자연어처리 NLP의 4일차 프로젝트를 진행했습니다.
Pycaret
어제에 이어 오늘 모델링을 더 진행했습니다. 오늘은 AutoML을 사용해서 모델링을 진행했습니다.
AutoML중에 Pycaret을 사용하여 진행했으며 간단하게 코드를 작성하겠습니다.
▶pip install
먼저 Pycaretㅇㄹ 사용하기 위해 모듈을 다운받아줍니다.
!pip install pycaret[full]
!pip install markupsafe==2.0.1여기서 pycaret[full]을 해주어야만 catboost등의 모든 모델을 자동학습해줍니다.
주의할 점은 이렇게 모듈을 다운받았다면 꼭 런타임 다시 시작을 눌러서 런타임을 재실행 해주어야합니다.
▶분류모델을 위한 패키지 import
분류 모델링을 위해서 필요한 함수와 패키지를 아래의 코드를 통해 import를 진행합니다.
from pycaret.classification import *▶모델 준비
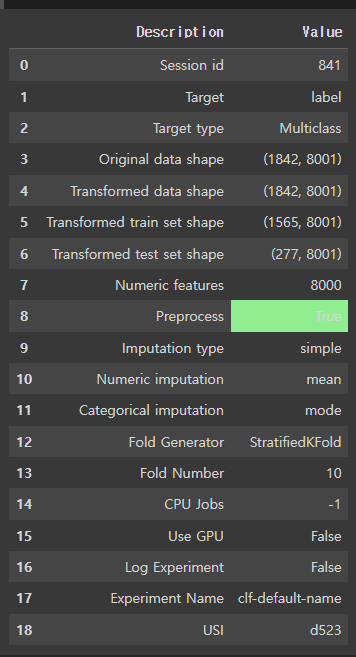
exp = setup(data=train_data, target='label', train_size=0.85)모델 데이터는 train_data고 타겟은 label컬럼을 가지고 타겟으로 잡습니다. 위 코드를 실행하면 아래와 같은 결과를 얻을 수 있습니다.
▶모델링 시작
best_5 = compare_models(sort='Accuracy', n_select=5, exclude=['catboost'])#상위 5개 모델해당 코드를 보면 catboost를 뺀 나머지 ML에 대해서 자동 학습을 진행해줍니다. 물론 순서는 Accuracy에 순위에 맞춰 상위 5개의 모델을 best_5의 리스트 형태로 저장하게 됩니다. 따라서 접근할 때, best_5[0] 이런식으로 사용하면 상위 첫 번째 모델을 가져와서 학습하거나 튜닝이 가능합니다.
▶튜닝
이번 미니프로젝트에서는 안 사용했지만 Pycaret을 사용하면 자동 튜닝도 가능합니다.
tuned_model = tune_model(best_5[1]) # 상위 5개 모델 중 두 번째 모델 튜닝이런식으로 자동 튜닝도 사용할 수 있습니다.
▶테스트 셋 전처리
만약 setup함수에서 옵션으로 전처리를 진행했다면 test셋에도 같은 전처리를 적용하기 위해 아래와 같이 코드를 작성하면 됩니다.
pipeline = get_config('pipeline')
test_auto_preprocessed = pipeline.transform(test_auto)추가 코드
csv 파일로 저장하기 위해 아래 코드를 사용했습니다.
x_pr_val_df = pd.DataFrame(x_pr_val)
val_y_df = pd.DataFrame(val_y)
train_data.to_csv(PATH+'train_data.csv', index=False)
train_y_df.to_csv(PATH+'train_y_df.csv', index=False)
x_pr_train_df.to_csv(PATH+'x_pr_train_df.csv', index=False)
x_pr_val_df.to_csv(PATH+'x_pr_val_df.csv', index=False)
val_y_df.to_csv(PATH+'val_y_df.csv', index=False)전처리가 아직 부족한지 낮은 성능을 보이기 때문에 내일 한번 더 전처리를 할 예정입니다.
※공부하고 있어 다소 틀린점이 있을 수 있습니다. 언제든지 말해주시면 수정하도록 하겠습니다.
※용어에 대해 조금 공부 더 해서 수정하겠습니다.
