오늘은 미니프로젝트6 3일차로 머신러닝을 새롭게 진행했습니다.
실습 내용
어제까지는 자연어처리를 진행했지만 오늘부터는 시계열 데이터의 머신러닝을 진행했습니다.
실습 코드
오늘 진행한 데이터는 시계열 데이터입니다. 시간에 따른 타겟값을 예측하는 문제를 진행했습니다.
data.rename(columns={'컬럼명1' : '컬럼명바뀜1'}, inplace=True)rename을 통해 컬럼명을 변경해줄 수 있습니다. 한글 컬럼명 사용시 오류가 출력될 수 있으므로 이를 방지하고자 영어 컬럼을로 바꾸어줍니다.
data['날짜데이터컬럼'] = pd.to_datetime(data['날짜데이터컬럼'])해당 코드를 사용해주면 자료형태를 날짜형태로 바꾸어줄 수 있습니다.
data['Day'] = data['날짜데이터컬럼'].dt.day_name()
data['Week'] = (data['날짜데이터컬럼'].dt.day-1) // 7 + 1
data['Month'] = data['날짜데이터컬럼'].dt.month
data['Year'] = data['날짜데이터컬럼'].dt.year데이터형태로 바꾸어주면 dt를 통해 다양한 데이터 조작을 사용하여 년, 월, 일을 출력할 수 있습니다.
여기서 Week 컬럼을 만들어주는 부분을 보게되면 여러 처리가 된 것을 볼 수 있는데 해당 처리는 각 월 별로 주차를 나타낸 것입니다. 그냥 dt.week를 사용하면 년에 따른 주차가 나오기 때문에 해당 작업을 해주면 1,2,3,4,5주차로 나눠지는 것을 확인할 수 있습니다.
total_data['target'] = total_data['타겟으로하고자하는컬럼'].shift(-1)해당 코드를 작성해주면 타겟으로하고자하는컬럼이 한칸씩 위로 올라가서 target컬럼에 작성됨으로 미래 시점이 타겟값으로 설정이 되는 것입니다. 즉 현재시점을 t라고 하면 target은 t+1이 되는 것입니다.
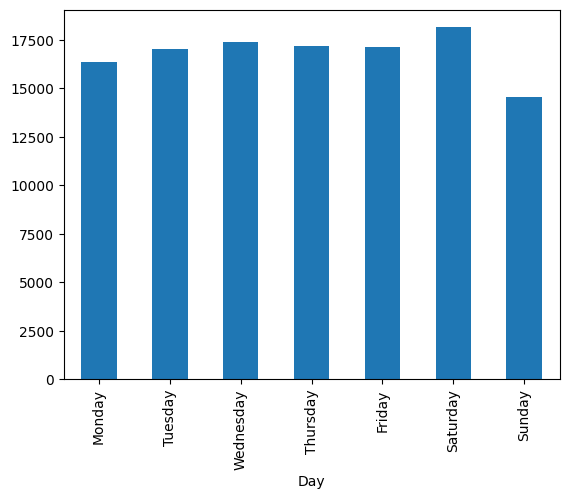
total_data['Day'] = pd.Categorical(total_data['Day'], categories=['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday'], ordered=True)해당 코드를 작성해주면 Categorical하게 설정이 되며 시각화를 진행하면 value의 값에 상관없게 설정한 순으로 출력이 가능해집니다.
from workalendar.asia import SouthKorea해당 패키지를 사용하면 한국의 공휴일 출력이 가능해집니다.
cal = SouthKorea()
holidays_data = pd.concat([pd.DataFrame(cal.holidays(year)) for year in range(2015, 2023)])이런식으로 사용한다면 2015-2022년도까지의 공휴일을 가져올 수 있습니다.
나머지 코드는 늘 진행하는 모델링과 라벨링이므로 굳이 포스팅하지 않고 전처리 위주로 포스팅했습니다.
※공부하고 있어 다소 틀린점이 있을 수 있습니다. 언제든지 말해주시면 수정하도록 하겠습니다.
※용어에 대해 조금 공부 더 해서 수정하겠습니다.
