오늘은 Flask사용과 MongoDB연동을 진행했습니다.
MongoDB
MongoDB의 IDE중 하나인 Studio 3T를 사용했고 접속한 후에 IntellShell을 누르면 MySQL과 같이 작성을 할 수 있는 코드창이 하나 나옵니다.
use mongo;
db;
show dbs;
db.user.insert({name:'andy', age:29, email:'andy@gmail.com'});
위와같이 js 기반으로 코드를 작성할 수 있습니다. use mongo는 mongo DB를 사용하겠다는 것이고 db.user.insert({name:'andy', age:29, email:'andy@gmail.com'}); 는 DB에 user이라는 컬렉션을 만들고 해당 데이터를 삽입합니다.
show collections;DB에 있는 컬렉션들을 보여줍니다.
db.createCollection('test')test라는 컬렉션이 생깁니다.
db.createCollection('info1', {capped=True, size: 500, max:5})capped가 True로 설정이 되면 최대 용량, 최대 document 설정이 다능합니다. size는 용량이고 byte단위를 가집니다. 최소용량은 4096이라 위에 500이라고 설정해도 4096byte가 설정됩니다. max는 최대 document를 설정합니다.
db.startup_log.drop();해당 startup_log라는 컬렉션을 삭제합니다.
DB는 CRUD를 기반으로 관리하면 좋습니다.
C는 Create의 앞글자로 아래와 같이 insert()를 사용해서 데이터를 추가합니다.
db.info1.insert([
{subject: 'python', level:1},
{subject: 'css', level:2},
{subject: 'html', level:3},
{subject: 'web', level:4},
{subject: 'Django', level:5},
{subject: 'ML', level:6},
{subject: 'java', level:7},
{subject: 'nginx', level:8},
]);R은 Read의 앞글자로 find()를 사용해서 데이터를 읽습니다.
db.info1.find();데이터를 읽어올때 앞에 max:5 로 설정해줘서 과거의 데이터는 지워지고 신식 데이터만 채워져서 아래와 같은 결과가 나옵니다.
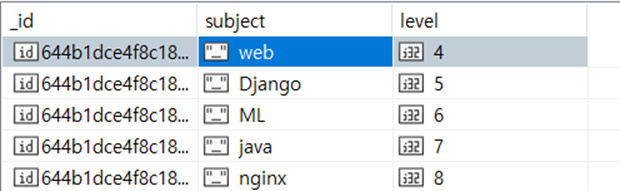
python, css html의 자료는 없는 것을 알 수 있습니다.
db.info.find({level: {$gte: 4}});는 level이 4 이상인 데이터들을 보여주고 gte는 greter than equal의 약자입니다.
db.info.find({subject: {$in: ['java', 'nginx']}});해당 코드를 사용하면 subject 컬럼이 java와 nginx인 값을 불러옵니다.
db.info.find({$and: [{subject:'nginx'}, {level: {$gt:5}}]});이렇게 논리 연산자로 사용가능합니다. 형태가 제가 알던 논리연산자와는 다르게 사용되는 것을 볼 수 있습니다.
db.user.find({}, {name:true, age:true});를 사용하면 원하는 컬럼만 가져와서 볼 수 있습니다. 앞에 {}는 전체데이터를 보여줍니다.
age만 제외하고 출력이 가능합니다.
db.user.find({}, {age:false});
db.user.find({}, {_id:false, name:true, age:true});이렇게 작성해주면 id값은 출력이 안됩니다. _id컬럼은 항상 출력이 됩니다.
단, _id를 제외하고서는 false와 true는 혼합해서 사용하면 안됩니다.
db.info.find().sort({level: 1});이라고 작성을 해주면 level 컬럼 기준으로 오름차순 정렬이 됩니다.
db.info.find().sort({level: -1});반대로 -1을 옵션 값으로 주면 내림차순 정렬이 됩니다.
limi()을 사용하면 출력 갯수가 제한이 가능합니다.
db.info.find().sort({level: -1}).limit(3); db.info.find({level:{$lte: 5}}).sort({level: -1}).limit(3);이런식으로 find에 조건을 걸어 혼합해서 사용이 가능합니다.
데이터를 스킵해서 출력하는 방법은 skip()을 사용합니다.
db.info.find({level:{$lte: 8}}).sort({level: -1}).skip(4);데이터를 4개를 생략하고 보여줍니다.
D는 Delete의 앞글자로 remove()를 사용합니다.
db.info1.remove({level:3});를 사용하면 에러가 발생합니다 이유는 capped:true 옵션을 걸어준 db에 대해서는 수정, 삭제가 불가능함으로 해당 옵션이 없는 db에서는 위와 같이 작성하면 삭제가 가능합니다.
U는 Update의 앞글자로 update()를 사용합니다.
db.info.update({subject:'python'}, {$set:{level:5}});document 1개만 수정합니다.
db.info.update({subject:'python'}, {$set:{level:5}}, {multi: true});이렇게 multi 옵션을 주면 모든 subject 컬럼값이 python인 데이터들에 대해 level을 5로 바꿔줍니다.
var pagenation= function(page, pageblock){
return db.info.find().skip((page-1)*pageblock).limit(pageblock)
};
pagenation(2,3)이런식으로 함수도 만들어서 사용이 가능합니다.
pymongo
!pip install pymongo
쥬피터 노트북에 pymongo를 설치해줍니다. (원격 컴퓨터에서 쥬피터 노트북을 진행했습니다.)
pymongo는 python에서 사용할 수 있도록 도와주는 패키지이며 connect server와 connect database, connect collection이 가능합니다. 그러면 document의 CRUD로 db관리가 가능합니다.
import pymongo
import pandas as pd먼저 pymongo 패키지를 불러옵니다.
client = pymongo.MongoClient('mongodb://kt:ktpw@15.165.19.207:27017')
list(client.list_databases())출력이 된다면 데이터 서버에 접속이 잘 된것입니다.
db = client.mongo
dbdb라는 변수에 mongo와 연결된 클라이언트를 넣어줍니다.
list(db.list_collection_names())db의 콜렉션 이름들을 확인할 수 있습니다.
..3교시 수업 다시보고 정리...
json_data = data.to_dict('records')datat.to_dict를 사용하면 dataframe을 list안에 dictionary가 있는 형태로 변환해줍니다.
pymongo도 마찬가지로 CRUD를 활용해 데이터를 관리할 수 있습니다.
collection = db.info
document = collection.find_one({'subject': 'python'})
documentsubject가 python인 데이터를 가져옵니다.
documents = collection.find({'subject': 'python'})
data = list(documents)
datasubject가 python인 모든 데이터를 리스트 형태로 data라는 변수에 저장합니다.
collection = db.info
documents = collection.find({'level': {'$gte': 5}}).sort('level', pymongo.DESCENDING)
pd.DataFrame(list(documents))level의 컬럼이 5이상이 값을 sort정렬을 해서 DataFrame 형태로 만들어서 출력합니다.
# insert many data
data = [
{'subject': 'webpack', 'level': 7},
{'subject': 'java', 'level': 6},
]
result = collection.insert_many(data)
print(result.inserted_ids)
해당 조건에 맞는 데이터의 ids값을 출력해서 보여줍니다.
collection.update_many({'subject': 'webpack'}, {'$set': {'level': 9}})webpack이란 값을 가진 모든 데이터들의 level의 값을 9로 업데트해줍니다.
collection.delete_many({'level': {'$gte': 7}})level의 값이 7 이상인 데이터들을 모두 지워줍니다.
flask
파이썬 언어로 WAS를 개발하는 프레임워크입니다. 빠르고 쉽게 WAS를 개발할 수 있도록 해줍니다.
!mkdir -p hello/static
!mkdir -p hello/templates
!touch hello/hello.py
!touch hello/templates/index.html
!tree hello작업환경은 원격 컴퓨팅된 서버의 쥬피터로 위와 같이 작성해줍니다.
해당 작업을 통해 flask 틀을 만들어줍니다.
hello.py는 flask의 app 객체를 생성하는 route입니다.
static은 정적파일들을 저장합니다. (js, hrml, css 등등)
templates는 주로 html파일을 저장합니다.
%%writefile hello/hello.py
from flask import *
app = Flask(__name__)
app = Flask(__name__)
@app.route('/')
def index():
return 'hello Flask!!'
app.run(debug=True, port=5000)다음으로는 route 모듈 파일을 만들어줍니다. %%writefile hello/hello.py 를 작성해주면 밑에 작성한 코드가 작성됩니다.
먼저 flask 패키지에서 모든 클레스를 호출합니다.
@app을 사용함으로 데코레이터가 가능합니다. 데코레이터는 함수안에서 공통의 기능을 빼와서 사용할수 있는 것 입니다.
%cat hello/hello.py파일의 내용을 보고 싶으면 리눅스에서 사용하던 cat 명령어를 사용해서 보면 됩니다.
!python hello/hello.py코드를 통해 이제 Flask를 실행해주고 ip주소:8080을 입력하면 Hello Flask!!가 찍힌 화면을 볼 수 있습니다.
오늘은 Flask와 MongoDB또 python으로 MongoDB관리를 도와주는 패키지 pymongo에 대해 배웠습니다. 강사님께서 협업에서 어떤식으로 한다라고 알려주시고 지금은 이런게 있다 흐름을 알아두는게 나중에 도움이 된다고 말해주셔서 기대를 가지고 많이 배웠습니다. 훗날 도움이 많이 되면 좋겠습니다.
※공부하고 있어 다소 틀린점이 있을 수 있습니다. 언제든지 말해주시면 수정하도록 하겠습니다.
※용어에 대해 조금 공부 더 해서 수정하겠습니다.
