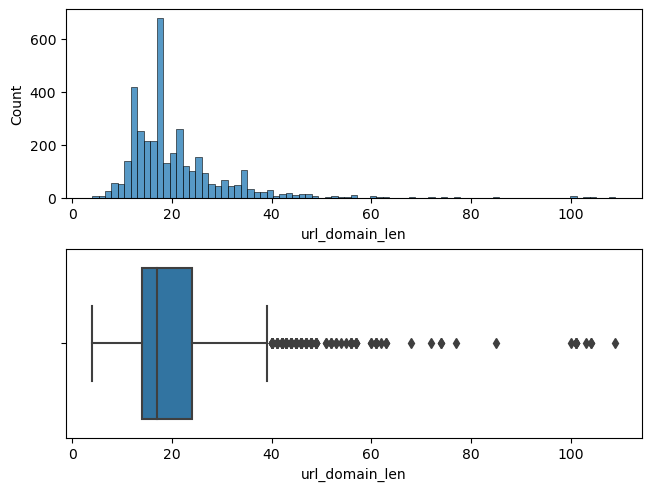
위와 같이 histplot과 boxplot으로 단변량 분석을 합니다.
▶이변량 분석
plt.figure(figsize=(14,8))
sns.heatmap(데이터프레임.corr(), cmap='Greens', annot=True, fmt='.2f')
plt.show() 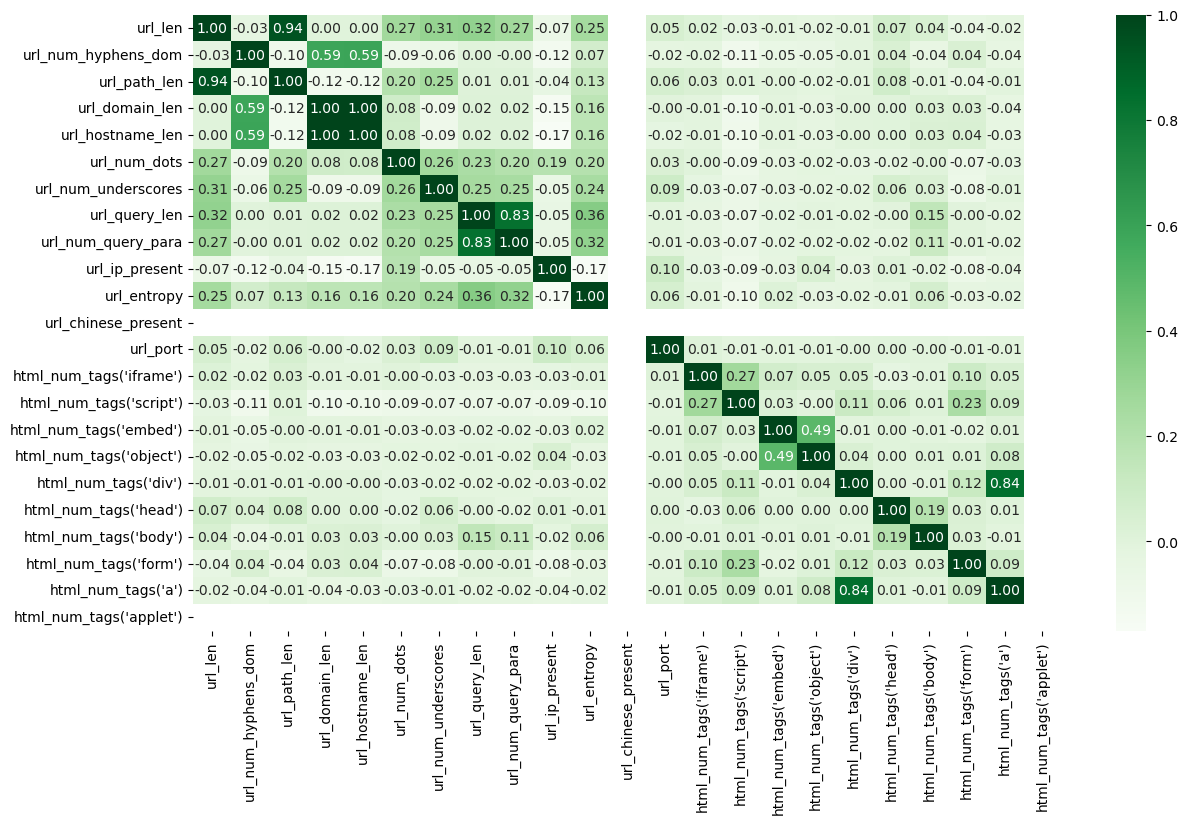
.corr를 사용하면 수치변수들의 상관계수를 알 수 있습니다.
▶중복데이터 제거
중복 데이터가 있는 경우 중복 데이터를 제거하는 코드는 아래와 같습니다.
데이터프레임 = 데이터프레임.drop_duplicates()▶데이터 탐색을 통한 변수 제거
데이터의 변수를 제거하는 방법에는 여러가지 방안이 있고 꼭 데이터를 제거한다고 해서 모델의 성능이 향상된다는 보장은 없습니다. 모델 성능향상의 방안중 하나이므로 한번 시도하는 것이 좋습니다. 따라서 변수 제거를 할만한 변수들의 선별 과정을 알아보겠습니다. 물론 이 과정도 득이 될 수도 독이 될 수도 있습니다.
저는 먼저 위의 히트맵을 그리고 확인을 했습니다. 만약 변수들끼리의 상관계수가 크다면 해당 변수끼리는 서로 연관성이 커서 한 변수가 다른 변수를 설명을 잘해준다고 판단해서 지웠습니다.
이런식으로 상관계수를 살펴보아 지울 수 있는 변수는 지웠습니다.
다음 방법으로는 변수의 중요도에 따라 중요도가 현저히 낮은 변수를 지워주는 과정을 걸쳤습니다. 저는 모델링이 끝나고 변수의 중요도를 확인합니다.
plt.barh(list(x_train), model.feature_importances_)
plt.show()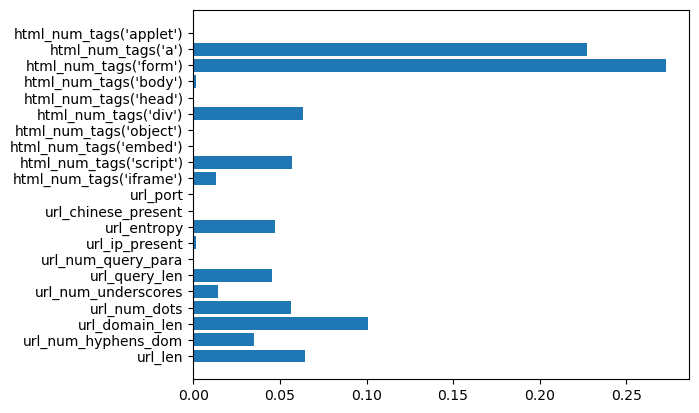
이렇게 변수의 중요도를 확인한 후 변수의 중요도가 현저히 낮다면 한번 제거하는 것도 좋은 방법이라고 생각합니다.
모델링
모델링은 어제와 크게 차이가 없지만 GridSearch를 진행했을 때 저는 LGBMClassifier()을 사용했습니다. 해당 알고리즘을 사용했을 때 하이퍼파라미터로 max_depth, num_leaves를 같이 튜닝하면 좋다는 것을 보고 같이 튜닝을 진행했습니다.
model_lg = LGBMClassifier()
param = {'max_depth' : range(1,11), 'num_leaves' : range(70,90)}
model = GridSearchCV(model_lg, param, cv = 15)num_leaves는 더 자세히 공부한 후에 포스팅을 추가하겠습니다.
기타
csv파일을 불러올 때 인덱스를 지정해주는 방법으로는 index_col=0이 있습니다.
x_train = pd.read_csv('./x_train.csv', index_col=0)와 같은 방법으로 사용됩니다.
항상 미니프로젝트마다 뭔가 새로운 것 같은 느낌을 받아 당황하는 나날입니다. 얼른 적응해서 더 숙달될 수 있도록 노력하겠습니다. 튜닝을 하면서 모델이 좋아지는 것을 볼 때마다 뿌듯함을 느낍니다.
※공부하고 있어 다소 틀린점이 있을 수 있습니다. 언제든지 말해주시면 수정하도록 하겠습니다.
※용어에 대해 조금 공부 더 해서 수정하겠습니다.
