오늘은 미니프로젝트6 1일차로 자연어처리 프로젝트를 진행했습니다.
실습 내용
오늘부터 또 새롭게 미니푸로젝트가 들어갔습니다. 오늘은 자연어처리를 활용한 챗봇 만들기였습니다.
주어진 데이터를 활용해서 자동으로 답변해주는 모델을 만드는 것이 오늘 목표였습니다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import joblib
import warnings
warnings.filterwarnings("ignore", category=DeprecationWarning)
# 필요하다고 판단되는 라이브러리를 추가하세요.
import os
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier
from sklearn.metrics import *
import tensorflow as tf
from keras.layers import Dense, Embedding, Bidirectional, LSTM, Concatenate, Dropout
from keras import Input, Model
from keras import optimizers
from keras.models import Sequential, load_model
from keras.callbacks import EarlyStopping, ModelCheckpoint
from gensim.models import Word2Vec
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from sklearn.metrics.pairwise import cosine_similarity
먼저 필요 패키지를 불러옵니다.
from konlpy.tag import Okt, Komoran, Mecab, Hannanum, Kkma
# 다양한 토크나이저를 사용할 수 있는 함수
def get_tokenizer(tokenizer_name):
if tokenizer_name == "komoran":
tokenizer = Komoran()
elif tokenizer_name == "okt":
tokenizer = Okt()
elif tokenizer_name == "mecab":
tokenizer = Mecab()
elif tokenizer_name == "hannanum":
tokenizer = Hannanum()
else:
# "kkma":
tokenizer = Kkma()
return tokenizer
# 형태소 분석을 수행하는 함수
def tokenize(tokenizer_name, original_sent, nouns=False):
# 미리 정의된 몇 가지 tokenizer 중 하나를 선택
tokenizer = get_tokenizer(tokenizer_name)
# tokenizer를 이용하여 original_sent를 토큰화하여 tokenized_sent에 저장하고, 이를 반환합니다.
sentence = original_sent.replace('\n', '').strip()
if nouns:
# tokenizer.nouns(sentence) -> 명사만 추출
tokens = tokenizer.nouns(sentence)
else:
tokens = tokenizer.morphs(sentence)
tokenized_sent = ' '.join(tokens)
return tokenized_sent 형태소 분석에 사용할 함수를 호출합니다.
데이터를 불러왔다고 가정 후에 형태소 분석을 아래와 같이 진행합니다.
train_df['Q'] = train_df['Q'].apply(lambda x : tokenize(get_tokenizer('mecab'), x))
test_df['Q'] = test_df['Q'].apply(lambda x : tokenize(get_tokenizer('mecab'), x))결과를 보면 형태소 분석이 된 것을 확인할 수 있습니다.
from gensim.models import Word2Vec
# Word2Vec 모델 생성
wv_model = Word2Vec(sentences=train_df['Q'], size=100, window=5, min_count=5, workers=4, sg=1)
#wv_model = Word2Vec(sentences=test_df['Q'], size=100, window=5, min_count=5, workers=4, sg=1)w2v을 진행해줍니다.
# Word2Vec 모델로부터 하나의 문장을 벡터화 시키는 함수
def get_sent_embedding(model, embedding_size, tokenized_words):
# 임베딩 벡터를 0으로 초기화
feature_vec = np.zeros((embedding_size,), dtype='float32')
# 단어 개수 초기화
n_words = 0
# 모델 단어 집합 생성
index2word_set = set(model.wv.index2word)
# 문장의 단어들을 하나씩 반복
for word in tokenized_words:
# 모델 단어 집합에 해당하는 단어일 경우에만
if word in index2word_set:
# 단어 개수 1 증가
n_words += 1
# 임베딩 벡터에 해당 단어의 벡터를 더함
feature_vec = np.add(feature_vec, model[word])
# 단어 개수가 0보다 큰 경우 벡터를 단어 개수로 나눠줌 (평균 임베딩 벡터 계산)
if (n_words > 0):
feature_vec = np.divide(feature_vec, n_words)
return feature_vec
# 문장벡터 데이터 셋 만들기
def get_dataset(sentences, model, num_features):
dataset = list()
# 각 문장을 벡터화해서 리스트에 저장
for sent in sentences:
dataset.append(get_sent_embedding(model, num_features, sent))
# 리스트를 numpy 배열로 변환하여 반환
sent_embedding_vectors = np.stack(dataset)
return sent_embedding_vectors다음으로 문장 벡터를 만들어주는 함수들을 만들어준 후 학습데이터를 가지고 Word2Vec모델을 사용해서 벡터화를 진행해줍니다.
# 학습 데이터의 문장들을 Word2Vec 모델을 사용하여 벡터화
train_data_vecs = get_dataset(train_df['Q'], wv_model, 100)
test_data_vecs = get_dataset(test_df['Q'], wv_model, 100)이제 해당 데이터로 모델링을 진행하겠습니다.
X = train_data_vecs
y = train_df['intent']
# X와 y 데이터 분리
from sklearn.model_selection import train_test_split
# Train-Test split
x_train, x_test, y_train, y_test = train_test_split(X, y, random_state=42, test_size=0.2)
from lightgbm import LGBMClassifier
model = LGBMClassifier()
model.fit(x_train, y_train)
y_pred = model.predict(x_test)
y_pred이렇게 간단하게 모델링을 진행하였고 이제 챗봇을 구축해서 진행하겠습니다.
a = input()
a = [tokenize(get_tokenizer('mecab'), a)]
# 토큰화된 데이터를 입력으로 사용하여 Word2Vec 모델 학습
wv_model = Word2Vec(a, size=100, window=5, min_count=1, workers=4, sg=1)
# 학습된 Word2Vec 모델을 사용하여 데이터셋 구성
inputQuestion = get_dataset(a, wv_model, 100)
이렇게 이제 문장 하나를 입력받고 전처리를 하는 코드를 작성합니다.
import random
predicted_intent = model.predict(inputQuestion)
# 예측된 intent에 해당하는 답변들의 리스트 가져오기
response_options = train_df[train_df['intent'] == predicted_intent[0]]['A'].tolist()
# 답변들 중에서 랜덤하게 하나 선택
response = random.choice(response_options)
print("답변:", response)이제 해당 코드를 통해 답변을 해주는 챗봇이 완성이 됩니다.
문제점
위와 같이 진행했더니 모델링을 너무 간단하게 해서 그런가 accuracy가 0.4 정도로 매우 낮게 측정이 되었습니다.
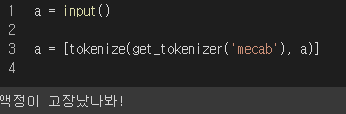
액정이 고장났다고 말하니...

액정이 고장난 고민을 한다고 생각하는지 고민은 누구나 한다고 답변이 옵니다...ㅎㅎ
문의 내용에 따른 답장을 해주는 챗봇 만들기를 진행했습니다. 간단한 모델로 진행해서 그런지 만족스럽지 않은 성능이였습니다.
※공부하고 있어 다소 틀린점이 있을 수 있습니다. 언제든지 말해주시면 수정하도록 하겠습니다.
※용어에 대해 조금 공부 더 해서 수정하겠습니다.

개발자가 되기 위한 한걸음