9일차는 전날에 이어 이변량분석 도구들과 데이터를 어떻게 분석하는지에 대해 배웠습니다.
데이터 분석
데이터를 파악할 때 통계량을 내서 요약을 보고 파악하거나 시각화해서 눈으로 파악하는 방법이 있습니다. 이런 과정을 통해 내가 비지니스이 이해 단계에서 세운 가설이 맞는지를 확인합니다.
x->y 가설을 세웠을 때, x는 정보이고 y는 우리가 해결해야되는 목표(타겟)입니다. 예를들어 타이타닉의 데이터를 가지고 분석할 때 생존여부를 확인하기 위해 여러 특징(정보)과 생존여부를 y 즉, 타겟 값으로 잡고 분석하기도 합니다.
정보를 가지고 이제 원본식별을 합니다. 그리고 분석 가능한 정보로 가공합니다. 가공이 끝나면 가설확인을 합니다.
EDA, CDA를 시행합니다. 개별 변수 확인, 가설 확인, x1 vs x2확인을 진행합니다. 이를 통해 분포를 파악하고 통게량을 구해냅니다.
p_value가 만약 0.05본다 작은 값이 나왔다면 상관계수가 유의미하다는 뜻입니다. 그러면 해당 변수들이 관계가 있다는 것 입니다. 예를들어 범죄율이 집 값의 차이에 관계가 있다는 가설을 세우고 가설확인을 통해 상관계수가 유의미하다고 나오면 범죄율은 집 값과 관련이 있다고 해석할 수 있습니다.
▶통계량에 대한 정리(절대적 기준이 아닙니다.)
통계량의 의미는 두 평균의 차이를 의미합니다.
상관계수 'r'은 0.5보다 크고 1보다 작으면 강한 관계 0.2보다 크고 0.5보다 작으면 약한 관계를 의미합니다.
t통계량은 -2보다 작거나 2보다 크면 관계가 있다고 해석합니다.
f통게량은 2~3보다 크면 관계가 있다고 해석합니다.
※주어진 데이터로만 분석하지 말고 데이터를 만들어서 결과를 도출해 내야 합니다.
두 변수의 관계 분석(이변량 분석)_ 범주->범주
범주 대 범주를 비교할 때는 교차표(crosstab)를 사용합니다.
▶교차표 시각화
crosstab을 사용하면 교차표를 만들 수 있습니다.
환경준비
import pandas as pd
import numpy as np
import random as rd
import matplotlib.pyplot as plt
import seaborn as sns
from statsmodels.graphics.mosaicplot import mosaic #mosaic plot사용준비
import scipy.stats as spst
교차표 만들기
pd.crosstab(데이터프레임명['컬럼명1'], 데이터프레임명['컬럼명2'])
교차표 crosstab에는 옵션이 하나 있습니다. normalize라는 옵션이 있는데 해당 옵션을 사용해주면 crosstab에 표시되는 값을 비율로 변환해서 나타내줍니다. 옵션 값을 columns로 해주면 열 기준으로 100%가 되게 하고 index로 값을 주면 행 기준으로 100% 비율이 됩니다.
▶mosaic plot
범주별 양과 비율을 그래프로 나타내줍니다. 다양한 옵션을 사용할 수 있습니다.
mosaic(데이터프레임명, [ '컬렴명1','컬럼명2'])
plt.axhline(1- 데이터프레임명['컬럼명2'].mean(), color = 'r')
plt.show()
위 코드를 보면 plt.axhline이 있는데 color='r'이라는 옵션을 줘서 주어진 값에 빨간 선을 그어주는 코드입니다.
x축 길이는 컬럼명1별로 컬럼명2 비율을 나타내줍니다.
두 범주형 변수가 만약 아무 상관이 없다면 범주별 비율 차이가 전혀 없는 '믐'같은 모양의 그래프가 나타납니다.
▶수치화에 대해 알아보겠습니다.
범주 대 범주 변수들을 수치화하는 도구로는 카이제곱 검정이 있습니다.
▶카이제곱 검정
기대빈도 : 아무런 기대치가 없을 때 나올 수 있는 값을 칭함(귀무가설이 참일 때 나올 수 있는 값)

카이제곱 통계량은 클수록 기대빈도로부터 실제 값이 크다는 것을 의미합니다. 자유도가 약 2배 보다 크다면 차이가 있다고 봅니다.
※자유도란 범주의 수 -1 입니다. 카이젭곱에서의 자유도 계산은 아래와 같습니다.
(x 변수의 자유도) * (y 변수의 자유도)
카이제곱 검정의 사용 방법은 아래와 같습니다.
# 1) 먼저 교차표 집계
table = pd.crosstab(데이터프레임명['컬럼명1'], 데이터프레임명['컬럼명2'])
#옵션 nomarlize 사용하면 안됨
# 2) 카이제곱검정
spst.chi2_contingency(table)
카이제곱 검정을 사용하여 수치화를 진행할 때는 먼저 교차표를 집계해 주어야 합니다. 그리고 교차표를 만들 때 옵션 nomarlize를 사용해서는 안됩니다.
출력결과는 카이제곱 통계량, p_value, 자유도, 기대빈도순으로 출력됩니다.
두 변수의 괸계 분석(이변량 분석)_숫자 -> 범주
숫자변수와 범주변수의 관계를 시각화 해주는 도구로는 kde plot을 사용해줍니다.
▶kedplot
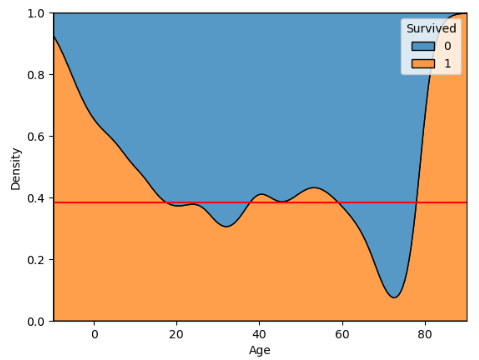
common_norm옵션 값을 False로 설정해주면 각 비교 대상의 kde plot 그래프를 나타낼 때 각각의 값을 1로 설정해서 그래프를 나타내줍니다. multiple = 'fill'로 옵션 값을 설정 해주면 모든 구간에 대한 비율을 100%로 설정하고 kde plot을 그려줍니다.
sns.kdeplot(x='Age', data = titanic, hue ='Survived', multiple = 'fill')
plt.axhline(titanic['Survived'].mean(), color = 'r')
plt.show()
hue 옵션을 사용해서 값으로 컬럼명을 설정해주면 해당 컬럼별로 그래프를 보여줍니다.
예를들어 타이타닉 데이터를 가지고 위 코드처럼 작성하게 되면 생존여부별 나이를 비율 100%로 그래프를 그려서 보여줍니다.
이번 수업에는 이변량 분석의 남은 도구들을 살펴보았습니다. 모든 도구들을 살펴본 것은 아니지만 대표적으로 수치형과 범주형들의 변수들을 분석할 때 사용하는 도구들을 학습했습니다. 남은 실습과 복습문제를 풀면서 복습하겠습니다.
※공부하고 있어 다소 틀린점이 있을 수 있습니다. 언제든지 말해주시면 수정하도록 하겠습니다.
※용어에 대해 조금 공부 더 해서 수정하겠습니다.
