1. 📂 필요한 컬럼만 필터링하여 저장
- 전체 데이터에서 분석에 필요한 25개 주요 컬럼만 추출하여
filtered.csv로 저장. - 이 과정을 통해 불필요한 정보 제거 및 분석 효율 향상.
2. ❗ 결측치 확인 및 제거
.isnull().sum()을 통해 결측치가 있는 컬럼과 개수 확인:
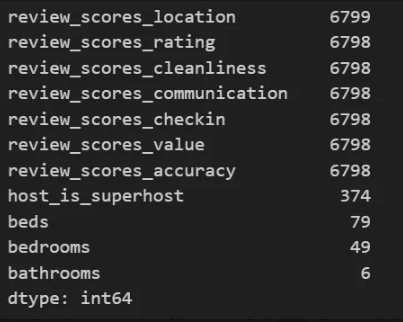
결측치가 존재하는 컬럼 (총 11개)
- 특히
review_scores_시리즈와host_is_superhost,bathrooms,beds,bedrooms등에 결측치 집중. - 이 11개 컬럼에서 결측치가 포함된 행을
dropna()로 삭제하여 분석 정확도를 확보함.
3. 🧮 이상치 탐지 (IQR 방식)
- 수치형 변수에 대해 IQR(사분위 범위) 기준으로 이상치 탐지.
- 각 컬럼의 이상치 개수, 상/하한값 확인하여
outlier_summary에 저장.
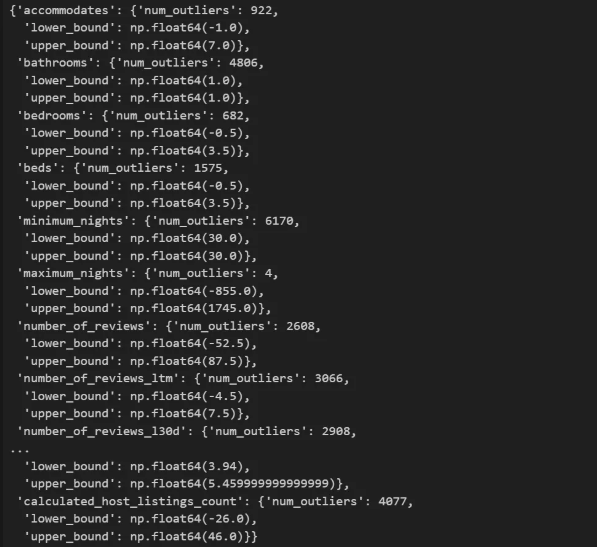
[그림 2] IQR 기반 이상치 탐지 결과 (일부 발췌)
-
예시:
minimum_nights: 이상치 6,170개 (상/하한 = 30.0)bathrooms: 이상치 4,866개 (상한 = 4.0)calculated_host_listings_count: 이상치 4,077개 (상한 = 46.4)
4. 📊 시각화 기반 이상치 판단
boxplot과hist()를 활용하여 이상치 분포 시각화.- 시각적으로 확인 후 제거 기준 수립:
| 변수 | 제거 기준 |
|---|---|
minimum_nights | 200 이상 제거 |
bathrooms | 5 이상 제거 |
accommodates | 17 이상 제거 |
beds | 13 이상 제거 |
bedrooms | 10 이상 제거 |
number_of_reviews | 600 이상 제거 |
review_scores_rating | 0~5 범위 이외 제거 |
calculated_host_listings_count | 7 이상 제거 |
5. 💲가격 데이터 정제
price컬럼에서 달러 기호($) 및 쉼표(,) 제거 후 실수 → 정수형으로 변환 완료.
df['price'] = df['price'].replace('[\$,]', '', regex=True).astype(float).astype(int)6. 🔢 정규화 (Min-Max Scaling)
estimated_occupancy_l365d컬럼은 0~1 범위로 정규화하여 스케일 통일.
7. 🧠 범주형 변수 인코딩
| 컬럼 | 인코딩 방식 |
|---|---|
host_is_superhost | One-Hot Encoding (drop_first=True) |
neighbourhood_group_cleansed | Label Encoding |
property_type | Label Encoding |
LabelEncoder객체는 추후 복호화를 위해 딕셔너리 형태로 저장.
💡 느낀 점
- 이상치 제거는 시각화와 수치 기준(IQR)을 함께 고려해야 신뢰도가 높다.
- 결측치 제거는 단순
dropna()보다, 제거 기준이 되는 컬럼을 명확히 하는 것이 중요. - Label Encoding 결과값은 숫자지만 본래 의미가 있으므로 변환 매핑 정보를 반드시 저장해두어야 한다.
- 정규화와 인코딩을 통해 모델 학습 전 데이터를 보다 깔끔하게 준비할 수 있었다.
